 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecificity-preserving RGB-D Saliency Detection
Aug 18, 2021
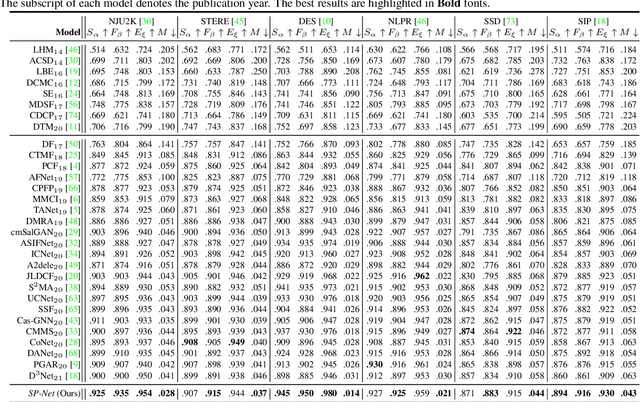
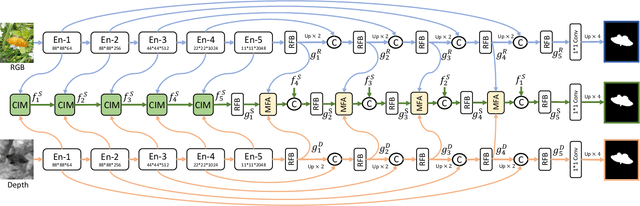
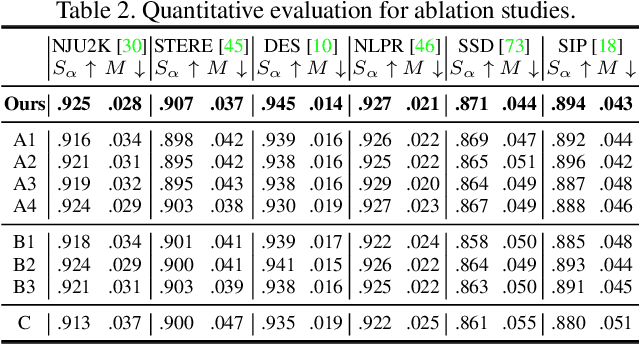
RGB-D saliency detection has attracted increasing attention, due to its effectiveness and the fact that depth cues can now be conveniently captured. Existing works often focus on learning a shared representation through various fusion strategies, with few methods explicitly considering how to preserve modality-specific characteristics. In this paper, taking a new perspective, we propose a specificity-preserving network (SP-Net) for RGB-D saliency detection, which benefits saliency detection performance by exploring both the shared information and modality-specific properties (e.g., specificity). Specifically, two modality-specific networks and a shared learning network are adopted to generate individual and shared saliency maps. A cross-enhanced integration module (CIM) is proposed to fuse cross-modal features in the shared learning network, which are then propagated to the next layer for integrating cross-level information. Besides, we propose a multi-modal feature aggregation (MFA) module to integrate the modality-specific features from each individual decoder into the shared decoder, which can provide rich complementary multi-modal information to boost the saliency detection performance. Further, a skip connection is used to combine hierarchical features between the encoder and decoder layers. Experiments on six benchmark datasets demonstrate that our SP-Net outperforms other state-of-the-art methods. Code is available at: https://github.com/taozh2017/SPNet.
Polyp-PVT: Polyp Segmentation with Pyramid Vision Transformers
Aug 16, 2021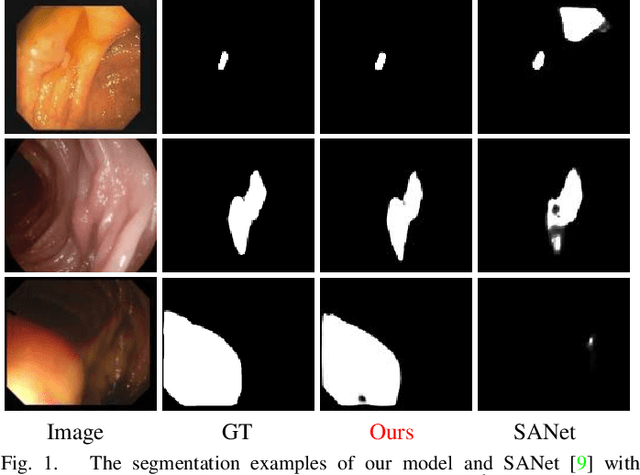
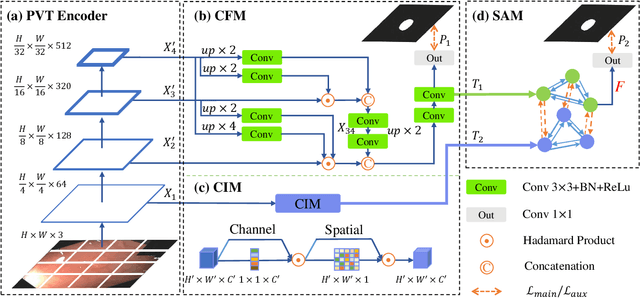
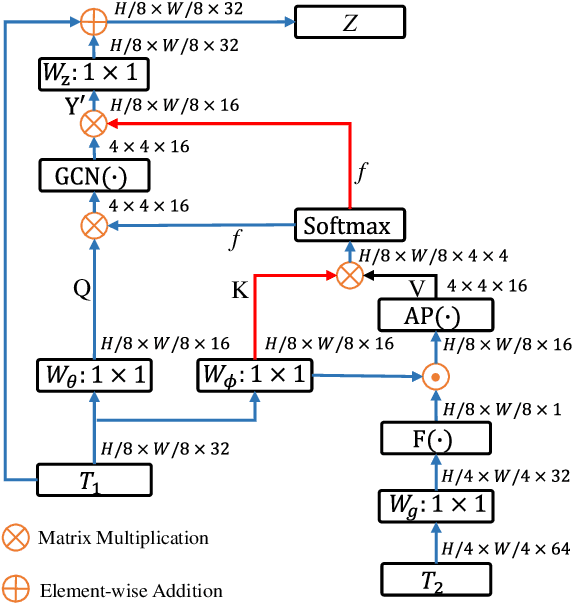
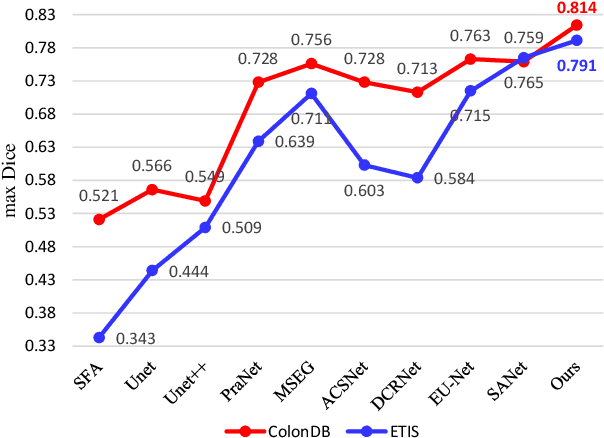
Most polyp segmentation methods use CNNs as their backbone, leading to two key issues when exchanging information between the encoder and decoder: 1) taking into account the differences in contribution between different-level features; and 2) designing effective mechanism for fusing these features. Different from existing CNN-based methods, we adopt a transformer encoder, which learns more powerful and robust representations. In addition, considering the image acquisition influence and elusive properties of polyps, we introduce three novel modules, including a cascaded fusion module (CFM), a camouflage identification module (CIM), a and similarity aggregation module (SAM). Among these, the CFM is used to collect the semantic and location information of polyps from high-level features, while the CIM is applied to capture polyp information disguised in low-level features. With the help of the SAM, we extend the pixel features of the polyp area with high-level semantic position information to the entire polyp area, thereby effectively fusing cross-level features. The proposed model, named \ourmodel, effectively suppresses noises in the features and significantly improves their expressive capabilities. Extensive experiments on five widely adopted datasets show that the proposed model is more robust to various challenging situations (e.g., appearance changes, small objects) than existing methods, and achieves the new state-of-the-art performance. The proposed model is available at https://github.com/DengPingFan/Polyp-PVT .
ASOD60K: Audio-Induced Salient Object Detection in Panoramic Videos
Jul 24, 2021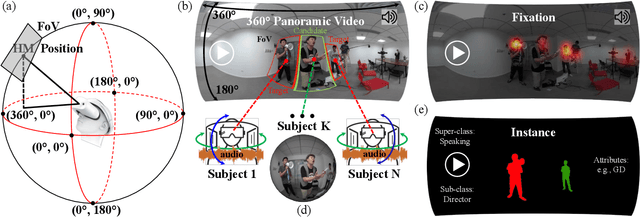

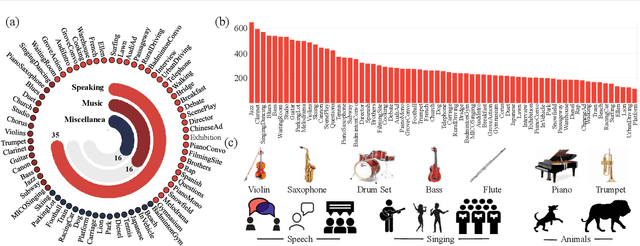
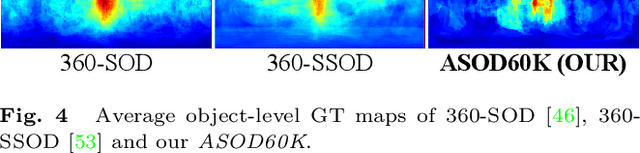
Exploring to what humans pay attention in dynamic panoramic scenes is useful for many fundamental applications, including augmented reality (AR) in retail, AR-powered recruitment, and visual language navigation. With this goal in mind, we propose PV-SOD, a new task that aims to segment salient objects from panoramic videos. In contrast to existing fixation-level or object-level saliency detection tasks, we focus on multi-modal salient object detection (SOD), which mimics human attention mechanism by segmenting salient objects with the guidance of audio-visual cues. To support this task, we collect the first large-scale dataset, named ASOD60K, which contains 4K-resolution video frames annotated with a six-level hierarchy, thus distinguishing itself with richness, diversity and quality. Specifically, each sequence is marked with both its super-/sub-class, with objects of each sub-class being further annotated with human eye fixations, bounding boxes, object-/instance-level masks, and associated attributes (e.g., geometrical distortion). These coarse-to-fine annotations enable detailed analysis for PV-SOD modeling, e.g., determining the major challenges for existing SOD models, and predicting scanpaths to study the long-term eye fixation behaviors of humans. We systematically benchmark 11 representative approaches on ASOD60K and derive several interesting findings. We hope this study could serve as a good starting point for advancing SOD research towards panoramic videos.
PVTv2: Improved Baselines with Pyramid Vision Transformer
Jul 17, 2021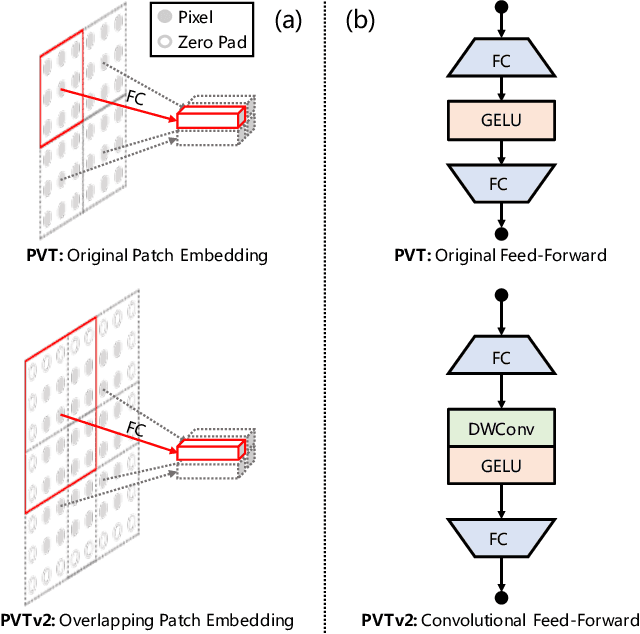
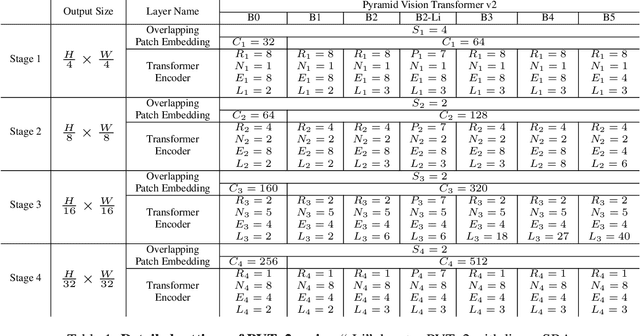
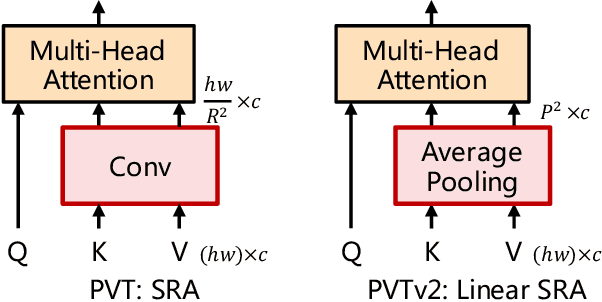
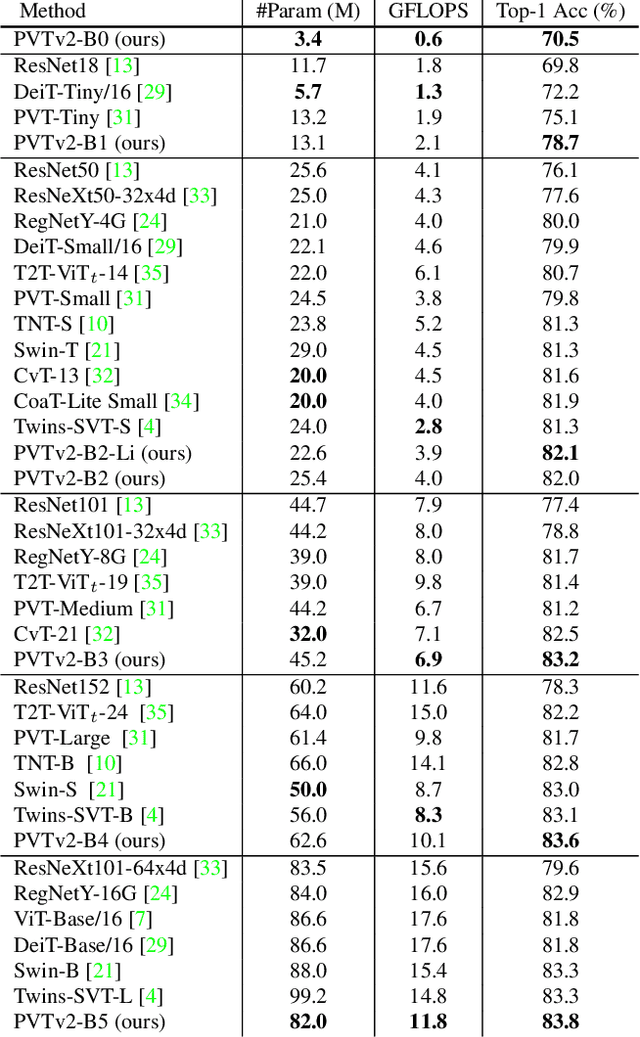
Transformer recently has shown encouraging progresses in computer vision. In this work, we present new baselines by improving the original Pyramid Vision Transformer (abbreviated as PVTv1) by adding three designs, including (1) overlapping patch embedding, (2) convolutional feed-forward networks, and (3) linear complexity attention layers. With these modifications, our PVTv2 significantly improves PVTv1 on three tasks e.g., classification, detection, and segmentation. Moreover, PVTv2 achieves comparable or better performances than recent works such as Swin Transformer. We hope this work will facilitate state-of-the-art Transformer researches in computer vision. Code is available at https://github.com/whai362/PVT .
Progressively Normalized Self-Attention Network for Video Polyp Segmentation
May 24, 2021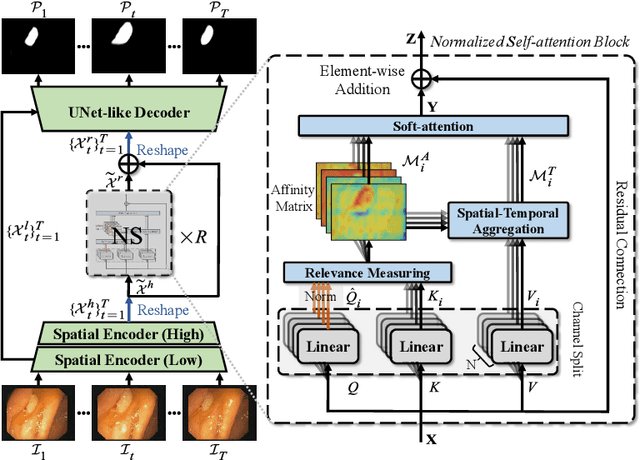
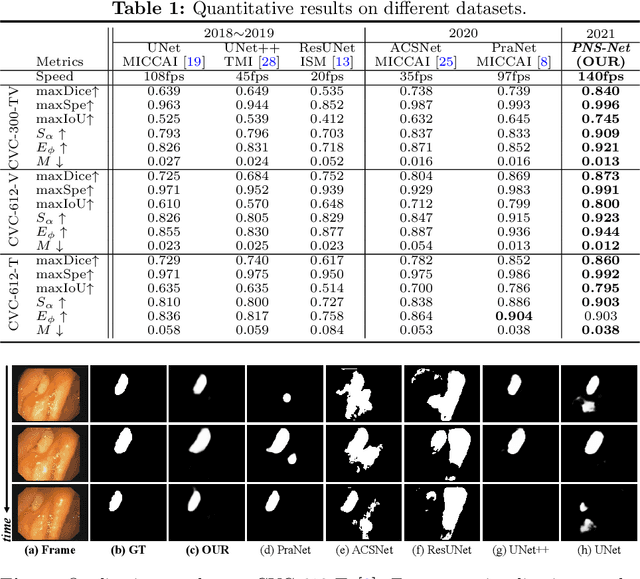
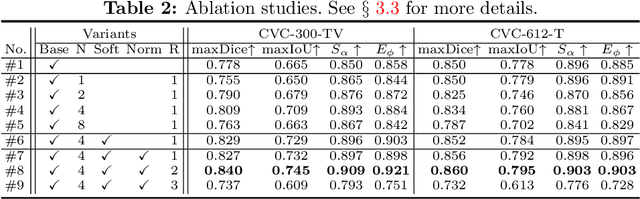
Existing video polyp segmentation (VPS) models typically employ convolutional neural networks (CNNs) to extract features. However, due to their limited receptive fields, CNNs can not fully exploit the global temporal and spatial information in successive video frames, resulting in false-positive segmentation results. In this paper, we propose the novel PNS-Net (Progressively Normalized Self-attention Network), which can efficiently learn representations from polyp videos with real-time speed (~140fps) on a single RTX 2080 GPU and no post-processing. Our PNS-Net is based solely on a basic normalized self-attention block, equipping with recurrence and CNNs entirely. Experiments on challenging VPS datasets demonstrate that the proposed PNS-Net achieves state-of-the-art performance. We also conduct extensive experiments to study the effectiveness of the channel split, soft-attention, and progressive learning strategy. We find that our PNS-Net works well under different settings, making it a promising solution to the VPS task.
Salient Objects in Clutter
May 07, 2021

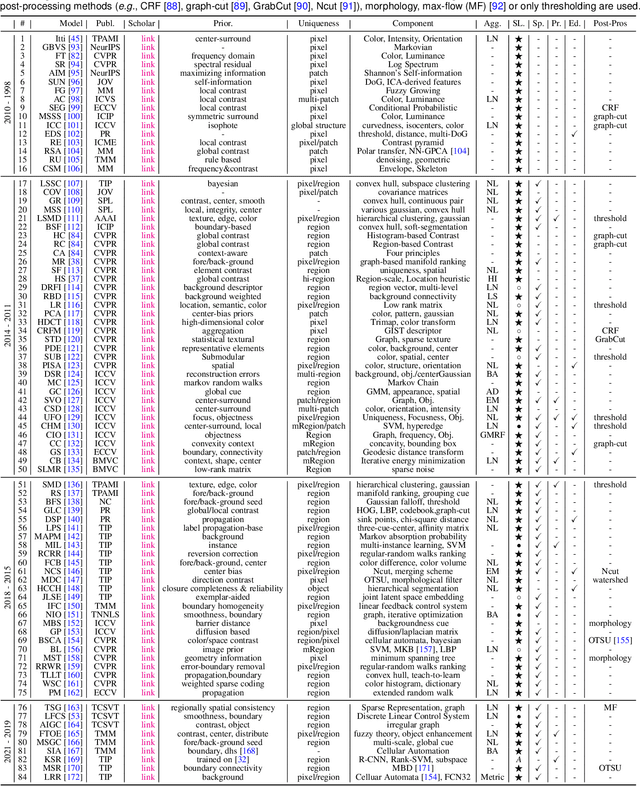
This paper identifies and addresses a serious design bias of existing salient object detection (SOD) datasets, which unrealistically assume that each image should contain at least one clear and uncluttered salient object. This design bias has led to a saturation in performance for state-of-the-art SOD models when evaluated on existing datasets. However, these models are still far from satisfactory when applied to real-world scenes. Based on our analyses, we propose a new high-quality dataset and update the previous saliency benchmark. Specifically, our dataset, called Salient Objects in Clutter (SOC), includes images with both salient and non-salient objects from several common object categories. In addition to object category annotations, each salient image is accompanied by attributes that reflect common challenges in real-world scenes, which can help provide deeper insight into the SOD problem. Further, with a given saliency encoder, e.g., the backbone network, existing saliency models are designed to achieve mapping from the training image set to the training ground-truth set. We, therefore, argue that improving the dataset can yield higher performance gains than focusing only on the decoder design. With this in mind, we investigate several dataset-enhancement strategies, including label smoothing to implicitly emphasize salient boundaries, random image augmentation to adapt saliency models to various scenarios, and self-supervised learning as a regularization strategy to learn from small datasets. Our extensive results demonstrate the effectiveness of these tricks. We also provide a comprehensive benchmark for SOD, which can be found in our repository: http://dpfan.net/SOCBenchmark.
Camouflaged Object Segmentation with Distraction Mining
Apr 21, 2021
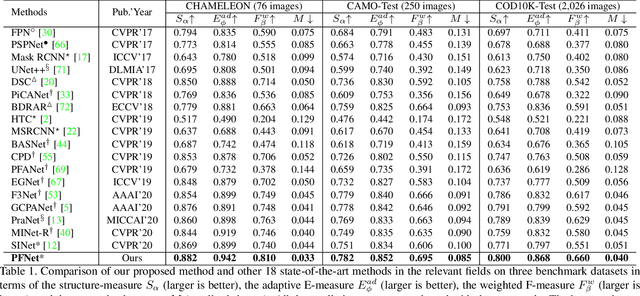
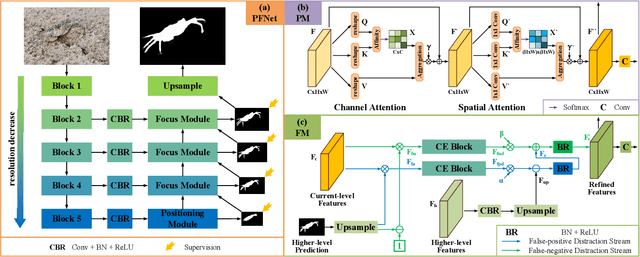
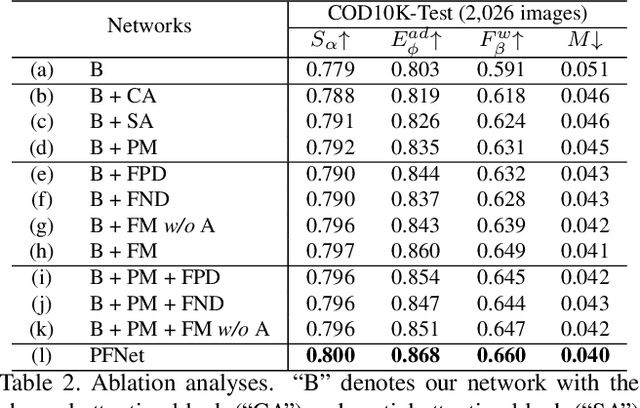
Camouflaged object segmentation (COS) aims to identify objects that are "perfectly" assimilate into their surroundings, which has a wide range of valuable applications. The key challenge of COS is that there exist high intrinsic similarities between the candidate objects and noise background. In this paper, we strive to embrace challenges towards effective and efficient COS. To this end, we develop a bio-inspired framework, termed Positioning and Focus Network (PFNet), which mimics the process of predation in nature. Specifically, our PFNet contains two key modules, i.e., the positioning module (PM) and the focus module (FM). The PM is designed to mimic the detection process in predation for positioning the potential target objects from a global perspective and the FM is then used to perform the identification process in predation for progressively refining the coarse prediction via focusing on the ambiguous regions. Notably, in the FM, we develop a novel distraction mining strategy for distraction discovery and removal, to benefit the performance of estimation. Extensive experiments demonstrate that our PFNet runs in real-time (72 FPS) and significantly outperforms 18 cutting-edge models on three challenging datasets under four standard metrics.
Transformer Transforms Salient Object Detection and Camouflaged Object Detection
Apr 20, 2021
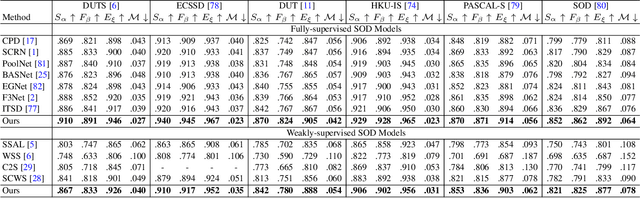
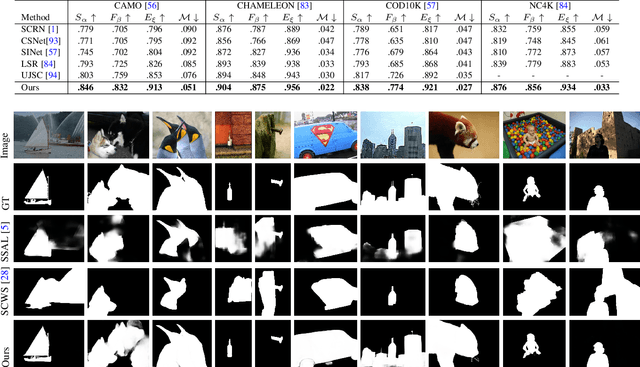
The transformer networks, which originate from machine translation, are particularly good at modeling long-range dependencies within a long sequence. Currently, the transformer networks are making revolutionary progress in various vision tasks ranging from high-level classification tasks to low-level dense prediction tasks. In this paper, we conduct research on applying the transformer networks for salient object detection (SOD). Specifically, we adopt the dense transformer backbone for fully supervised RGB image based SOD, RGB-D image pair based SOD, and weakly supervised SOD via scribble supervision. As an extension, we also apply our fully supervised model to the task of camouflaged object detection (COD) for camouflaged object segmentation. For the fully supervised models, we define the dense transformer backbone as feature encoder, and design a very simple decoder to produce a one channel saliency map (or camouflage map for the COD task). For the weakly supervised model, as there exists no structure information in the scribble annotation, we first adopt the recent proposed Gated-CRF loss to effectively model the pair-wise relationships for accurate model prediction. Then, we introduce self-supervised learning strategy to push the model to produce scale-invariant predictions, which is proven effective for weakly supervised models and models trained on small training datasets. Extensive experimental results on various SOD and COD tasks (fully supervised RGB image based SOD, fully supervised RGB-D image pair based SOD, weakly supervised SOD via scribble supervision, and fully supervised RGB image based COD) illustrate that transformer networks can transform salient object detection and camouflaged object detection, leading to new benchmarks for each related task.
Kaleido-BERT: Vision-Language Pre-training on Fashion Domain
Apr 15, 2021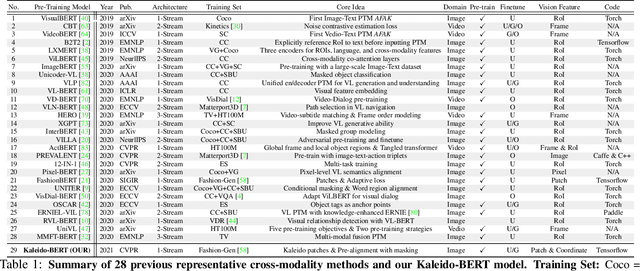
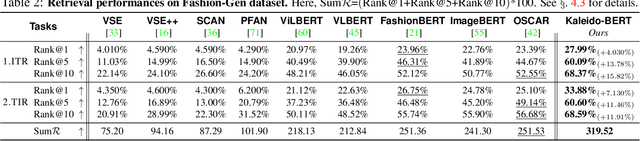
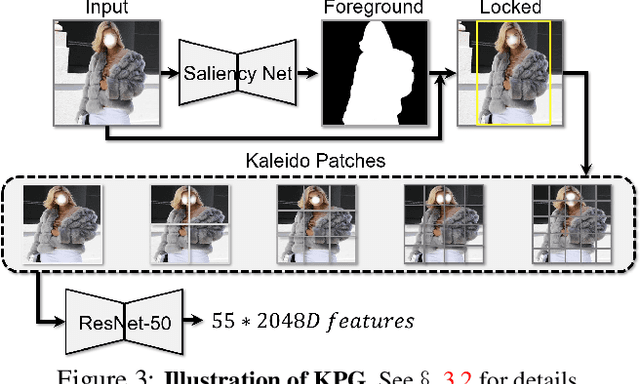
We present a new vision-language (VL) pre-training model dubbed Kaleido-BERT, which introduces a novel kaleido strategy for fashion cross-modality representations from transformers. In contrast to random masking strategy of recent VL models, we design alignment guided masking to jointly focus more on image-text semantic relations. To this end, we carry out five novel tasks, i.e., rotation, jigsaw, camouflage, grey-to-color, and blank-to-color for self-supervised VL pre-training at patches of different scale. Kaleido-BERT is conceptually simple and easy to extend to the existing BERT framework, it attains new state-of-the-art results by large margins on four downstream tasks, including text retrieval (R@1: 4.03% absolute improvement), image retrieval (R@1: 7.13% abs imv.), category recognition (ACC: 3.28% abs imv.), and fashion captioning (Bleu4: 1.2 abs imv.). We validate the efficiency of Kaleido-BERT on a wide range of e-commerical websites, demonstrating its broader potential in real-world applications.
Mutual Graph Learning for Camouflaged Object Detection
Apr 03, 2021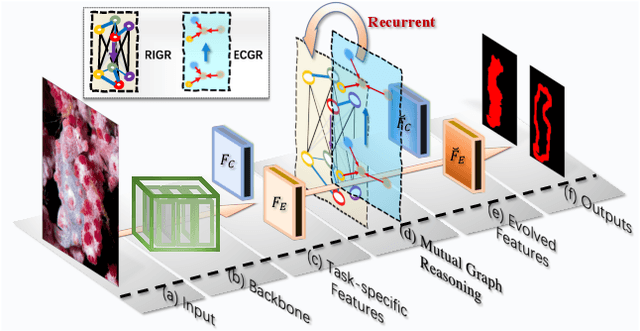
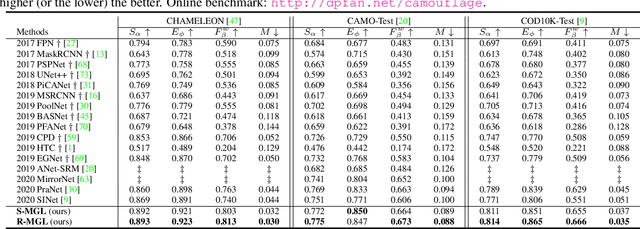
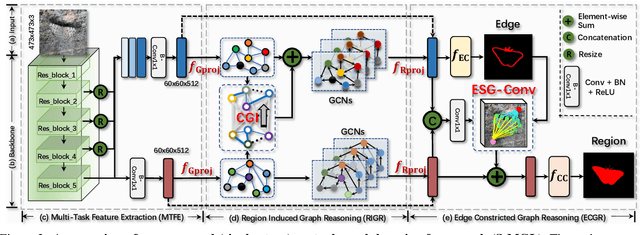

Automatically detecting/segmenting object(s) that blend in with their surroundings is difficult for current models. A major challenge is that the intrinsic similarities between such foreground objects and background surroundings make the features extracted by deep model indistinguishable. To overcome this challenge, an ideal model should be able to seek valuable, extra clues from the given scene and incorporate them into a joint learning framework for representation co-enhancement. With this inspiration, we design a novel Mutual Graph Learning (MGL) model, which generalizes the idea of conventional mutual learning from regular grids to the graph domain. Specifically, MGL decouples an image into two task-specific feature maps -- one for roughly locating the target and the other for accurately capturing its boundary details -- and fully exploits the mutual benefits by recurrently reasoning their high-order relations through graphs. Importantly, in contrast to most mutual learning approaches that use a shared function to model all between-task interactions, MGL is equipped with typed functions for handling different complementary relations to maximize information interactions. Experiments on challenging datasets, including CHAMELEON, CAMO and COD10K, demonstrate the effectiveness of our MGL with superior performance to existing state-of-the-art methods.