 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding effective deep neural network architectures one feature at a time
Oct 19, 2017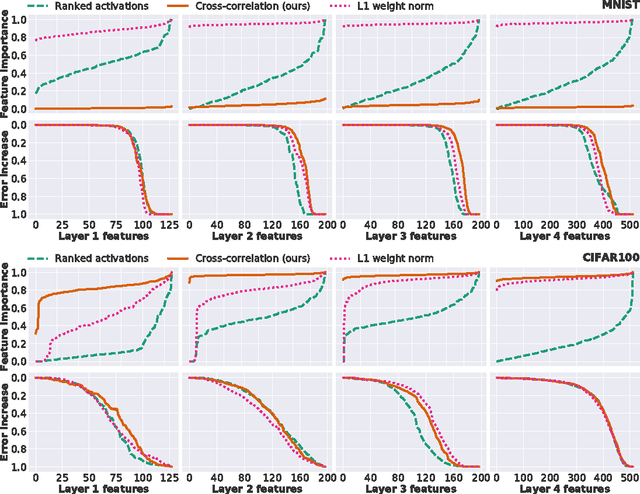
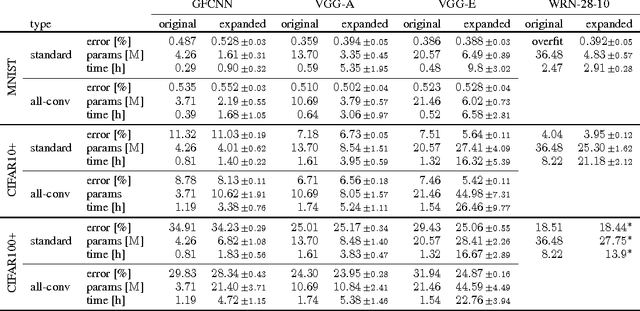
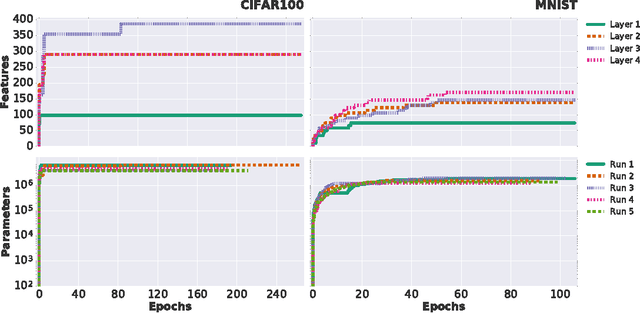

Successful training of convolutional neural networks is often associated with sufficiently deep architectures composed of high amounts of features. These networks typically rely on a variety of regularization and pruning techniques to converge to less redundant states. We introduce a novel bottom-up approach to expand representations in fixed-depth architectures. These architectures start from just a single feature per layer and greedily increase width of individual layers to attain effective representational capacities needed for a specific task. While network growth can rely on a family of metrics, we propose a computationally efficient version based on feature time evolution and demonstrate its potency in determining feature importance and a networks' effective capacity. We demonstrate how automatically expanded architectures converge to similar topologies that benefit from lesser amount of parameters or improved accuracy and exhibit systematic correspondence in representational complexity with the specified task. In contrast to conventional design patterns with a typical monotonic increase in the amount of features with increased depth, we observe that CNNs perform better when there is more learnable parameters in intermediate, with falloffs to earlier and later layers.
Dropout as data augmentation
Jan 08, 2016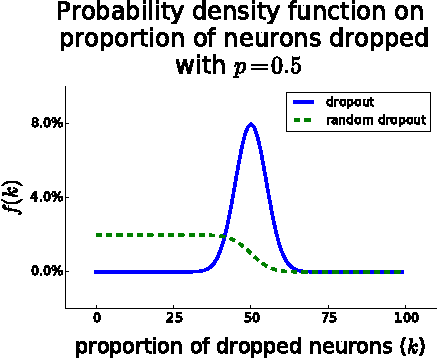
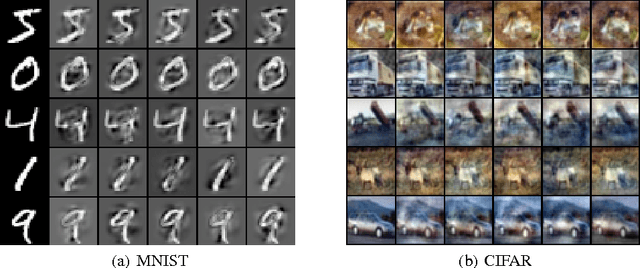

Dropout is typically interpreted as bagging a large number of models sharing parameters. We show that using dropout in a network can also be interpreted as a kind of data augmentation in the input space without domain knowledge. We present an approach to projecting the dropout noise within a network back into the input space, thereby generating augmented versions of the training data, and we show that training a deterministic network on the augmented samples yields similar results. Finally, we propose a new dropout noise scheme based on our observations and show that it improves dropout results without adding significant computational cost.
How far can we go without convolution: Improving fully-connected networks
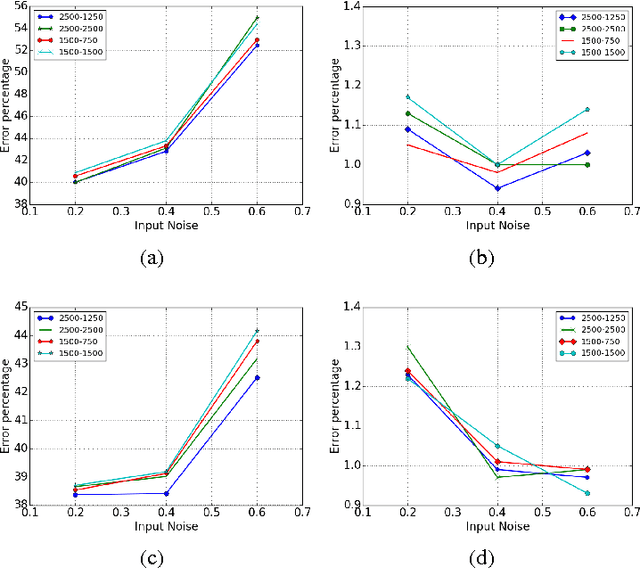
Nov 09, 2015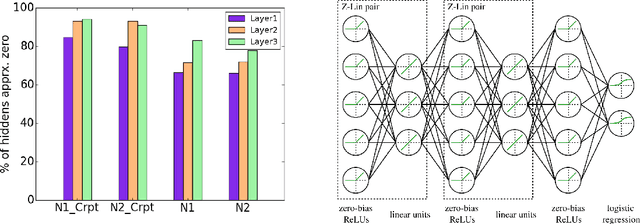
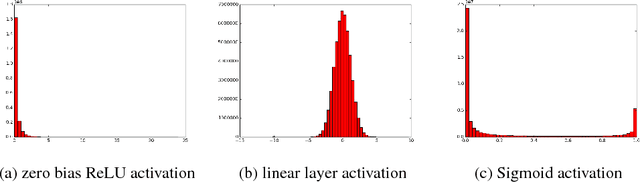
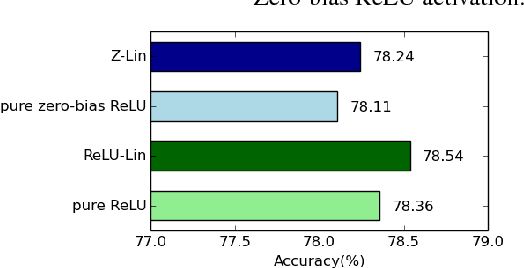
We propose ways to improve the performance of fully connected networks. We found that two approaches in particular have a strong effect on performance: linear bottleneck layers and unsupervised pre-training using autoencoders without hidden unit biases. We show how both approaches can be related to improving gradient flow and reducing sparsity in the network. We show that a fully connected network can yield approximately 70% classification accuracy on the permutation-invariant CIFAR-10 task, which is much higher than the current state-of-the-art. By adding deformations to the training data, the fully connected network achieves 78% accuracy, which is just 10% short of a decent convolutional network.
Zero-bias autoencoders and the benefits of co-adapting features
Apr 08, 2015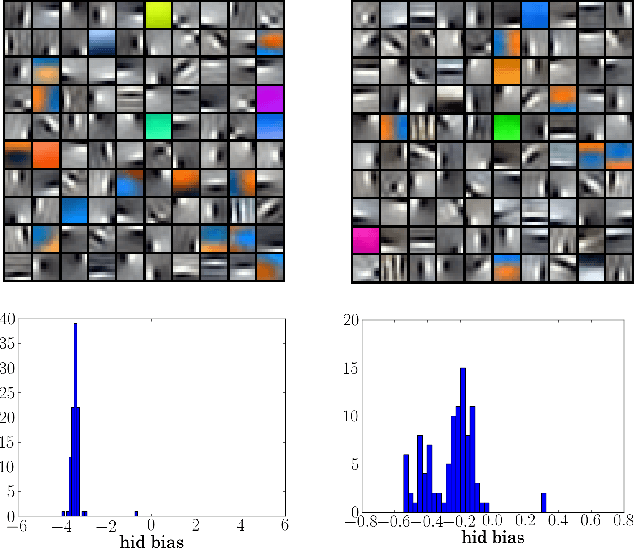

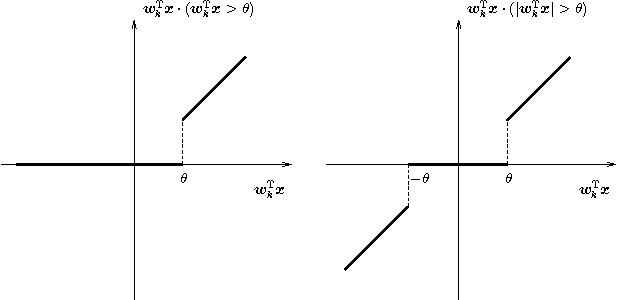
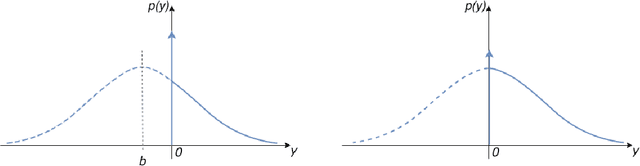
Regularized training of an autoencoder typically results in hidden unit biases that take on large negative values. We show that negative biases are a natural result of using a hidden layer whose responsibility is to both represent the input data and act as a selection mechanism that ensures sparsity of the representation. We then show that negative biases impede the learning of data distributions whose intrinsic dimensionality is high. We also propose a new activation function that decouples the two roles of the hidden layer and that allows us to learn representations on data with very high intrinsic dimensionality, where standard autoencoders typically fail. Since the decoupled activation function acts like an implicit regularizer, the model can be trained by minimizing the reconstruction error of training data, without requiring any additional regularization.
EmoNets: Multimodal deep learning approaches for emotion recognition in video
Mar 30, 2015

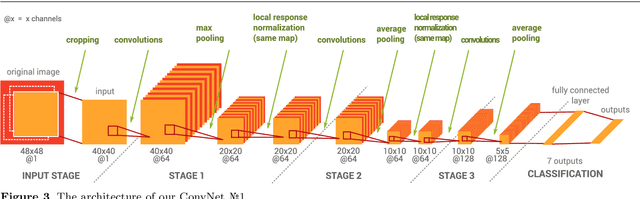
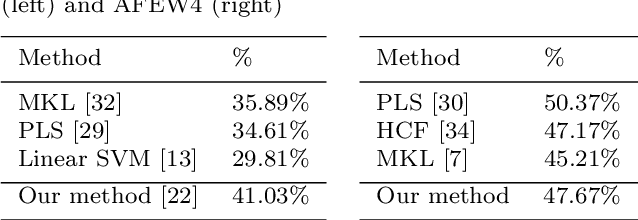
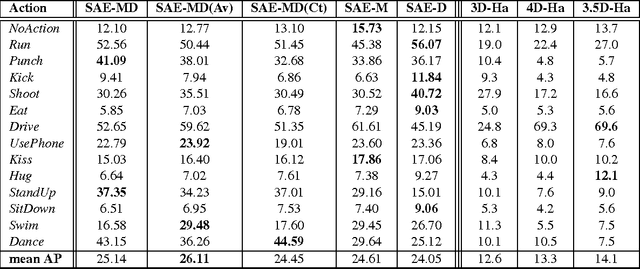
The task of the emotion recognition in the wild (EmotiW) Challenge is to assign one of seven emotions to short video clips extracted from Hollywood style movies. The videos depict acted-out emotions under realistic conditions with a large degree of variation in attributes such as pose and illumination, making it worthwhile to explore approaches which consider combinations of features from multiple modalities for label assignment. In this paper we present our approach to learning several specialist models using deep learning techniques, each focusing on one modality. Among these are a convolutional neural network, focusing on capturing visual information in detected faces, a deep belief net focusing on the representation of the audio stream, a K-Means based "bag-of-mouths" model, which extracts visual features around the mouth region and a relational autoencoder, which addresses spatio-temporal aspects of videos. We explore multiple methods for the combination of cues from these modalities into one common classifier. This achieves a considerably greater accuracy than predictions from our strongest single-modality classifier. Our method was the winning submission in the 2013 EmotiW challenge and achieved a test set accuracy of 47.67% on the 2014 dataset.
Modeling sequential data using higher-order relational features and predictive training
Feb 10, 2014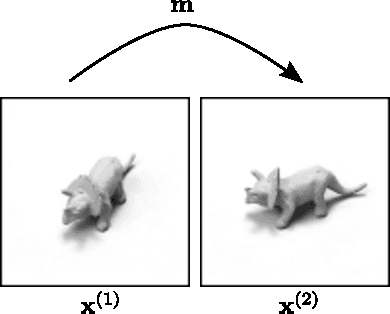

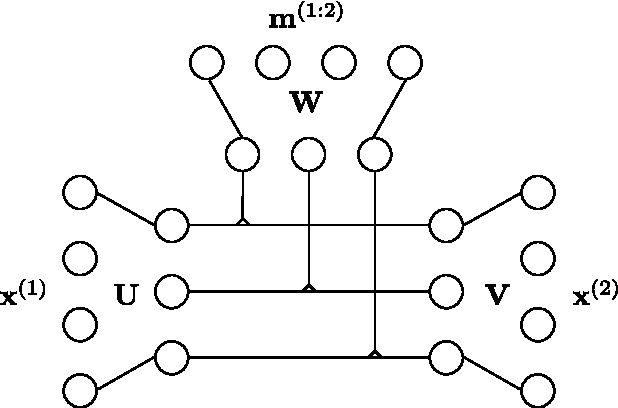
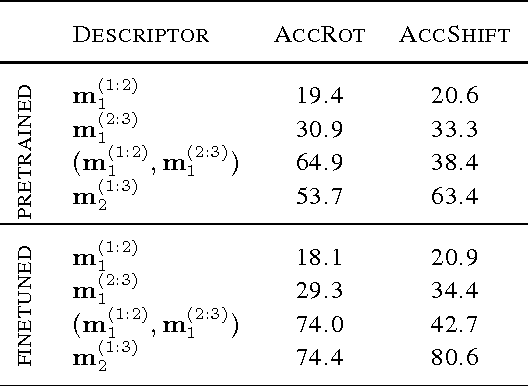
Bi-linear feature learning models, like the gated autoencoder, were proposed as a way to model relationships between frames in a video. By minimizing reconstruction error of one frame, given the previous frame, these models learn "mapping units" that encode the transformations inherent in a sequence, and thereby learn to encode motion. In this work we extend bi-linear models by introducing "higher-order mapping units" that allow us to encode transformations between frames and transformations between transformations. We show that this makes it possible to encode temporal structure that is more complex and longer-range than the structure captured within standard bi-linear models. We also show that a natural way to train the model is by replacing the commonly used reconstruction objective with a prediction objective which forces the model to correctly predict the evolution of the input multiple steps into the future. Learning can be achieved by back-propagating the multi-step prediction through time. We test the model on various temporal prediction tasks, and show that higher-order mappings and predictive training both yield a significant improvement over bi-linear models in terms of prediction accuracy.
Unsupervised learning of depth and motion
Dec 16, 2013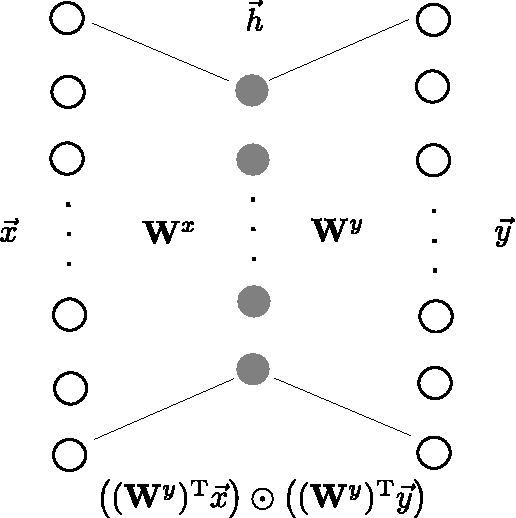

We present a model for the joint estimation of disparity and motion. The model is based on learning about the interrelations between images from multiple cameras, multiple frames in a video, or the combination of both. We show that learning depth and motion cues, as well as their combinations, from data is possible within a single type of architecture and a single type of learning algorithm, by using biologically inspired "complex cell" like units, which encode correlations between the pixels across image pairs. Our experimental results show that the learning of depth and motion makes it possible to achieve state-of-the-art performance in 3-D activity analysis, and to outperform existing hand-engineered 3-D motion features by a very large margin.