 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Blocks and Fuel: Frameworks for deep learning
Jun 01, 2015We introduce two Python frameworks to train neural networks on large datasets: Blocks and Fuel. Blocks is based on Theano, a linear algebra compiler with CUDA-support. It facilitates the training of complex neural network models by providing parametrized Theano operations, attaching metadata to Theano's symbolic computational graph, and providing an extensive set of utilities to assist training the networks, e.g. training algorithms, logging, monitoring, visualization, and serialization. Fuel provides a standard format for machine learning datasets. It allows the user to easily iterate over large datasets, performing many types of pre-processing on the fly.
Self-informed neural network structure learning
Apr 13, 2015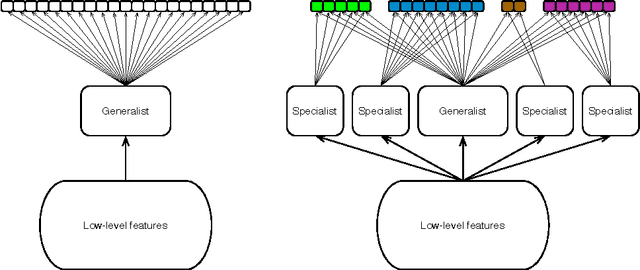

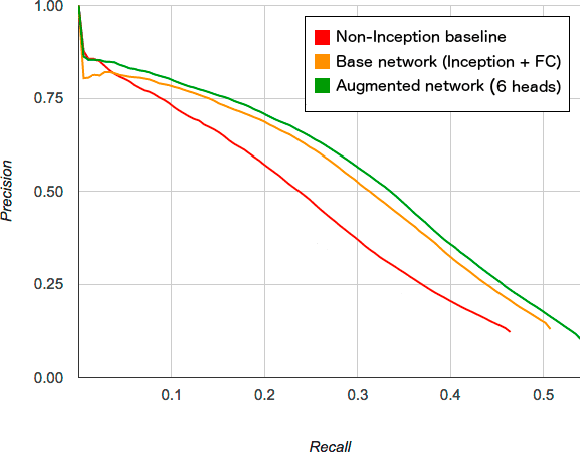
We study the problem of large scale, multi-label visual recognition with a large number of possible classes. We propose a method for augmenting a trained neural network classifier with auxiliary capacity in a manner designed to significantly improve upon an already well-performing model, while minimally impacting its computational footprint. Using the predictions of the network itself as a descriptor for assessing visual similarity, we define a partitioning of the label space into groups of visually similar entities. We then augment the network with auxilliary hidden layer pathways with connectivity only to these groups of label units. We report a significant improvement in mean average precision on a large-scale object recognition task with the augmented model, while increasing the number of multiply-adds by less than 3%.
EmoNets: Multimodal deep learning approaches for emotion recognition in video
Mar 30, 2015

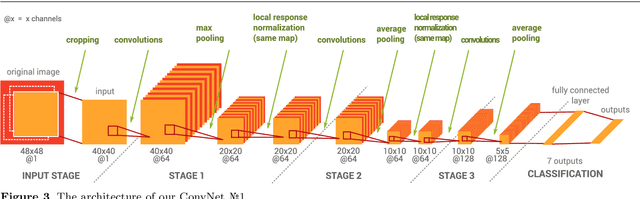
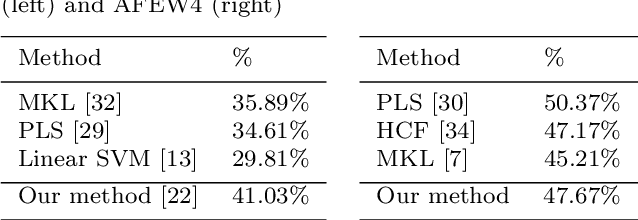
The task of the emotion recognition in the wild (EmotiW) Challenge is to assign one of seven emotions to short video clips extracted from Hollywood style movies. The videos depict acted-out emotions under realistic conditions with a large degree of variation in attributes such as pose and illumination, making it worthwhile to explore approaches which consider combinations of features from multiple modalities for label assignment. In this paper we present our approach to learning several specialist models using deep learning techniques, each focusing on one modality. Among these are a convolutional neural network, focusing on capturing visual information in detected faces, a deep belief net focusing on the representation of the audio stream, a K-Means based "bag-of-mouths" model, which extracts visual features around the mouth region and a relational autoencoder, which addresses spatio-temporal aspects of videos. We explore multiple methods for the combination of cues from these modalities into one common classifier. This achieves a considerably greater accuracy than predictions from our strongest single-modality classifier. Our method was the winning submission in the 2013 EmotiW challenge and achieved a test set accuracy of 47.67% on the 2014 dataset.
Generative Adversarial Networks
Jun 10, 2014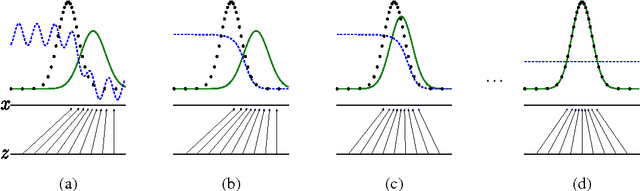
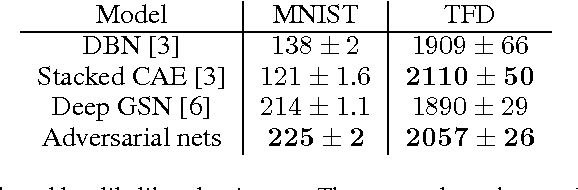

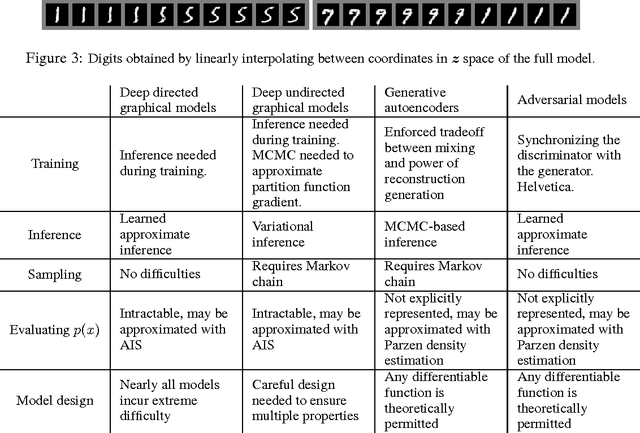
We propose a new framework for estimating generative models via an adversarial process, in which we simultaneously train two models: a generative model G that captures the data distribution, and a discriminative model D that estimates the probability that a sample came from the training data rather than G. The training procedure for G is to maximize the probability of D making a mistake. This framework corresponds to a minimax two-player game. In the space of arbitrary functions G and D, a unique solution exists, with G recovering the training data distribution and D equal to 1/2 everywhere. In the case where G and D are defined by multilayer perceptrons, the entire system can be trained with backpropagation. There is no need for any Markov chains or unrolled approximate inference networks during either training or generation of samples. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the generated samples.
An empirical analysis of dropout in piecewise linear networks
Jan 02, 2014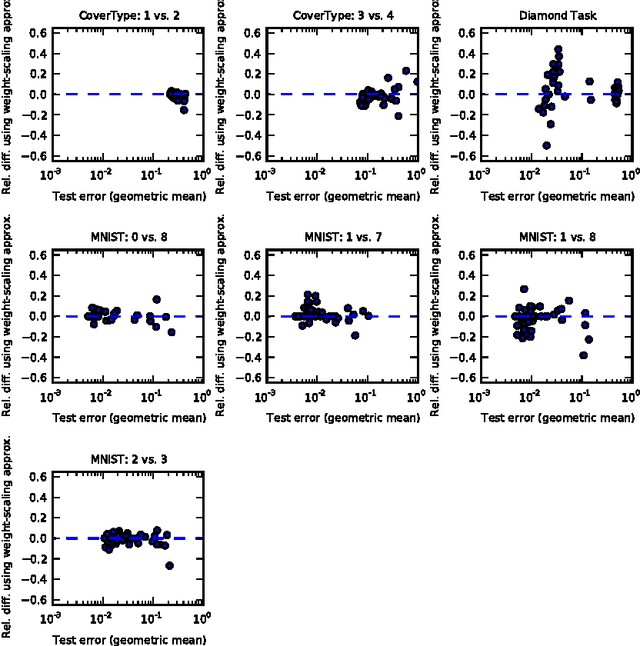
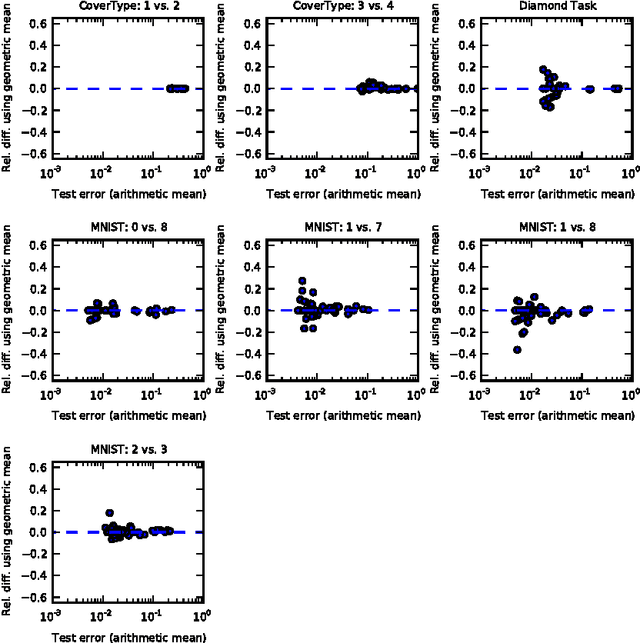
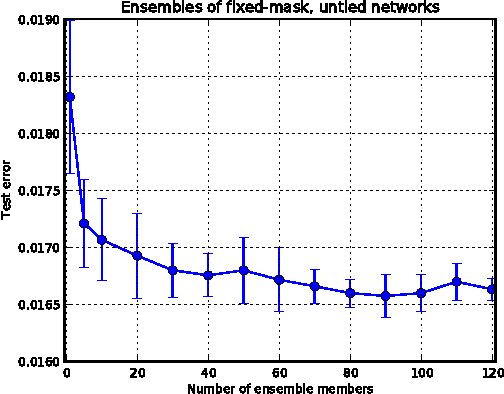
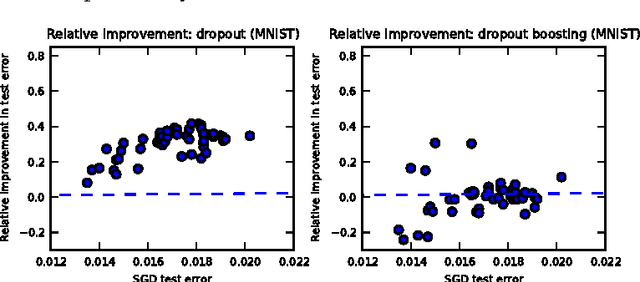
The recently introduced dropout training criterion for neural networks has been the subject of much attention due to its simplicity and remarkable effectiveness as a regularizer, as well as its interpretation as a training procedure for an exponentially large ensemble of networks that share parameters. In this work we empirically investigate several questions related to the efficacy of dropout, specifically as it concerns networks employing the popular rectified linear activation function. We investigate the quality of the test time weight-scaling inference procedure by evaluating the geometric average exactly in small models, as well as compare the performance of the geometric mean to the arithmetic mean more commonly employed by ensemble techniques. We explore the effect of tied weights on the ensemble interpretation by training ensembles of masked networks without tied weights. Finally, we investigate an alternative criterion based on a biased estimator of the maximum likelihood ensemble gradient.
Maxout Networks
Sep 20, 2013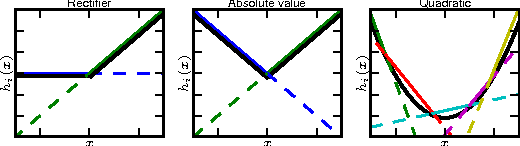
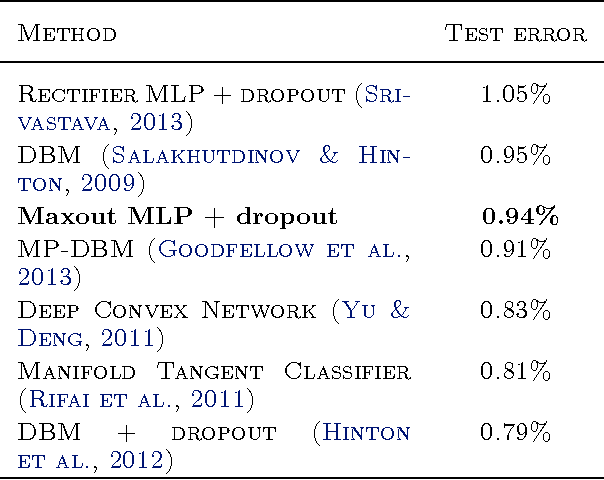
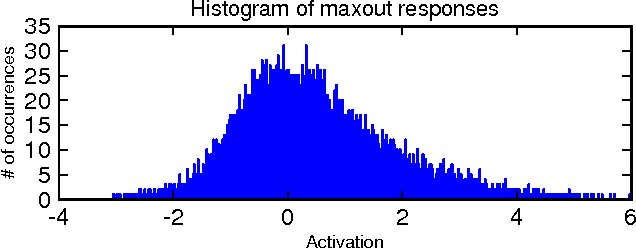

We consider the problem of designing models to leverage a recently introduced approximate model averaging technique called dropout. We define a simple new model called maxout (so named because its output is the max of a set of inputs, and because it is a natural companion to dropout) designed to both facilitate optimization by dropout and improve the accuracy of dropout's fast approximate model averaging technique. We empirically verify that the model successfully accomplishes both of these tasks. We use maxout and dropout to demonstrate state of the art classification performance on four benchmark datasets: MNIST, CIFAR-10, CIFAR-100, and SVHN.
* This is the version of the paper that appears in ICML 2013
Pylearn2: a machine learning research library
Aug 20, 2013Pylearn2 is a machine learning research library. This does not just mean that it is a collection of machine learning algorithms that share a common API; it means that it has been designed for flexibility and extensibility in order to facilitate research projects that involve new or unusual use cases. In this paper we give a brief history of the library, an overview of its basic philosophy, a summary of the library's architecture, and a description of how the Pylearn2 community functions socially.
Theano: new features and speed improvements
Nov 23, 2012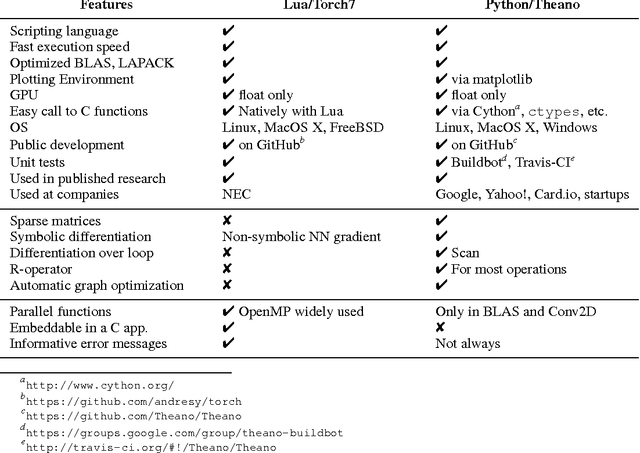
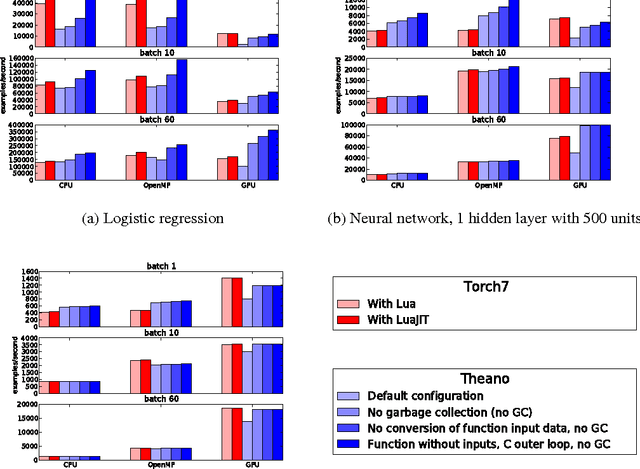
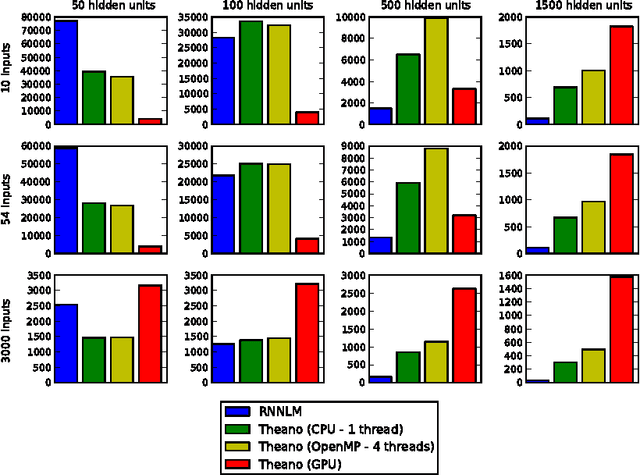
Theano is a linear algebra compiler that optimizes a user's symbolically-specified mathematical computations to produce efficient low-level implementations. In this paper, we present new features and efficiency improvements to Theano, and benchmarks demonstrating Theano's performance relative to Torch7, a recently introduced machine learning library, and to RNNLM, a C++ library targeted at recurrent neural networks.