 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJolia: Concept-Level Vision-Language Alignment for 3D CT Contrastive Learning
Jun 24, 2026Vision-language contrastive pretraining has become the dominant recipe for 3D medical foundation models, leveraging the large volumes of paired scans and reports produced in clinical practice. However, medical images usually span dozens of organs, and radiological reports are much longer than typical natural image captions and are composed of multiple structured sections. CLIP-style pretraining compresses this structure by encoding each modality into a single global token, at the risk of losing important details. We introduce ConQuer (Concept Queries), an image-text pretraining method that augments CLIP's global alignment with a set of localized alignments, one per concept. ConQuer splits the report into concept-specific sections and learns cross-attention queries that pool the matching image features without using any segmentation mask or spatial supervision. Contrastive learning is then applied independently for each concept. Concepts can be any unit of semantic localization; here, they are anatomical regions, one query per organ or gross body region. As a byproduct, each query learns attention maps focused on its concept, providing built-in spatial interpretability. We use ConQuer to train Jolia, a 3D CT foundation model on chest and abdominal CT. Jolia consistently outperforms a CLIP baseline on findings classification, report generation, and cross-center transfer, and sets a new state of the art across multiple public benchmarks. Jolia's weights are available at https://huggingface.co/raidium/Jolia
Towards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
Apr 13, 2026Clinical deployment of automated brain MRI analysis faces a fundamental challenge: clinical data is heterogeneous and noisy, and high-quality labels are prohibitively costly to obtain. Self-supervised learning (SSL) can address this by leveraging the vast amounts of unlabeled data produced in clinical workflows to train robust \textit{foundation models} that adapt out-of-domain with minimal supervision. However, the development of foundation models for brain MRI has been limited by small pretraining datasets and in-domain benchmarking focused on high-quality, research-grade data. To address this gap, we organized the FOMO25 challenge as a satellite event at MICCAI 2025. FOMO25 provided participants with a large pretraining dataset, FOMO60K, and evaluated models on data sourced directly from clinical workflows in few-shot and out-of-domain settings. Tasks covered infarct classification, meningioma segmentation, and brain age regression, and considered both models trained on FOMO60K (method track) and any data (open track). Nineteen foundation models from sixteen teams were evaluated using a standardized containerized pipeline. Results show that (a) self-supervised pretraining improves generalization on clinical data under domain shift, with the strongest models trained \textit{out-of-domain} surpassing supervised baselines trained \textit{in-domain}. (b) No single pretraining objective benefits all tasks: MAE favors segmentation, hybrid reconstruction-contrastive objectives favor classification, and (c) strong performance was achieved by small pretrained models, and improvements from scaling model size and training duration did not yield reliable benefits.
Curia-2: Scaling Self-Supervised Learning for Radiology Foundation Models
Apr 02, 2026The rapid growth of medical imaging has fueled the development of Foundation Models (FMs) to reduce the growing, unsustainable workload on radiologists. While recent FMs have shown the power of large-scale pre-training to CT and MRI analysis, there remains significant room to optimize how these models learn from complex radiological volumes. Building upon the Curia framework, this work introduces Curia-2, which significantly improves the original pre-training strategy and representation quality to better capture the specificities of radiological data. The proposed methodology enables scaling the architecture up to billion-parameter Vision Transformers, marking a first for multi-modal CT and MRI FMs. Furthermore, we formalize the evaluation of these models by extending and restructuring CuriaBench into two distinct tracks: a 2D track tailored for slice-based vision models and a 3D track for volumetric benchmarking. Our results demonstrate that Curia-2 outperforms all FMs on vision-focused tasks and fairs competitively to vision-language models on clinically complex tasks such as finding detection. Weights will be made publicly available to foster further research.
RadImageNet-VQA: A Large-Scale CT and MRI Dataset for Radiologic Visual Question Answering
Dec 19, 2025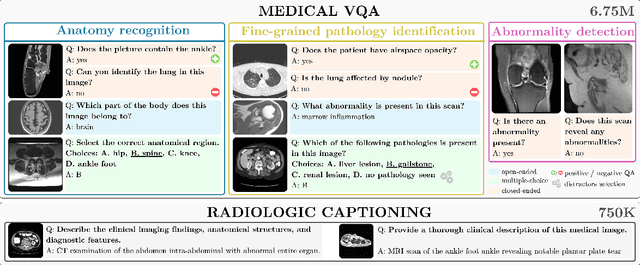

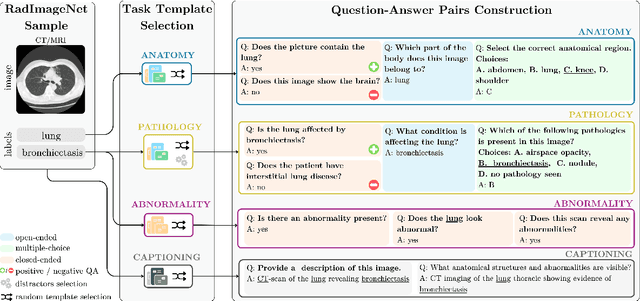
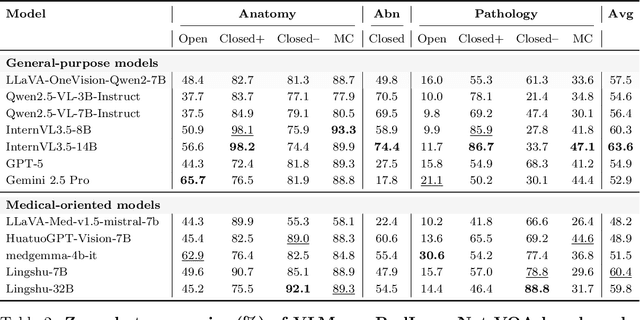
In this work, we introduce RadImageNet-VQA, a large-scale dataset designed to advance radiologic visual question answering (VQA) on CT and MRI exams. Existing medical VQA datasets are limited in scale, dominated by X-ray imaging or biomedical illustrations, and often prone to text-based shortcuts. RadImageNet-VQA is built from expert-curated annotations and provides 750K images paired with 7.5M question-answer samples. It covers three key tasks - abnormality detection, anatomy recognition, and pathology identification - spanning eight anatomical regions and 97 pathology categories, and supports open-ended, closed-ended, and multiple-choice questions. Extensive experiments show that state-of-the-art vision-language models still struggle with fine-grained pathology identification, particularly in open-ended settings and even after fine-tuning. Text-only analysis further reveals that model performance collapses to near-random without image inputs, confirming that RadImageNet-VQA is free from linguistic shortcuts. The full dataset and benchmark are publicly available at https://huggingface.co/datasets/raidium/RadImageNet-VQA.
RAPS-3D: Efficient interactive segmentation for 3D radiological imaging
Jul 10, 2025

Promptable segmentation, introduced by the Segment Anything Model (SAM), is a promising approach for medical imaging, as it enables clinicians to guide and refine model predictions interactively. However, SAM's architecture is designed for 2D images and does not extend naturally to 3D volumetric data such as CT or MRI scans. Adapting 2D models to 3D typically involves autoregressive strategies, where predictions are propagated slice by slice, resulting in increased inference complexity. Processing large 3D volumes also requires significant computational resources, often leading existing 3D methods to also adopt complex strategies like sliding-window inference to manage memory usage, at the cost of longer inference times and greater implementation complexity. In this paper, we present a simplified 3D promptable segmentation method, inspired by SegVol, designed to reduce inference time and eliminate prompt management complexities associated with sliding windows while achieving state-of-the-art performance.
RadSAM: Segmenting 3D radiological images with a 2D promptable model
Apr 29, 2025



Medical image segmentation is a crucial and time-consuming task in clinical care, where mask precision is extremely important. The Segment Anything Model (SAM) offers a promising approach, as it provides an interactive interface based on visual prompting and edition to refine an initial segmentation. This model has strong generalization capabilities, does not rely on predefined classes, and adapts to diverse objects; however, it is pre-trained on natural images and lacks the ability to process medical data effectively. In addition, this model is built for 2D images, whereas a whole medical domain is based on 3D images, such as CT and MRI. Recent adaptations of SAM for medical imaging are based on 2D models, thus requiring one prompt per slice to segment 3D objects, making the segmentation process tedious. They also lack important features such as editing. To bridge this gap, we propose RadSAM, a novel method for segmenting 3D objects with a 2D model from a single prompt. In practice, we train a 2D model using noisy masks as initial prompts, in addition to bounding boxes and points. We then use this novel prompt type with an iterative inference pipeline to reconstruct the 3D mask slice-by-slice. We introduce a benchmark to evaluate the model's ability to segment 3D objects in CT images from a single prompt and evaluate the models' out-of-domain transfer and edition capabilities. We demonstrate the effectiveness of our approach against state-of-the-art models on this benchmark using the AMOS abdominal organ segmentation dataset.
ONCOPILOT: A Promptable CT Foundation Model For Solid Tumor Evaluation
Oct 10, 2024



Carcinogenesis is a proteiform phenomenon, with tumors emerging in various locations and displaying complex, diverse shapes. At the crucial intersection of research and clinical practice, it demands precise and flexible assessment. However, current biomarkers, such as RECIST 1.1's long and short axis measurements, fall short of capturing this complexity, offering an approximate estimate of tumor burden and a simplistic representation of a more intricate process. Additionally, existing supervised AI models face challenges in addressing the variability in tumor presentations, limiting their clinical utility. These limitations arise from the scarcity of annotations and the models' focus on narrowly defined tasks. To address these challenges, we developed ONCOPILOT, an interactive radiological foundation model trained on approximately 7,500 CT scans covering the whole body, from both normal anatomy and a wide range of oncological cases. ONCOPILOT performs 3D tumor segmentation using visual prompts like point-click and bounding boxes, outperforming state-of-the-art models (e.g., nnUnet) and achieving radiologist-level accuracy in RECIST 1.1 measurements. The key advantage of this foundation model is its ability to surpass state-of-the-art performance while keeping the radiologist in the loop, a capability that previous models could not achieve. When radiologists interactively refine the segmentations, accuracy improves further. ONCOPILOT also accelerates measurement processes and reduces inter-reader variability, facilitating volumetric analysis and unlocking new biomarkers for deeper insights. This AI assistant is expected to enhance the precision of RECIST 1.1 measurements, unlock the potential of volumetric biomarkers, and improve patient stratification and clinical care, while seamlessly integrating into the radiological workflow.
Efficient Medical Question Answering with Knowledge-Augmented Question Generation
May 23, 2024In the expanding field of language model applications, medical knowledge representation remains a significant challenge due to the specialized nature of the domain. Large language models, such as GPT-4, obtain reasonable scores on medical question answering tasks, but smaller models are far behind. In this work, we introduce a method to improve the proficiency of a small language model in the medical domain by employing a two-fold approach. We first fine-tune the model on a corpus of medical textbooks. Then, we use GPT-4 to generate questions similar to the downstream task, prompted with textbook knowledge, and use them to fine-tune the model. Additionally, we introduce ECN-QA, a novel medical question answering dataset containing ``progressive questions'' composed of related sequential questions. We show the benefits of our training strategy on this dataset. The study's findings highlight the potential of small language models in the medical domain when appropriately fine-tuned. The code and weights are available at https://github.com/raidium-med/MQG.
Beyond Task Performance: Evaluating and Reducing the Flaws of Large Multimodal Models with In-Context Learning
Oct 01, 2023Following the success of Large Language Models (LLMs), Large Multimodal Models (LMMs), such as the Flamingo model and its subsequent competitors, have started to emerge as natural steps towards generalist agents. However, interacting with recent LMMs reveals major limitations that are hardly captured by the current evaluation benchmarks. Indeed, task performances (e.g., VQA accuracy) alone do not provide enough clues to understand their real capabilities, limitations, and to which extent such models are aligned to human expectations. To refine our understanding of those flaws, we deviate from the current evaluation paradigm and propose the EvALign-ICL framework, in which we (1) evaluate 8 recent open-source LMMs (based on the Flamingo architecture such as OpenFlamingo and IDEFICS) on 5 different axes; hallucinations, abstention, compositionality, explainability and instruction following. Our evaluation on these axes reveals major flaws in LMMs. To efficiently address these problems, and inspired by the success of in-context learning (ICL) in LLMs, (2) we explore ICL as a solution and study how it affects these limitations. Based on our ICL study, (3) we push ICL further and propose new multimodal ICL approaches such as; Multitask-ICL, Chain-of-Hindsight-ICL, and Self-Correcting-ICL. Our findings are as follows; (1) Despite their success, LMMs have flaws that remain unsolved with scaling alone. (2) The effect of ICL on LMMs flaws is nuanced; despite its effectiveness for improved explainability, abstention, and instruction following, ICL does not improve compositional abilities, and actually even amplifies hallucinations. (3) The proposed ICL variants are promising as post-hoc approaches to efficiently tackle some of those flaws. The code is available here: https://evalign-icl.github.io/
Unified Model for Image, Video, Audio and Language Tasks
Jul 30, 2023Large Language Models (LLMs) have made the ambitious quest for generalist agents significantly far from being a fantasy. A key hurdle for building such general models is the diversity and heterogeneity of tasks and modalities. A promising solution is unification, allowing the support of a myriad of tasks and modalities within one unified framework. While few large models (e.g., Flamingo (Alayrac et al., 2022), trained on massive datasets, can support more than two modalities, current small to mid-scale unified models are still limited to 2 modalities, usually image-text or video-text. The question that we ask is: is it possible to build efficiently a unified model that can support all modalities? To answer this, we propose UnIVAL, a step further towards this ambitious goal. Without relying on fancy datasets sizes or models with billions of parameters, the ~ 0.25B parameter UnIVAL model goes beyond two modalities and unifies text, images, video, and audio into a single model. Our model is efficiently pretrained on many tasks, based on task balancing and multimodal curriculum learning. UnIVAL shows competitive performance to existing state-of-the-art approaches, across image and video-text tasks. The feature representations learned from image and video-text modalities, allows the model to achieve competitive performance when finetuned on audio-text tasks, despite not being pretrained on audio. Thanks to the unified model, we propose a novel study on multimodal model merging via weight interpolation of models trained on different multimodal tasks, showing their benefits in particular for out-of-distribution generalization. Finally, we motivate unification by showing the synergy between tasks. The model weights and code are released here: https://github.com/mshukor/UnIVAL.