 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowDA: All-in-One Knowledge Mixture Model for Data Augmentation in Few-Shot NLP
Jun 21, 2022
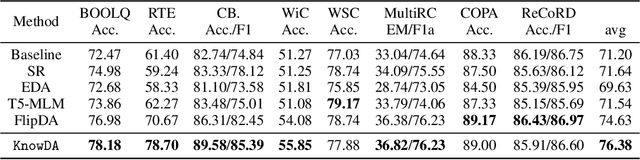
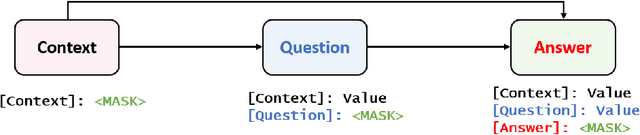
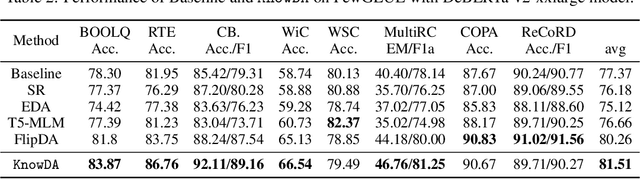
This paper focuses on text data augmentation for few-shot NLP tasks. The existing data augmentation algorithms either leverage task-independent heuristic rules (e.g., Synonym Replacement) or fine-tune general-purpose pre-trained language models (e.g., GPT2) using a small training set to produce new synthetic data. Consequently, these methods have trivial task-specific knowledge and are limited to yielding low-quality synthetic data for weak baselines in simple tasks. To combat this issue, we propose the Knowledge Mixture Data Augmentation Model (KnowDA): an encoder-decoder LM pretrained on a mixture of diverse NLP tasks using Knowledge Mixture Training (KoMT). KoMT is a training procedure that reformulates input examples from various heterogeneous NLP tasks into a unified text-to-text format and employs denoising objectives in different granularity to learn to generate partial or complete samples. With the aid of KoMT, KnowDA could combine required task-specific knowledge implicitly from the learned mixture of tasks and quickly grasp the inherent synthesis law of the target task through a few given instances. To the best of our knowledge, we are the first attempt to scale the number of tasks to 100+ in multi-task co-training for data augmentation. Extensive experiments show that i) KnowDA successfully improves the performance of Albert and Deberta by a large margin on the FewGLUE benchmark, outperforming previous state-of-the-art data augmentation baselines; ii) KnowDA could also improve the model performance on the few-shot NER tasks, a held-out task type not included in KoMT.
Bridging the Gap Between Indexing and Retrieval for Differentiable Search Index with Query Generation
Jun 21, 2022
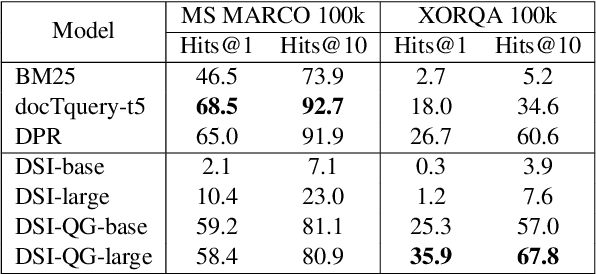
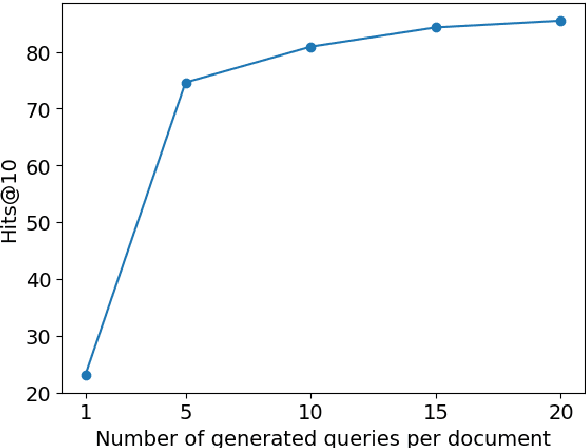
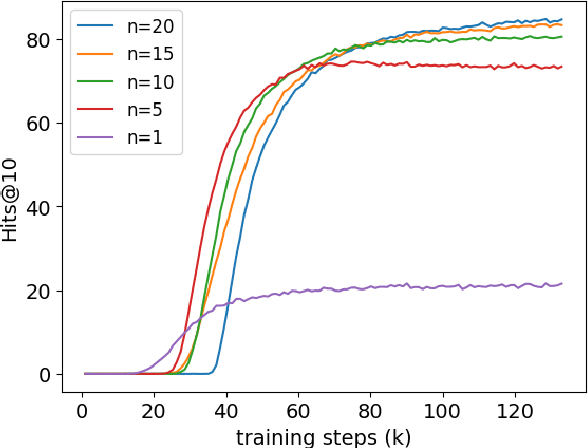
The Differentiable Search Index (DSI) is a new, emerging paradigm for information retrieval. Unlike traditional retrieval architectures where index and retrieval are two different and separate components, DSI uses a single transformer model to perform both indexing and retrieval. In this paper, we identify and tackle an important issue of current DSI models: the data distribution mismatch that occurs between the DSI indexing and retrieval processes. Specifically, we argue that, at indexing, current DSI methods learn to build connections between long document texts and their identifies, but then at retrieval, short query texts are provided to DSI models to perform the retrieval of the document identifiers. This problem is further exacerbated when using DSI for cross-lingual retrieval, where document text and query text are in different languages. To address this fundamental problem of current DSI models we propose a simple yet effective indexing framework for DSI called DSI-QG. In DSI-QG, documents are represented by a number of relevant queries generated by a query generation model at indexing time. This allows DSI models to connect a document identifier to a set of query texts when indexing, hence mitigating data distribution mismatches present between the indexing and the retrieval phases. Empirical results on popular mono-lingual and cross-lingual passage retrieval benchmark datasets show that DSI-QG significantly outperforms the original DSI model.
Towards Robust Ranker for Text Retrieval
Jun 16, 2022
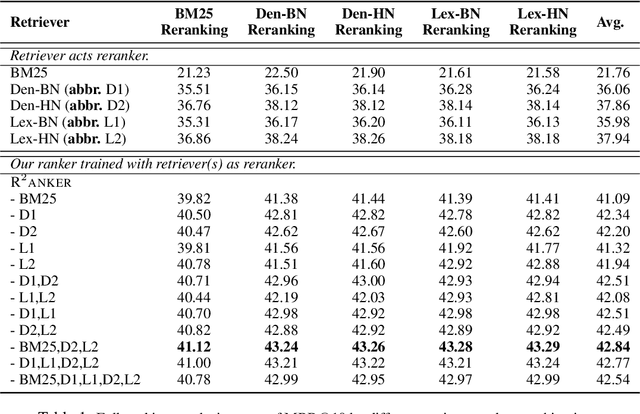
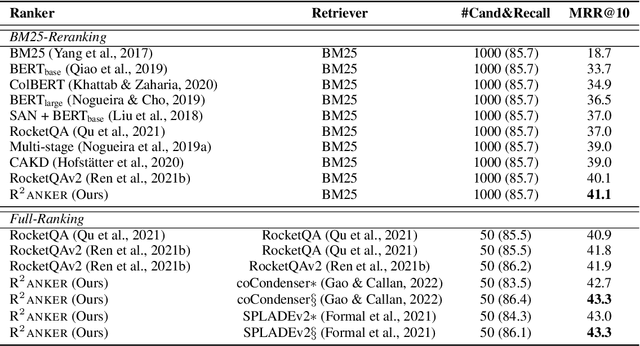
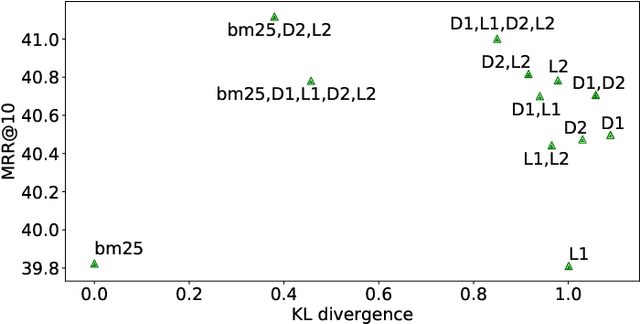
A ranker plays an indispensable role in the de facto 'retrieval & rerank' pipeline, but its training still lags behind -- learning from moderate negatives or/and serving as an auxiliary module for a retriever. In this work, we first identify two major barriers to a robust ranker, i.e., inherent label noises caused by a well-trained retriever and non-ideal negatives sampled for a high-capable ranker. Thereby, we propose multiple retrievers as negative generators improve the ranker's robustness, where i) involving extensive out-of-distribution label noises renders the ranker against each noise distribution, and ii) diverse hard negatives from a joint distribution are relatively close to the ranker's negative distribution, leading to more challenging thus effective training. To evaluate our robust ranker (dubbed R$^2$anker), we conduct experiments in various settings on the popular passage retrieval benchmark, including BM25-reranking, full-ranking, retriever distillation, etc. The empirical results verify the new state-of-the-art effectiveness of our model.
Unsupervised Context Aware Sentence Representation Pretraining for Multi-lingual Dense Retrieval
Jun 07, 2022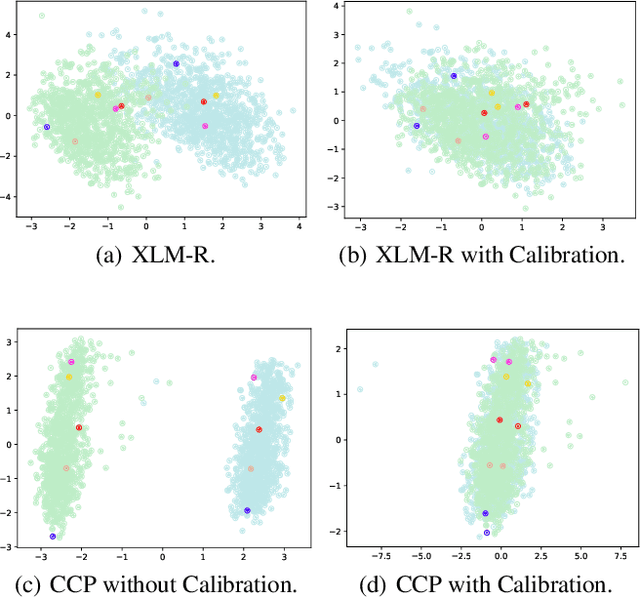

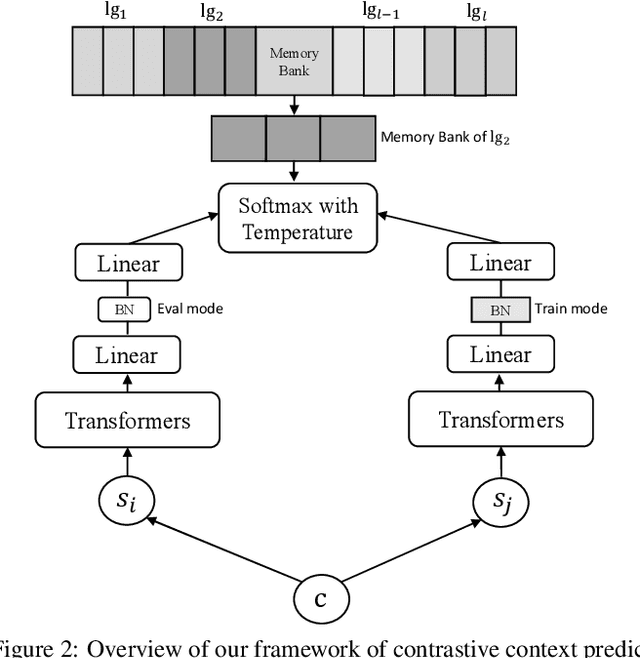

Recent research demonstrates the effectiveness of using pretrained language models (PLM) to improve dense retrieval and multilingual dense retrieval. In this work, we present a simple but effective monolingual pretraining task called contrastive context prediction~(CCP) to learn sentence representation by modeling sentence level contextual relation. By pushing the embedding of sentences in a local context closer and pushing random negative samples away, different languages could form isomorphic structure, then sentence pairs in two different languages will be automatically aligned. Our experiments show that model collapse and information leakage are very easy to happen during contrastive training of language model, but language-specific memory bank and asymmetric batch normalization operation play an essential role in preventing collapsing and information leakage, respectively. Besides, a post-processing for sentence embedding is also very effective to achieve better retrieval performance. On the multilingual sentence retrieval task Tatoeba, our model achieves new SOTA results among methods without using bilingual data. Our model also shows larger gain on Tatoeba when transferring between non-English pairs. On two multi-lingual query-passage retrieval tasks, XOR Retrieve and Mr.TYDI, our model even achieves two SOTA results in both zero-shot and supervised setting among all pretraining models using bilingual data.
Task-Specific Expert Pruning for Sparse Mixture-of-Experts
Jun 02, 2022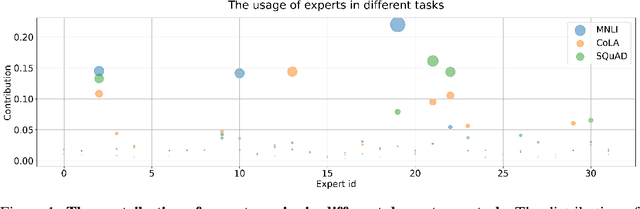
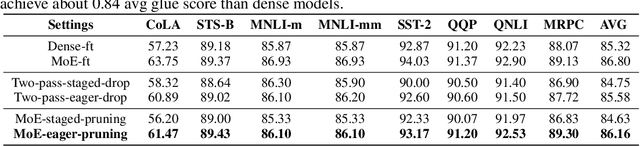
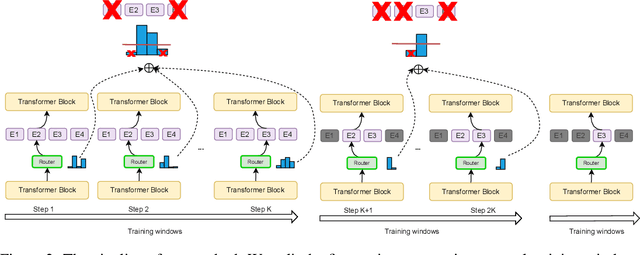
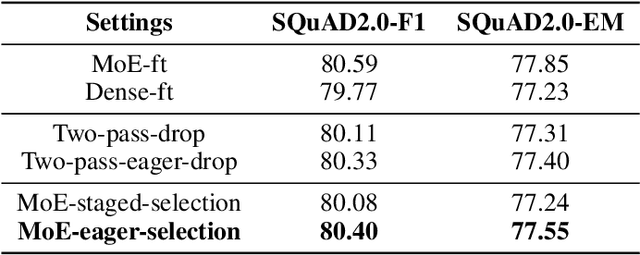
The sparse Mixture-of-Experts (MoE) model is powerful for large-scale pre-training and has achieved promising results due to its model capacity. However, with trillions of parameters, MoE is hard to be deployed on cloud or mobile environment. The inference of MoE requires expert parallelism, which is not hardware-friendly and communication expensive. Especially for resource-limited downstream tasks, such sparse structure has to sacrifice a lot of computing efficiency for limited performance gains. In this work, we observe most experts contribute scarcely little to the MoE fine-tuning and inference. We further propose a general method to progressively drop the non-professional experts for the target downstream task, which preserves the benefits of MoE while reducing the MoE model into one single-expert dense model. Our experiments reveal that the fine-tuned single-expert model could preserve 99.3% benefits from MoE across six different types of tasks while enjoying 2x inference speed with free communication cost.
THE-X: Privacy-Preserving Transformer Inference with Homomorphic Encryption
Jun 02, 2022As more and more pre-trained language models adopt on-cloud deployment, the privacy issues grow quickly, mainly for the exposure of plain-text user data (e.g., search history, medical record, bank account). Privacy-preserving inference of transformer models is on the demand of cloud service users. To protect privacy, it is an attractive choice to compute only with ciphertext in homomorphic encryption (HE). However, enabling pre-trained models inference on ciphertext data is difficult due to the complex computations in transformer blocks, which are not supported by current HE tools yet. In this work, we introduce $\textit{THE-X}$, an approximation approach for transformers, which enables privacy-preserving inference of pre-trained models developed by popular frameworks. $\textit{THE-X}$ proposes a workflow to deal with complex computation in transformer networks, including all the non-polynomial functions like GELU, softmax, and LayerNorm. Experiments reveal our proposed $\textit{THE-X}$ can enable transformer inference on encrypted data for different downstream tasks, all with negligible performance drop but enjoying the theory-guaranteed privacy-preserving advantage.
Negative Sampling for Contrastive Representation Learning: A Review
Jun 01, 2022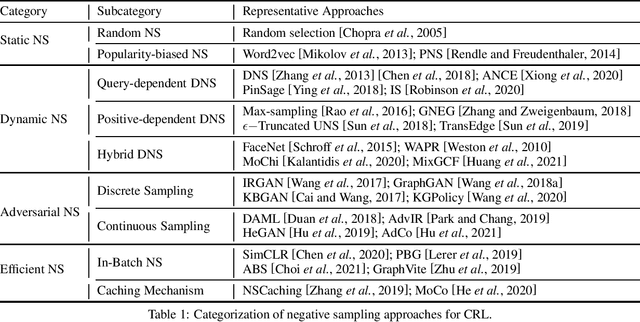
The learn-to-compare paradigm of contrastive representation learning (CRL), which compares positive samples with negative ones for representation learning, has achieved great success in a wide range of domains, including natural language processing, computer vision, information retrieval and graph learning. While many research works focus on data augmentations, nonlinear transformations or other certain parts of CRL, the importance of negative sample selection is usually overlooked in literature. In this paper, we provide a systematic review of negative sampling (NS) techniques and discuss how they contribute to the success of CRL. As the core part of this paper, we summarize the existing NS methods into four categories with pros and cons in each genre, and further conclude with several open research questions as future directions. By generalizing and aligning the fundamental NS ideas across multiple domains, we hope this survey can accelerate cross-domain knowledge sharing and motivate future researches for better CRL.
UnifieR: A Unified Retriever for Large-Scale Retrieval
May 23, 2022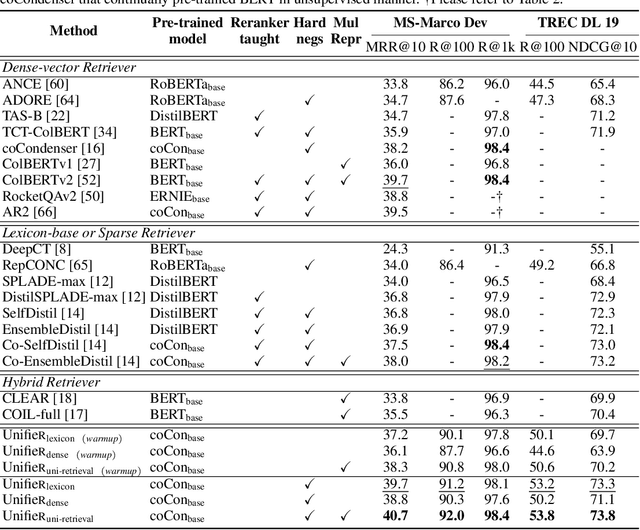
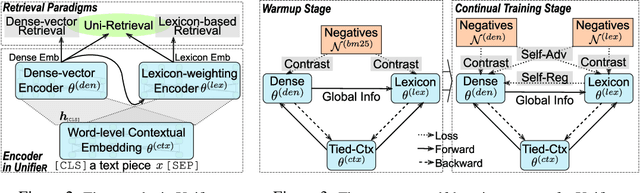
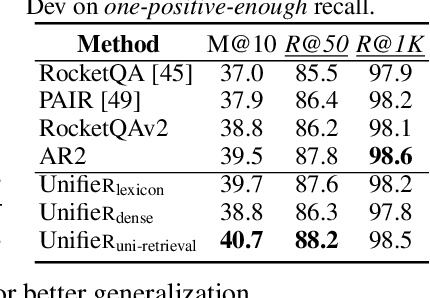
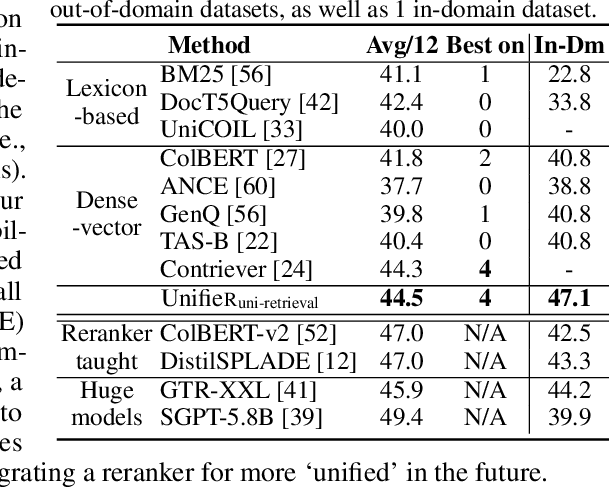
Large-scale retrieval is to recall relevant documents from a huge collection given a query. It relies on representation learning to embed documents and queries into a common semantic encoding space. According to the encoding space, recent retrieval methods based on pre-trained language models (PLM) can be coarsely categorized into either dense-vector or lexicon-based paradigms. These two paradigms unveil the PLMs' representation capability in different granularities, i.e., global sequence-level compression and local word-level contexts, respectively. Inspired by their complementary global-local contextualization and distinct representing views, we propose a new learning framework, UnifieR, which unifies dense-vector and lexicon-based retrieval in one model with a dual-representing capability. Experiments on passage retrieval benchmarks verify its effectiveness in both paradigms. A uni-retrieval scheme is further presented with even better retrieval quality. We lastly evaluate the model on BEIR benchmark to verify its transferability.
Multi-level Contrastive Learning for Cross-lingual Spoken Language Understanding
May 07, 2022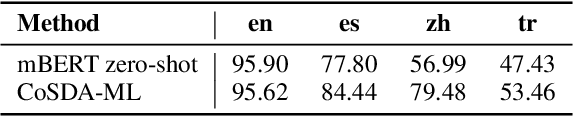
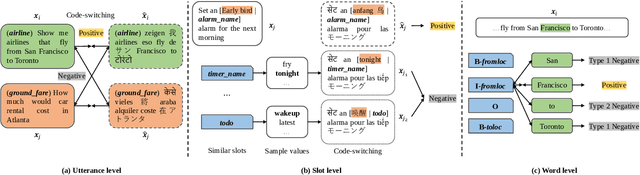
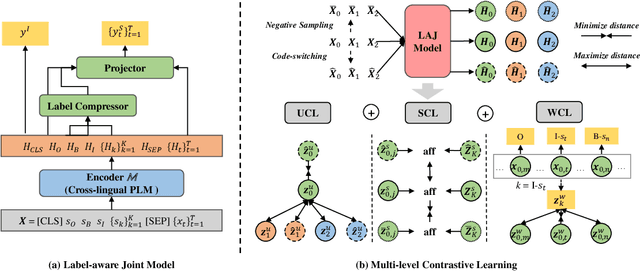
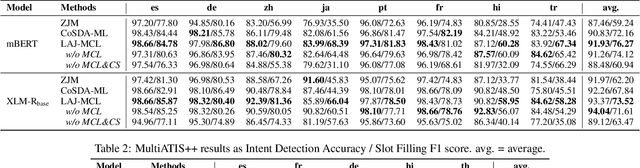
Although spoken language understanding (SLU) has achieved great success in high-resource languages, such as English, it remains challenging in low-resource languages mainly due to the lack of high quality training data. The recent multilingual code-switching approach samples some words in an input utterance and replaces them by expressions in some other languages of the same meaning. The multilingual code-switching approach achieves better alignments of representations across languages in zero-shot cross-lingual SLU. Surprisingly, all existing multilingual code-switching methods disregard the inherent semantic structure in SLU, i.e., most utterances contain one or more slots, and each slot consists of one or more words. In this paper, we propose to exploit the "utterance-slot-word" structure of SLU and systematically model this structure by a multi-level contrastive learning framework at the utterance, slot, and word levels. We develop novel code-switching schemes to generate hard negative examples for contrastive learning at all levels. Furthermore, we develop a label-aware joint model to leverage label semantics for cross-lingual knowledge transfer. Our experimental results show that our proposed methods significantly improve the performance compared with the strong baselines on two zero-shot cross-lingual SLU benchmark datasets.
Stylized Knowledge-Grounded Dialogue Generation via Disentangled Template Rewriting
Apr 12, 2022
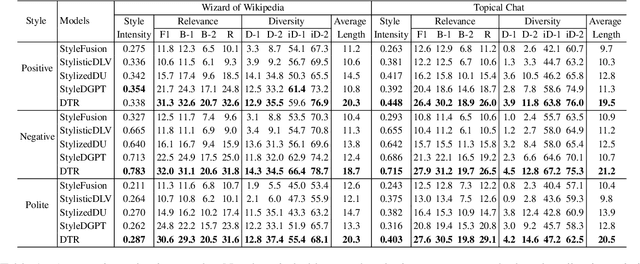
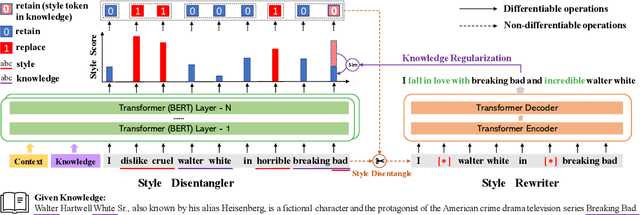
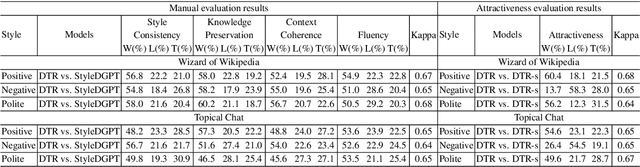
Current Knowledge-Grounded Dialogue Generation (KDG) models specialize in producing rational and factual responses. However, to establish long-term relationships with users, the KDG model needs the capability to generate responses in a desired style or attribute. Thus, we study a new problem: Stylized Knowledge-Grounded Dialogue Generation (SKDG). It presents two challenges: (1) How to train a SKDG model where no <context, knowledge, stylized response> triples are available. (2) How to cohere with context and preserve the knowledge when generating a stylized response. In this paper, we propose a novel disentangled template rewriting (DTR) method which generates responses via combing disentangled style templates (from monolingual stylized corpus) and content templates (from KDG corpus). The entire framework is end-to-end differentiable and learned without supervision. Extensive experiments on two benchmarks indicate that DTR achieves a significant improvement on all evaluation metrics compared with previous state-of-the-art stylized dialogue generation methods. Besides, DTR achieves comparable performance with the state-of-the-art KDG methods in standard KDG evaluation setting.