 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrozen Policy Iteration: Computationally Efficient RL under Linear $Q^π$ Realizability for Deterministic Dynamics
Feb 28, 2026We study computationally and statistically efficient reinforcement learning under the linear $Q^π$ realizability assumption, where any policy's $Q$-function is linear in a given state-action feature representation. Prior methods in this setting are either computationally intractable, or require (local) access to a simulator. In this paper, we propose a computationally efficient online RL algorithm, named Frozen Policy Iteration, under the linear $Q^π$ realizability setting that works for Markov Decision Processes (MDPs) with stochastic initial states, stochastic rewards and deterministic transitions. Our algorithm achieves a regret bound of $\widetilde{O}(\sqrt{d^2H^6T})$, where $d$ is the dimensionality of the feature space, $H$ is the horizon length, and $T$ is the total number of episodes. Our regret bound is optimal for linear (contextual) bandits which is a special case of our setting with $H = 1$. Existing policy iteration algorithms under the same setting heavily rely on repeatedly sampling the same state by access to the simulator, which is not implementable in the online setting with stochastic initial states studied in this paper. In contrast, our new algorithm circumvents this limitation by strategically using only high-confidence part of the trajectory data and freezing the policy for well-explored states, which ensures that all data used by our algorithm remains effectively on-policy during the whole course of learning. We further demonstrate the versatility of our approach by extending it to the Uniform-PAC setting and to function classes with bounded eluder dimension.
Misspecified $Q$-Learning with Sparse Linear Function Approximation: Tight Bounds on Approximation Error
Jul 18, 2024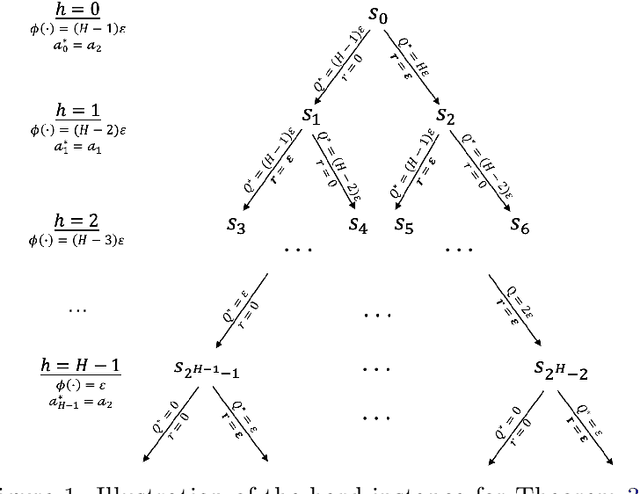
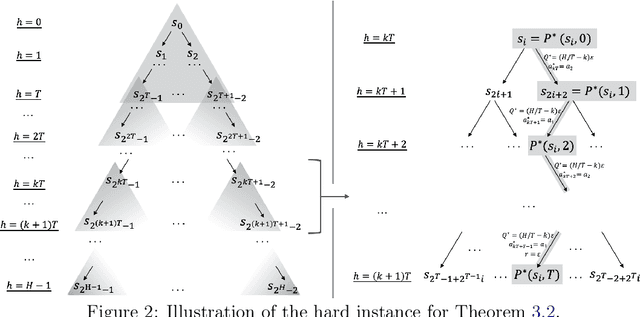
The recent work by Dong & Yang (2023) showed for misspecified sparse linear bandits, one can obtain an $O\left(\epsilon\right)$-optimal policy using a polynomial number of samples when the sparsity is a constant, where $\epsilon$ is the misspecification error. This result is in sharp contrast to misspecified linear bandits without sparsity, which require an exponential number of samples to get the same guarantee. In order to study whether the analog result is possible in the reinforcement learning setting, we consider the following problem: assuming the optimal $Q$-function is a $d$-dimensional linear function with sparsity $k$ and misspecification error $\epsilon$, whether we can obtain an $O\left(\epsilon\right)$-optimal policy using number of samples polynomially in the feature dimension $d$. We first demonstrate why the standard approach based on Bellman backup or the existing optimistic value function elimination approach such as OLIVE (Jiang et al., 2017) achieves suboptimal guarantees for this problem. We then design a novel elimination-based algorithm to show one can obtain an $O\left(H\epsilon\right)$-optimal policy with sample complexity polynomially in the feature dimension $d$ and planning horizon $H$. Lastly, we complement our upper bound with an $\widetilde{\Omega}\left(H\epsilon\right)$ suboptimality lower bound, giving a complete picture of this problem.
Provably Efficient Reinforcement Learning via Surprise Bound
Feb 22, 2023Value function approximation is important in modern reinforcement learning (RL) problems especially when the state space is (infinitely) large. Despite the importance and wide applicability of value function approximation, its theoretical understanding is still not as sophisticated as its empirical success, especially in the context of general function approximation. In this paper, we propose a provably efficient RL algorithm (both computationally and statistically) with general value function approximations. We show that if the value functions can be approximated by a function class that satisfies the Bellman-completeness assumption, our algorithm achieves an $\widetilde{O}(\text{poly}(\iota H)\sqrt{T})$ regret bound where $\iota$ is the product of the surprise bound and log-covering numbers, $H$ is the planning horizon, $K$ is the number of episodes and $T = HK$ is the total number of steps the agent interacts with the environment. Our algorithm achieves reasonable regret bounds when applied to both the linear setting and the sparse high-dimensional linear setting. Moreover, our algorithm only needs to solve $O(H\log K)$ empirical risk minimization (ERM) problems, which is far more efficient than previous algorithms that need to solve ERM problems for $\Omega(HK)$ times.
Variance-Aware Sparse Linear Bandits
May 26, 2022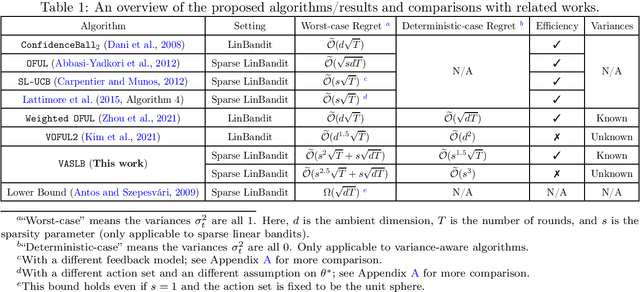
It is well-known that the worst-case minimax regret for sparse linear bandits is $\widetilde{\Theta}\left(\sqrt{dT}\right)$ where $d$ is the ambient dimension and $T$ is the number of time steps (ignoring the dependency on sparsity). On the other hand, in the benign setting where there is no noise and the action set is the unit sphere, one can use divide-and-conquer to achieve an $\widetilde{\mathcal O}(1)$ regret, which is (nearly) independent of $d$ and $T$. In this paper, we present the first variance-aware regret guarantee for sparse linear bandits: $\widetilde{\mathcal O}\left(\sqrt{d\sum_{t=1}^T \sigma_t^2} + 1\right)$, where $\sigma_t^2$ is the variance of the noise at the $t$-th time step. This bound naturally interpolates the regret bounds for the worst-case constant-variance regime ($\sigma_t = \Omega(1)$) and the benign deterministic regimes ($\sigma_t = 0$). To achieve this variance-aware regret guarantee, we develop a general framework that converts any variance-aware linear bandit algorithm to a variance-aware algorithm for sparse linear bandits in a ``black-box'' manner. Specifically, we take two recent algorithms as black boxes to illustrate that the claimed bounds indeed hold, where the first algorithm can handle unknown-variance cases and the second one is more efficient.
Settling the Horizon-Dependence of Sample Complexity in Reinforcement Learning
Nov 01, 2021Recently there is a surge of interest in understanding the horizon-dependence of the sample complexity in reinforcement learning (RL). Notably, for an RL environment with horizon length $H$, previous work have shown that there is a probably approximately correct (PAC) algorithm that learns an $O(1)$-optimal policy using $\mathrm{polylog}(H)$ episodes of environment interactions when the number of states and actions is fixed. It is yet unknown whether the $\mathrm{polylog}(H)$ dependence is necessary or not. In this work, we resolve this question by developing an algorithm that achieves the same PAC guarantee while using only $O(1)$ episodes of environment interactions, completely settling the horizon-dependence of the sample complexity in RL. We achieve this bound by (i) establishing a connection between value functions in discounted and finite-horizon Markov decision processes (MDPs) and (ii) a novel perturbation analysis in MDPs. We believe our new techniques are of independent interest and could be applied in related questions in RL.
Online Sub-Sampling for Reinforcement Learning with General Function Approximation
Jun 14, 2021Designing provably efficient algorithms with general function approximation is an important open problem in reinforcement learning. Recently, Wang et al.~[2020c] establish a value-based algorithm with general function approximation that enjoys $\widetilde{O}(\mathrm{poly}(dH)\sqrt{K})$\footnote{Throughout the paper, we use $\widetilde{O}(\cdot)$ to suppress logarithm factors. } regret bound, where $d$ depends on the complexity of the function class, $H$ is the planning horizon, and $K$ is the total number of episodes. However, their algorithm requires $\Omega(K)$ computation time per round, rendering the algorithm inefficient for practical use. In this paper, by applying online sub-sampling techniques, we develop an algorithm that takes $\widetilde{O}(\mathrm{poly}(dH))$ computation time per round on average, and enjoys nearly the same regret bound. Furthermore, the algorithm achieves low switching cost, i.e., it changes the policy only $\widetilde{O}(\mathrm{poly}(dH))$ times during its execution, making it appealing to be implemented in real-life scenarios. Moreover, by using an upper-confidence based exploration-driven reward function, the algorithm provably explores the environment in the reward-free setting. In particular, after $\widetilde{O}(\mathrm{poly}(dH))/\epsilon^2$ rounds of exploration, the algorithm outputs an $\epsilon$-optimal policy for any given reward function.
An Exponential Lower Bound for Linearly-Realizable MDPs with Constant Suboptimality Gap
Mar 23, 2021
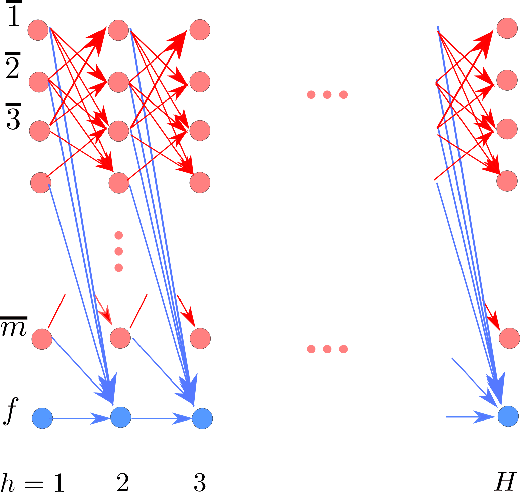
A fundamental question in the theory of reinforcement learning is: suppose the optimal $Q$-function lies in the linear span of a given $d$ dimensional feature mapping, is sample-efficient reinforcement learning (RL) possible? The recent and remarkable result of Weisz et al. (2020) resolved this question in the negative, providing an exponential (in $d$) sample size lower bound, which holds even if the agent has access to a generative model of the environment. One may hope that this information theoretic barrier for RL can be circumvented by further supposing an even more favorable assumption: there exists a \emph{constant suboptimality gap} between the optimal $Q$-value of the best action and that of the second-best action (for all states). The hope is that having a large suboptimality gap would permit easier identification of optimal actions themselves, thus making the problem tractable; indeed, provided the agent has access to a generative model, sample-efficient RL is in fact possible with the addition of this more favorable assumption. This work focuses on this question in the standard online reinforcement learning setting, where our main result resolves this question in the negative: our hardness result shows that an exponential sample complexity lower bound still holds even if a constant suboptimality gap is assumed in addition to having a linearly realizable optimal $Q$-function. Perhaps surprisingly, this implies an exponential separation between the online RL setting and the generative model setting. Complementing our negative hardness result, we give two positive results showing that provably sample-efficient RL is possible either under an additional low-variance assumption or under a novel hypercontractivity assumption (both implicitly place stronger conditions on the underlying dynamics model).
Bilinear Classes: A Structural Framework for Provable Generalization in RL
Mar 19, 2021
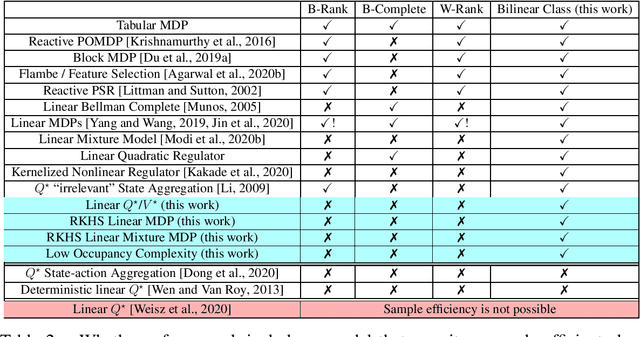
This work introduces Bilinear Classes, a new structural framework, which permit generalization in reinforcement learning in a wide variety of settings through the use of function approximation. The framework incorporates nearly all existing models in which a polynomial sample complexity is achievable, and, notably, also includes new models, such as the Linear $Q^*/V^*$ model in which both the optimal $Q$-function and the optimal $V$-function are linear in some known feature space. Our main result provides an RL algorithm which has polynomial sample complexity for Bilinear Classes; notably, this sample complexity is stated in terms of a reduction to the generalization error of an underlying supervised learning sub-problem. These bounds nearly match the best known sample complexity bounds for existing models. Furthermore, this framework also extends to the infinite dimensional (RKHS) setting: for the the Linear $Q^*/V^*$ model, linear MDPs, and linear mixture MDPs, we provide sample complexities that have no explicit dependence on the explicit feature dimension (which could be infinite), but instead depends only on information theoretic quantities.
Instabilities of Offline RL with Pre-Trained Neural Representation
Mar 08, 2021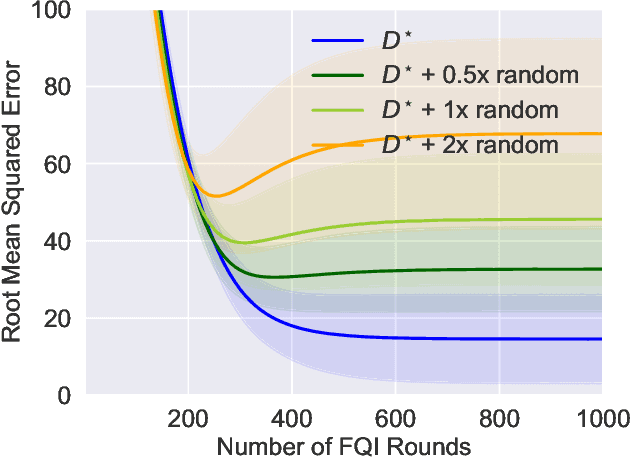

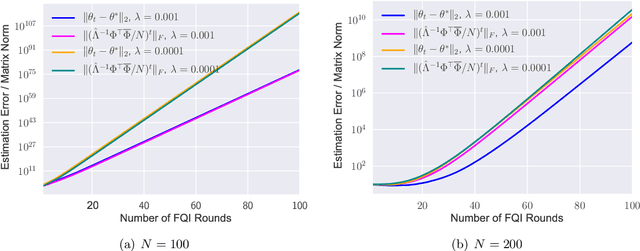

In offline reinforcement learning (RL), we seek to utilize offline data to evaluate (or learn) policies in scenarios where the data are collected from a distribution that substantially differs from that of the target policy to be evaluated. Recent theoretical advances have shown that such sample-efficient offline RL is indeed possible provided certain strong representational conditions hold, else there are lower bounds exhibiting exponential error amplification (in the problem horizon) unless the data collection distribution has only a mild distribution shift relative to the target policy. This work studies these issues from an empirical perspective to gauge how stable offline RL methods are. In particular, our methodology explores these ideas when using features from pre-trained neural networks, in the hope that these representations are powerful enough to permit sample efficient offline RL. Through extensive experiments on a range of tasks, we see that substantial error amplification does occur even when using such pre-trained representations (trained on the same task itself); we find offline RL is stable only under extremely mild distribution shift. The implications of these results, both from a theoretical and an empirical perspective, are that successful offline RL (where we seek to go beyond the low distribution shift regime) requires substantially stronger conditions beyond those which suffice for successful supervised learning.
What are the Statistical Limits of Offline RL with Linear Function Approximation?
Oct 22, 2020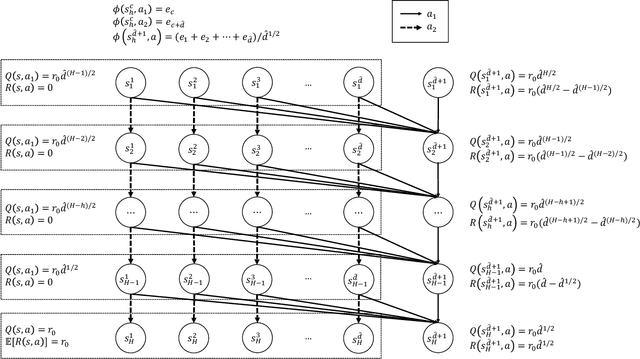
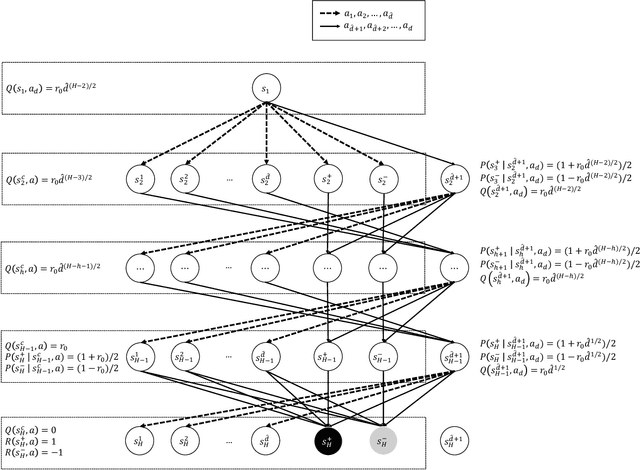
Offline reinforcement learning seeks to utilize offline (observational) data to guide the learning of (causal) sequential decision making strategies. The hope is that offline reinforcement learning coupled with function approximation methods (to deal with the curse of dimensionality) can provide a means to help alleviate the excessive sample complexity burden in modern sequential decision making problems. However, the extent to which this broader approach can be effective is not well understood, where the literature largely consists of sufficient conditions. This work focuses on the basic question of what are necessary representational and distributional conditions that permit provable sample-efficient offline reinforcement learning. Perhaps surprisingly, our main result shows that even if: i) we have realizability in that the true value function of \emph{every} policy is linear in a given set of features and 2) our off-policy data has good coverage over all features (under a strong spectral condition), then any algorithm still (information-theoretically) requires a number of offline samples that is exponential in the problem horizon in order to non-trivially estimate the value of \emph{any} given policy. Our results highlight that sample-efficient offline policy evaluation is simply not possible unless significantly stronger conditions hold; such conditions include either having low distribution shift (where the offline data distribution is close to the distribution of the policy to be evaluated) or significantly stronger representational conditions (beyond realizability).