 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Visual Navigation
Nov 12, 2020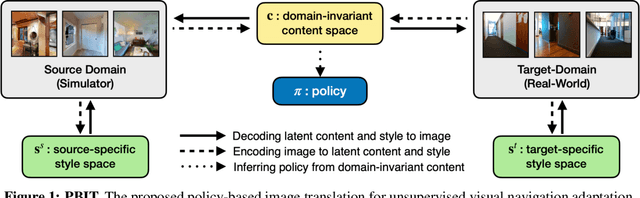
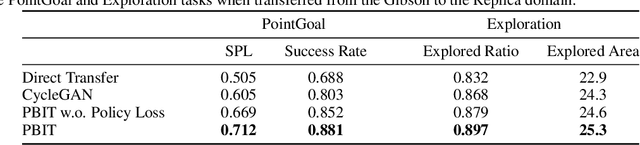

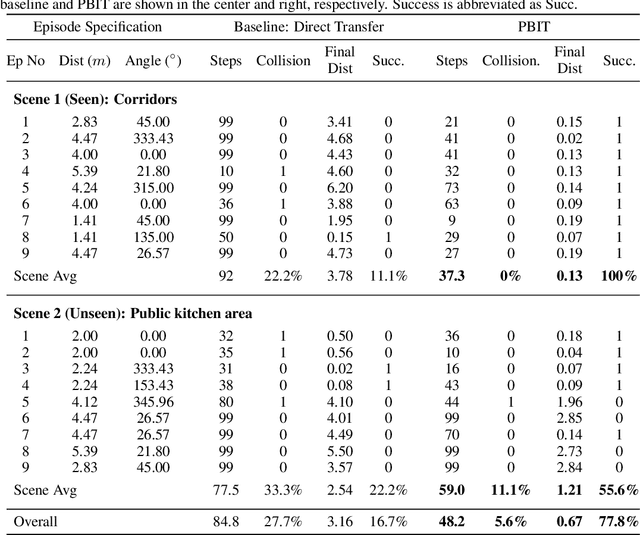
Advances in visual navigation methods have led to intelligent embodied navigation agents capable of learning meaningful representations from raw RGB images and perform a wide variety of tasks involving structural and semantic reasoning. However, most learning-based navigation policies are trained and tested in simulation environments. In order for these policies to be practically useful, they need to be transferred to the real-world. In this paper, we propose an unsupervised domain adaptation method for visual navigation. Our method translates the images in the target domain to the source domain such that the translation is consistent with the representations learned by the navigation policy. The proposed method outperforms several baselines across two different navigation tasks in simulation. We further show that our method can be used to transfer the navigation policies learned in simulation to the real world.
Distributional Advantage Actor-Critic
Jun 10, 2018



In traditional reinforcement learning, an agent maximizes the reward collected during its interaction with the environment by approximating the optimal policy through the estimation of value functions. Typically, given a state s and action a, the corresponding value is the expected discounted sum of rewards. The optimal action is then chosen to be the action a with the largest value estimated by value function. However, recent developments have shown both theoretical and experimental evidence of superior performance when value function is replaced with value distribution in context of deep Q learning [1]. In this paper, we develop a new algorithm that combines advantage actor-critic with value distribution estimated by quantile regression. We evaluated this new algorithm, termed Distributional Advantage Actor-Critic (DA2C or QR-A2C) on a variety of tasks, and observed it to achieve at least as good as baseline algorithms, and outperforming baseline in some tasks with smaller variance and increased stability.