 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndiscernible Object Counting in Underwater Scenes
Apr 23, 2023



Recently, indiscernible scene understanding has attracted a lot of attention in the vision community. We further advance the frontier of this field by systematically studying a new challenge named indiscernible object counting (IOC), the goal of which is to count objects that are blended with respect to their surroundings. Due to a lack of appropriate IOC datasets, we present a large-scale dataset IOCfish5K which contains a total of 5,637 high-resolution images and 659,024 annotated center points. Our dataset consists of a large number of indiscernible objects (mainly fish) in underwater scenes, making the annotation process all the more challenging. IOCfish5K is superior to existing datasets with indiscernible scenes because of its larger scale, higher image resolutions, more annotations, and denser scenes. All these aspects make it the most challenging dataset for IOC so far, supporting progress in this area. For benchmarking purposes, we select 14 mainstream methods for object counting and carefully evaluate them on IOCfish5K. Furthermore, we propose IOCFormer, a new strong baseline that combines density and regression branches in a unified framework and can effectively tackle object counting under concealed scenes. Experiments show that IOCFormer achieves state-of-the-art scores on IOCfish5K.
Advances in Deep Concealed Scene Understanding
Apr 21, 2023Concealed scene understanding (CSU) is a hot computer vision topic aiming to perceive objects with camouflaged properties. The current boom in its advanced techniques and novel applications makes it timely to provide an up-to-date survey to enable researchers to understand the global picture of the CSU field, including both current achievements and major challenges. This paper makes four contributions: (1) For the first time, we present a comprehensive survey of the deep learning techniques oriented at CSU, including a background with its taxonomy, task-unique challenges, and a review of its developments in the deep learning era via surveying existing datasets and deep techniques. (2) For a quantitative comparison of the state-of-the-art, we contribute the largest and latest benchmark for Concealed Object Segmentation (COS). (3) To evaluate the transferability of deep CSU in practical scenarios, we re-organize the largest concealed defect segmentation dataset termed CDS2K with the hard cases from diversified industrial scenarios, on which we construct a comprehensive benchmark. (4) We discuss open problems and potential research directions for this community. Our code and datasets are available at https://github.com/DengPingFan/CSU, which will be updated continuously to watch and summarize the advancements in this rapidly evolving field.
CamDiff: Camouflage Image Augmentation via Diffusion Model
Apr 11, 2023The burgeoning field of camouflaged object detection (COD) seeks to identify objects that blend into their surroundings. Despite the impressive performance of recent models, we have identified a limitation in their robustness, where existing methods may misclassify salient objects as camouflaged ones, despite these two characteristics being contradictory. This limitation may stem from lacking multi-pattern training images, leading to less saliency robustness. To address this issue, we introduce CamDiff, a novel approach inspired by AI-Generated Content (AIGC) that overcomes the scarcity of multi-pattern training images. Specifically, we leverage the latent diffusion model to synthesize salient objects in camouflaged scenes, while using the zero-shot image classification ability of the Contrastive Language-Image Pre-training (CLIP) model to prevent synthesis failures and ensure the synthesized object aligns with the input prompt. Consequently, the synthesized image retains its original camouflage label while incorporating salient objects, yielding camouflage samples with richer characteristics. The results of user studies show that the salient objects in the scenes synthesized by our framework attract the user's attention more; thus, such samples pose a greater challenge to the existing COD models. Our approach enables flexible editing and efficient large-scale dataset generation at a low cost. It significantly enhances COD baselines' training and testing phases, emphasizing robustness across diverse domains. Our newly-generated datasets and source code are available at https://github.com/drlxj/CamDiff.
QR-CLIP: Introducing Explicit Open-World Knowledge for Location and Time Reasoning
Feb 02, 2023Daily images may convey abstract meanings that require us to memorize and infer profound information from them. To encourage such human-like reasoning, in this work, we teach machines to predict where and when it was taken rather than performing basic tasks like traditional segmentation or classification. Inspired by Horn's QR theory, we designed a novel QR-CLIP model consisting of two components: 1) the Quantity module first retrospects more open-world knowledge as the candidate language inputs; 2) the Relevance module carefully estimates vision and language cues and infers the location and time. Experiments show our QR-CLIP's effectiveness, and it outperforms the previous SOTA on each task by an average of about 10% and 130% relative lift in terms of location and time reasoning. This study lays a technical foundation for location and time reasoning and suggests that effectively introducing open-world knowledge is one of the panaceas for the tasks.
Source-free Depth for Object Pop-out
Dec 10, 2022



Depth cues are known to be useful for visual perception. However, direct measurement of depth is often impracticable. Fortunately, though, modern learning-based methods offer promising depth maps by inference in the wild. In this work, we adapt such depth inference models for object segmentation using the objects' ``pop-out'' prior in 3D. The ``pop-out'' is a simple composition prior that assumes objects reside on the background surface. Such compositional prior allows us to reason about objects in the 3D space. More specifically, we adapt the inferred depth maps such that objects can be localized using only 3D information. Such separation, however, requires knowledge about contact surface which we learn using the weak supervision of the segmentation mask. Our intermediate representation of contact surface, and thereby reasoning about objects purely in 3D, allows us to better transfer the depth knowledge into semantics. The proposed adaptation method uses only the depth model without needing the source data used for training, making the learning process efficient and practical. Our experiments on eight datasets of two challenging tasks, namely camouflaged object detection and salient object detection, consistently demonstrate the benefit of our method in terms of both performance and generalizability.
CamoFormer: Masked Separable Attention for Camouflaged Object Detection
Dec 10, 2022



How to identify and segment camouflaged objects from the background is challenging. Inspired by the multi-head self-attention in Transformers, we present a simple masked separable attention (MSA) for camouflaged object detection. We first separate the multi-head self-attention into three parts, which are responsible for distinguishing the camouflaged objects from the background using different mask strategies. Furthermore, we propose to capture high-resolution semantic representations progressively based on a simple top-down decoder with the proposed MSA to attain precise segmentation results. These structures plus a backbone encoder form a new model, dubbed CamoFormer. Extensive experiments show that CamoFormer surpasses all existing state-of-the-art methods on three widely-used camouflaged object detection benchmarks. There are on average around 5% relative improvements over previous methods in terms of S-measure and weighted F-measure.
Masked Vision-Language Transformer in Fashion
Oct 27, 2022We present a masked vision-language transformer (MVLT) for fashion-specific multi-modal representation. Technically, we simply utilize vision transformer architecture for replacing the BERT in the pre-training model, making MVLT the first end-to-end framework for the fashion domain. Besides, we designed masked image reconstruction (MIR) for a fine-grained understanding of fashion. MVLT is an extensible and convenient architecture that admits raw multi-modal inputs without extra pre-processing models (e.g., ResNet), implicitly modeling the vision-language alignments. More importantly, MVLT can easily generalize to various matching and generative tasks. Experimental results show obvious improvements in retrieval (rank@5: 17%) and recognition (accuracy: 3%) tasks over the Fashion-Gen 2018 winner Kaleido-BERT. Code is made available at https://github.com/GewelsJI/MVLT.
OSFormer: One-Stage Camouflaged Instance Segmentation with Transformers
Jul 08, 2022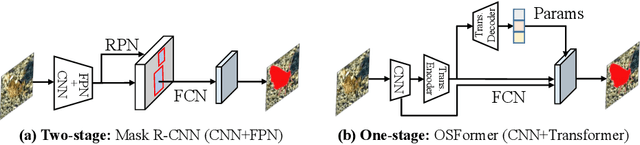
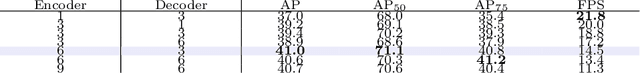

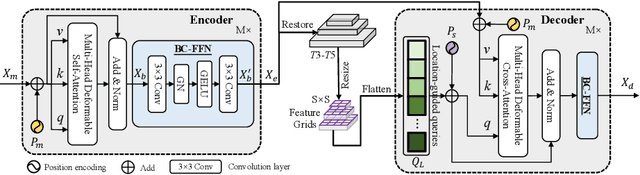
We present OSFormer, the first one-stage transformer framework for camouflaged instance segmentation (CIS). OSFormer is based on two key designs. First, we design a location-sensing transformer (LST) to obtain the location label and instance-aware parameters by introducing the location-guided queries and the blend-convolution feedforward network. Second, we develop a coarse-to-fine fusion (CFF) to merge diverse context information from the LST encoder and CNN backbone. Coupling these two components enables OSFormer to efficiently blend local features and long-range context dependencies for predicting camouflaged instances. Compared with two-stage frameworks, our OSFormer reaches 41% AP and achieves good convergence efficiency without requiring enormous training data, i.e., only 3,040 samples under 60 epochs. Code link: https://github.com/PJLallen/OSFormer.
GCoNet+: A Stronger Group Collaborative Co-Salient Object Detector
Jun 01, 2022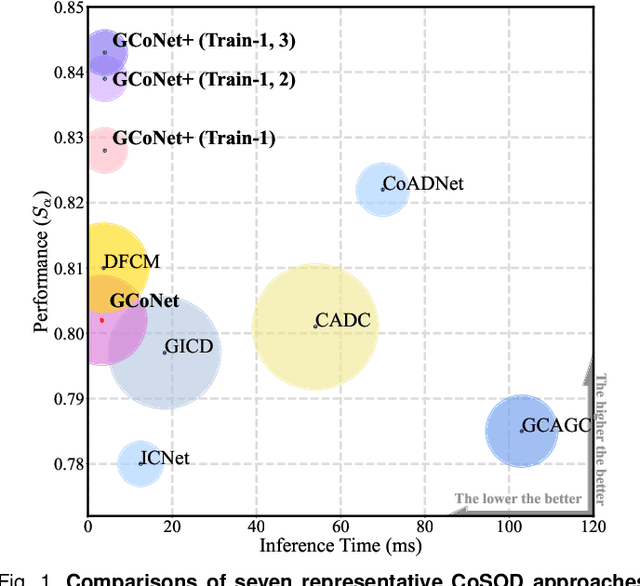



In this paper, we present a novel end-to-end group collaborative learning network, termed GCoNet+, which can effectively and efficiently (250 fps) identify co-salient objects in natural scenes. The proposed GCoNet+ achieves the new state-of-the-art performance for co-salient object detection (CoSOD) through mining consensus representations based on the following two essential criteria: 1) intra-group compactness to better formulate the consistency among co-salient objects by capturing their inherent shared attributes using our novel group affinity module (GAM); 2) inter-group separability to effectively suppress the influence of noisy objects on the output by introducing our new group collaborating module (GCM) conditioning on the inconsistent consensus. To further improve the accuracy, we design a series of simple yet effective components as follows: i) a recurrent auxiliary classification module (RACM) promoting the model learning at the semantic level; ii) a confidence enhancement module (CEM) helping the model to improve the quality of the final predictions; and iii) a group-based symmetric triplet (GST) loss guiding the model to learn more discriminative features. Extensive experiments on three challenging benchmarks, i.e., CoCA, CoSOD3k, and CoSal2015, demonstrate that our GCoNet+ outperforms the existing 12 cutting-edge models. Code has been released at https://github.com/ZhengPeng7/GCoNet_plus.
Deep Gradient Learning for Efficient Camouflaged Object Detection
May 25, 2022
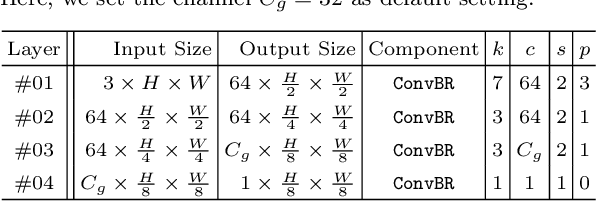

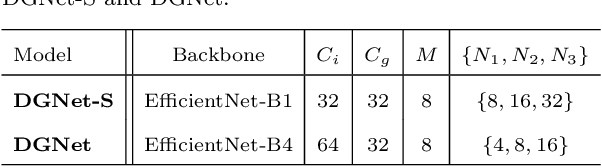
This paper introduces DGNet, a novel deep framework that exploits object gradient supervision for camouflaged object detection (COD). It decouples the task into two connected branches, i.e., a context and a texture encoder. The essential connection is the gradient-induced transition, representing a soft grouping between context and texture features. Benefiting from the simple but efficient framework, DGNet outperforms existing state-of-the-art COD models by a large margin. Notably, our efficient version, DGNet-S, runs in real-time (80 fps) and achieves comparable results to the cutting-edge model JCSOD-CVPR$_{21}$ with only 6.82% parameters. Application results also show that the proposed DGNet performs well in polyp segmentation, defect detection, and transparent object segmentation tasks. Codes will be made available at https://github.com/GewelsJI/DGNet.