 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAL: Self-supervised Embodied Active Learning using Exploration and 3D Consistency
Dec 02, 2021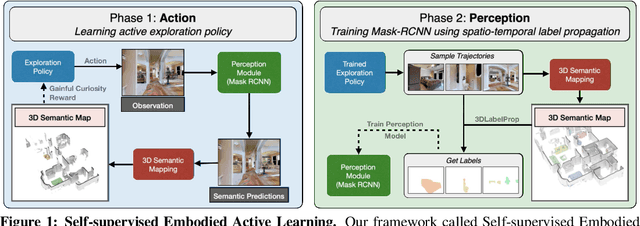
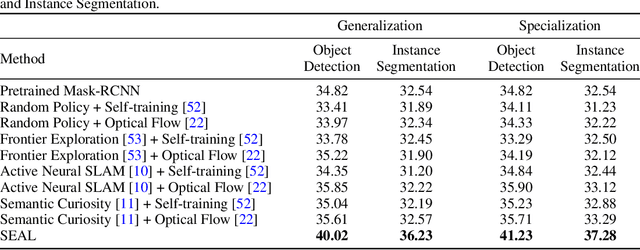
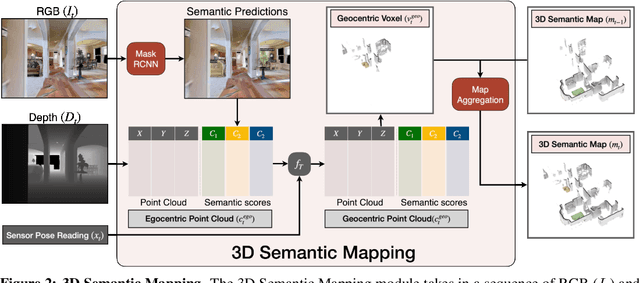

In this paper, we explore how we can build upon the data and models of Internet images and use them to adapt to robot vision without requiring any extra labels. We present a framework called Self-supervised Embodied Active Learning (SEAL). It utilizes perception models trained on internet images to learn an active exploration policy. The observations gathered by this exploration policy are labelled using 3D consistency and used to improve the perception model. We build and utilize 3D semantic maps to learn both action and perception in a completely self-supervised manner. The semantic map is used to compute an intrinsic motivation reward for training the exploration policy and for labelling the agent observations using spatio-temporal 3D consistency and label propagation. We demonstrate that the SEAL framework can be used to close the action-perception loop: it improves object detection and instance segmentation performance of a pretrained perception model by just moving around in training environments and the improved perception model can be used to improve Object Goal Navigation.
FILM: Following Instructions in Language with Modular Methods
Oct 18, 2021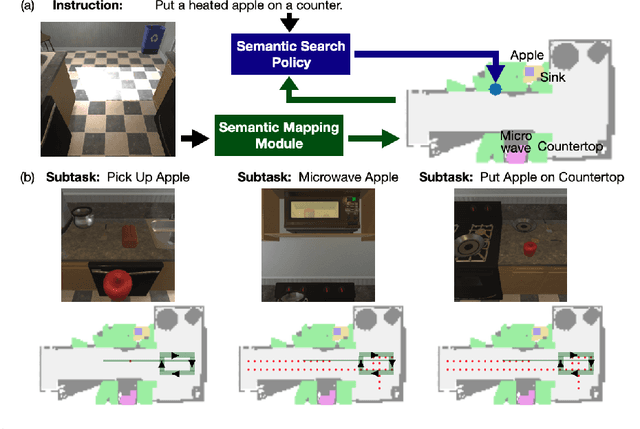
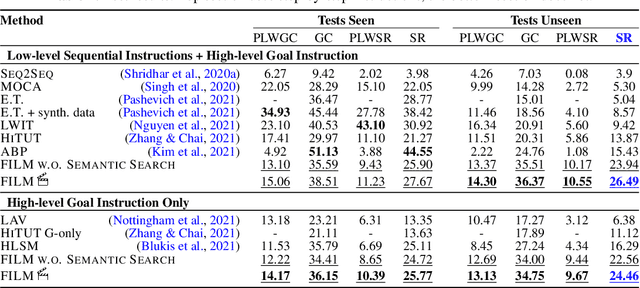
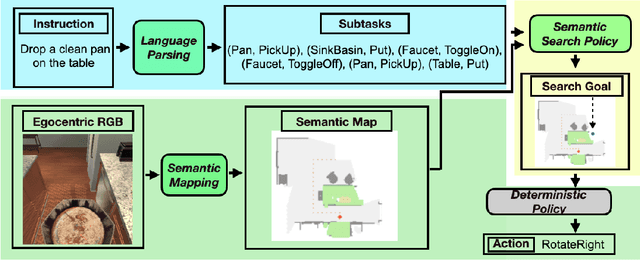
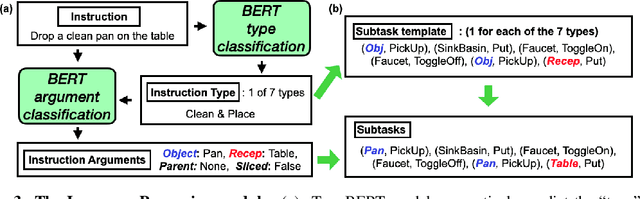
Recent methods for embodied instruction following are typically trained end-to-end using imitation learning. This requires the use of expert trajectories and low-level language instructions. Such approaches assume learned hidden states will simultaneously integrate semantics from the language and vision to perform state tracking, spatial memory, exploration, and long-term planning. In contrast, we propose a modular method with structured representations that (1) builds a semantic map of the scene, and (2) performs exploration with a semantic search policy, to achieve the natural language goal. Our modular method achieves SOTA performance (24.46%) with a substantial (8.17 % absolute) gap from previous work while using less data by eschewing both expert trajectories and low-level instructions. Leveraging low-level language, however, can further increase our performance (26.49%). Our findings suggest that an explicit spatial memory and a semantic search policy can provide a stronger and more general representation for state-tracking and guidance, even in the absence of expert trajectories or low-level instructions.
Building Intelligent Autonomous Navigation Agents
Jun 25, 2021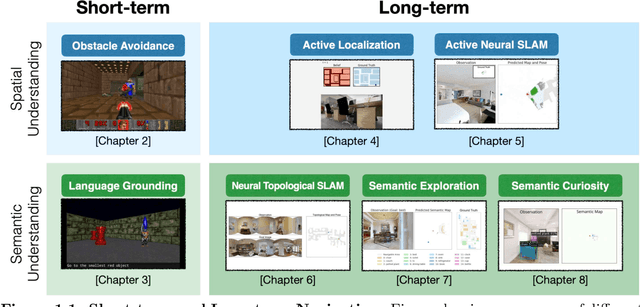
Breakthroughs in machine learning in the last decade have led to `digital intelligence', i.e. machine learning models capable of learning from vast amounts of labeled data to perform several digital tasks such as speech recognition, face recognition, machine translation and so on. The goal of this thesis is to make progress towards designing algorithms capable of `physical intelligence', i.e. building intelligent autonomous navigation agents capable of learning to perform complex navigation tasks in the physical world involving visual perception, natural language understanding, reasoning, planning, and sequential decision making. Despite several advances in classical navigation methods in the last few decades, current navigation agents struggle at long-term semantic navigation tasks. In the first part of the thesis, we discuss our work on short-term navigation using end-to-end reinforcement learning to tackle challenges such as obstacle avoidance, semantic perception, language grounding, and reasoning. In the second part, we present a new class of navigation methods based on modular learning and structured explicit map representations, which leverage the strengths of both classical and end-to-end learning methods, to tackle long-term navigation tasks. We show that these methods are able to effectively tackle challenges such as localization, mapping, long-term planning, exploration and learning semantic priors. These modular learning methods are capable of long-term spatial and semantic understanding and achieve state-of-the-art results on various navigation tasks.
Unsupervised Domain Adaptation for Visual Navigation
Nov 12, 2020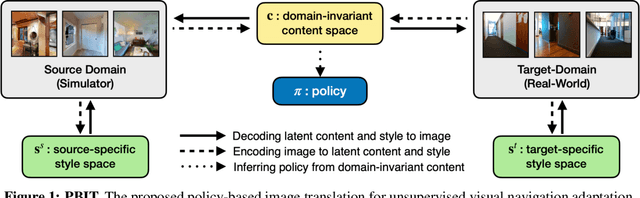
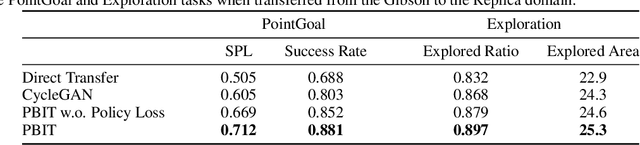

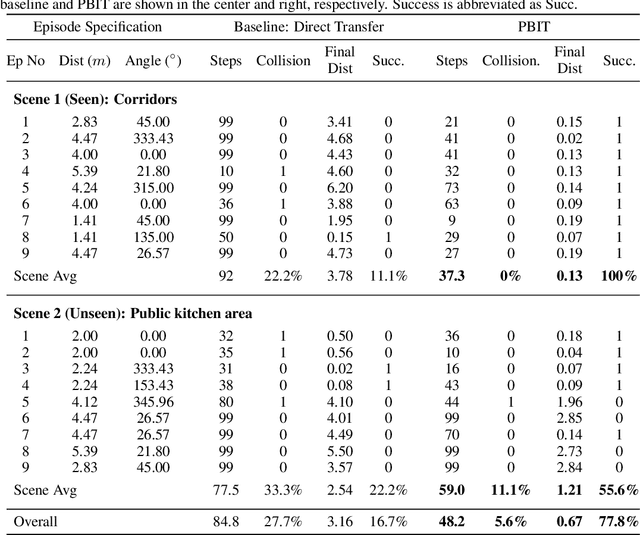
Advances in visual navigation methods have led to intelligent embodied navigation agents capable of learning meaningful representations from raw RGB images and perform a wide variety of tasks involving structural and semantic reasoning. However, most learning-based navigation policies are trained and tested in simulation environments. In order for these policies to be practically useful, they need to be transferred to the real-world. In this paper, we propose an unsupervised domain adaptation method for visual navigation. Our method translates the images in the target domain to the source domain such that the translation is consistent with the representations learned by the navigation policy. The proposed method outperforms several baselines across two different navigation tasks in simulation. We further show that our method can be used to transfer the navigation policies learned in simulation to the real world.
Planning with Submodular Objective Functions
Oct 22, 2020
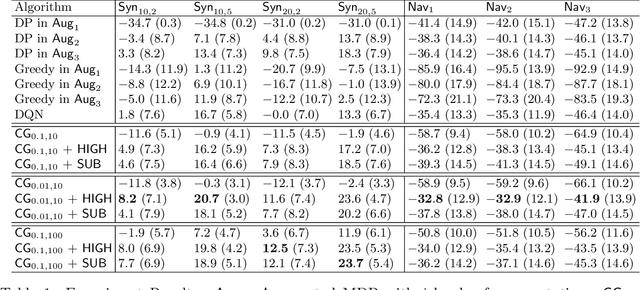

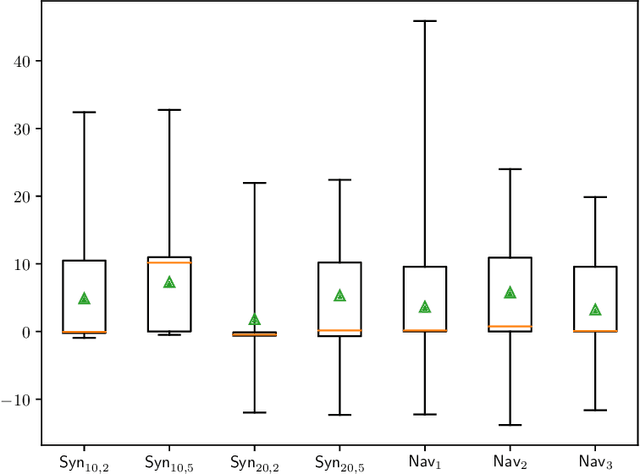
We study planning with submodular objective functions, where instead of maximizing the cumulative reward, the goal is to maximize the objective value induced by a submodular function. Our framework subsumes standard planning and submodular maximization with cardinality constraints as special cases, and thus many practical applications can be naturally formulated within our framework. Based on the notion of multilinear extension, we propose a novel and theoretically principled algorithmic framework for planning with submodular objective functions, which recovers classical algorithms when applied to the two special cases mentioned above. Empirically, our approach significantly outperforms baseline algorithms on synthetic environments and navigation tasks.
Object Goal Navigation using Goal-Oriented Semantic Exploration
Jul 02, 2020
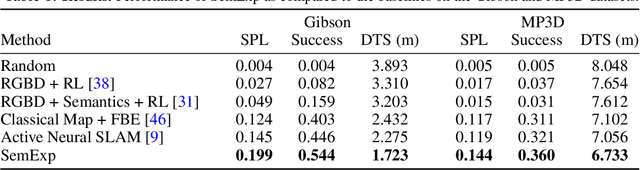
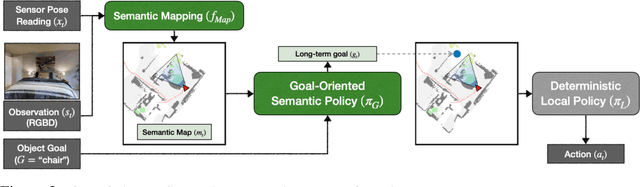

This work studies the problem of object goal navigation which involves navigating to an instance of the given object category in unseen environments. End-to-end learning-based navigation methods struggle at this task as they are ineffective at exploration and long-term planning. We propose a modular system called, `Goal-Oriented Semantic Exploration' which builds an episodic semantic map and uses it to explore the environment efficiently based on the goal object category. Empirical results in visually realistic simulation environments show that the proposed model outperforms a wide range of baselines including end-to-end learning-based methods as well as modular map-based methods and led to the winning entry of the CVPR-2020 Habitat ObjectNav Challenge. Ablation analysis indicates that the proposed model learns semantic priors of the relative arrangement of objects in a scene, and uses them to explore efficiently. Domain-agnostic module design allow us to transfer our model to a mobile robot platform and achieve similar performance for object goal navigation in the real-world.
Semantic Curiosity for Active Visual Learning
Jun 16, 2020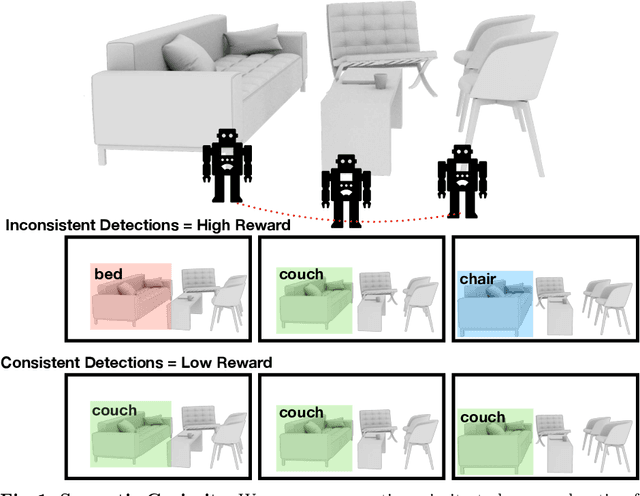

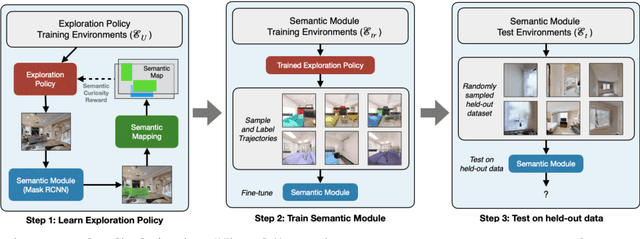
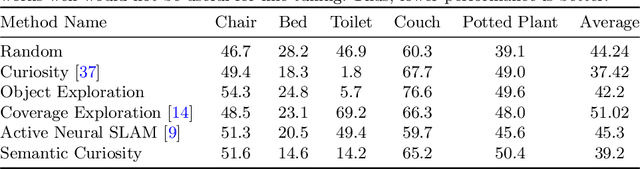
In this paper, we study the task of embodied interactive learning for object detection. Given a set of environments (and some labeling budget), our goal is to learn an object detector by having an agent select what data to obtain labels for. How should an exploration policy decide which trajectory should be labeled? One possibility is to use a trained object detector's failure cases as an external reward. However, this will require labeling millions of frames required for training RL policies, which is infeasible. Instead, we explore a self-supervised approach for training our exploration policy by introducing a notion of semantic curiosity. Our semantic curiosity policy is based on a simple observation -- the detection outputs should be consistent. Therefore, our semantic curiosity rewards trajectories with inconsistent labeling behavior and encourages the exploration policy to explore such areas. The exploration policy trained via semantic curiosity generalizes to novel scenes and helps train an object detector that outperforms baselines trained with other possible alternatives such as random exploration, prediction-error curiosity, and coverage-maximizing exploration.
Neural Topological SLAM for Visual Navigation
May 28, 2020
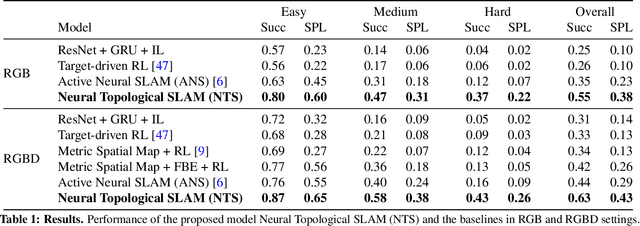

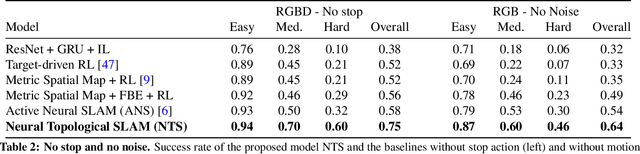
This paper studies the problem of image-goal navigation which involves navigating to the location indicated by a goal image in a novel previously unseen environment. To tackle this problem, we design topological representations for space that effectively leverage semantics and afford approximate geometric reasoning. At the heart of our representations are nodes with associated semantic features, that are interconnected using coarse geometric information. We describe supervised learning-based algorithms that can build, maintain and use such representations under noisy actuation. Experimental study in visually and physically realistic simulation suggests that our method builds effective representations that capture structural regularities and efficiently solve long-horizon navigation problems. We observe a relative improvement of more than 50% over existing methods that study this task.
Learning to Explore using Active Neural SLAM
Apr 10, 2020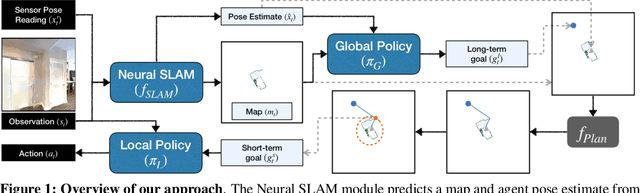
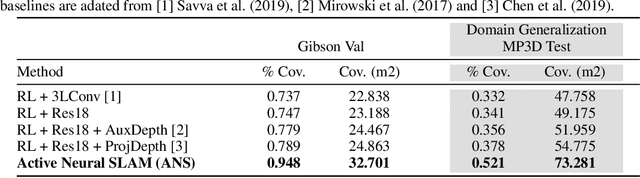
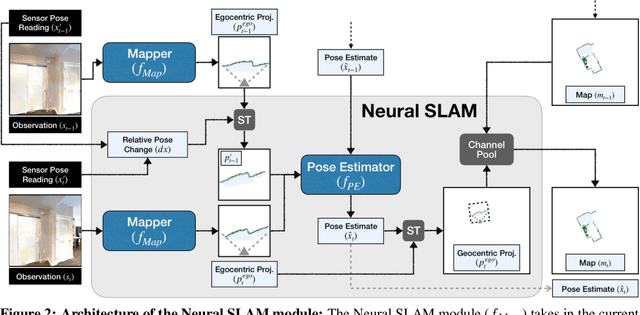
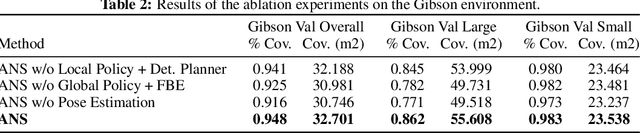
This work presents a modular and hierarchical approach to learn policies for exploring 3D environments, called `Active Neural SLAM'. Our approach leverages the strengths of both classical and learning-based methods, by using analytical path planners with learned SLAM module, and global and local policies. The use of learning provides flexibility with respect to input modalities (in the SLAM module), leverages structural regularities of the world (in global policies), and provides robustness to errors in state estimation (in local policies). Such use of learning within each module retains its benefits, while at the same time, hierarchical decomposition and modular training allow us to sidestep the high sample complexities associated with training end-to-end policies. Our experiments in visually and physically realistic simulated 3D environments demonstrate the effectiveness of our approach over past learning and geometry-based approaches. The proposed model can also be easily transferred to the PointGoal task and was the winning entry of the CVPR 2019 Habitat PointGoal Navigation Challenge.
Embodied Multimodal Multitask Learning
Feb 04, 2019

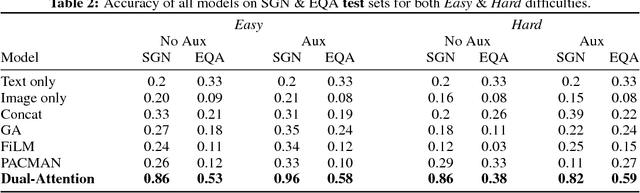
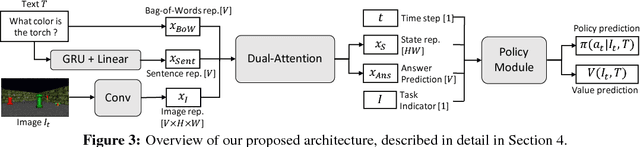
Recent efforts on training visual navigation agents conditioned on language using deep reinforcement learning have been successful in learning policies for different multimodal tasks, such as semantic goal navigation and embodied question answering. In this paper, we propose a multitask model capable of jointly learning these multimodal tasks, and transferring knowledge of words and their grounding in visual objects across the tasks. The proposed model uses a novel Dual-Attention unit to disentangle the knowledge of words in the textual representations and visual concepts in the visual representations, and align them with each other. This disentangled task-invariant alignment of representations facilitates grounding and knowledge transfer across both tasks. We show that the proposed model outperforms a range of baselines on both tasks in simulated 3D environments. We also show that this disentanglement of representations makes our model modular, interpretable, and allows for transfer to instructions containing new words by leveraging object detectors.