 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2022 Competition: Driving SMARTS
Nov 14, 2022

Driving SMARTS is a regular competition designed to tackle problems caused by the distribution shift in dynamic interaction contexts that are prevalent in real-world autonomous driving (AD). The proposed competition supports methodologically diverse solutions, such as reinforcement learning (RL) and offline learning methods, trained on a combination of naturalistic AD data and open-source simulation platform SMARTS. The two-track structure allows focusing on different aspects of the distribution shift. Track 1 is open to any method and will give ML researchers with different backgrounds an opportunity to solve a real-world autonomous driving challenge. Track 2 is designed for strictly offline learning methods. Therefore, direct comparisons can be made between different methods with the aim to identify new promising research directions. The proposed setup consists of 1) realistic traffic generated using real-world data and micro simulators to ensure fidelity of the scenarios, 2) framework accommodating diverse methods for solving the problem, and 3) baseline method. As such it provides a unique opportunity for the principled investigation into various aspects of autonomous vehicle deployment.
Uncertainty-Driven Active Vision for Implicit Scene Reconstruction
Oct 03, 2022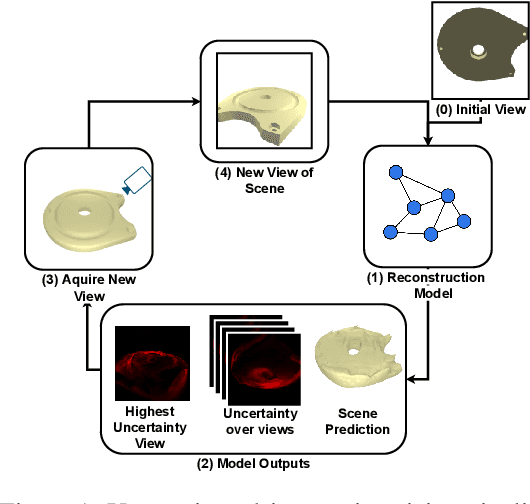
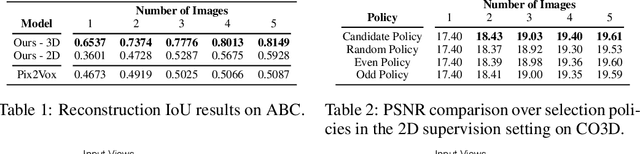
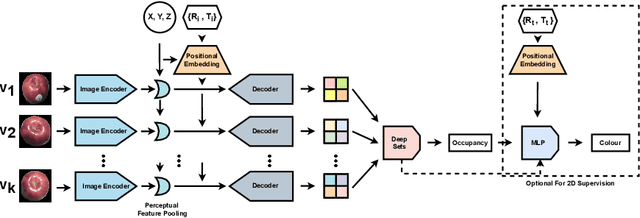

Multi-view implicit scene reconstruction methods have become increasingly popular due to their ability to represent complex scene details. Recent efforts have been devoted to improving the representation of input information and to reducing the number of views required to obtain high quality reconstructions. Yet, perhaps surprisingly, the study of which views to select to maximally improve scene understanding remains largely unexplored. We propose an uncertainty-driven active vision approach for implicit scene reconstruction, which leverages occupancy uncertainty accumulated across the scene using volume rendering to select the next view to acquire. To this end, we develop an occupancy-based reconstruction method which accurately represents scenes using either 2D or 3D supervision. We evaluate our proposed approach on the ABC dataset and the in the wild CO3D dataset, and show that: (1) we are able to obtain high quality state-of-the-art occupancy reconstructions; (2) our perspective conditioned uncertainty definition is effective to drive improvements in next best view selection and outperforms strong baseline approaches; and (3) we can further improve shape understanding by performing a gradient-based search on the view selection candidates. Overall, our results highlight the importance of view selection for implicit scene reconstruction, making it a promising avenue to explore further.
Bayesian Q-learning With Imperfect Expert Demonstrations
Oct 01, 2022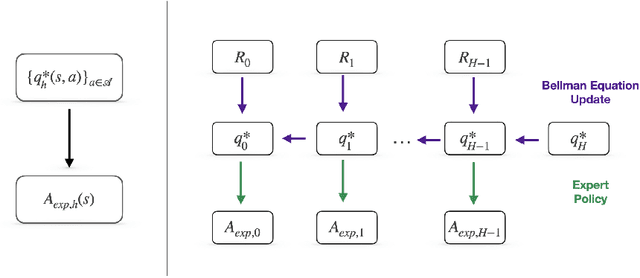
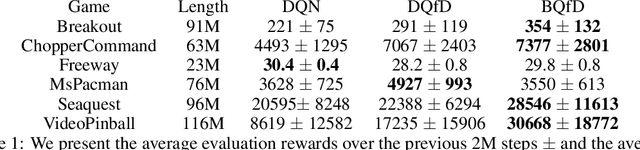
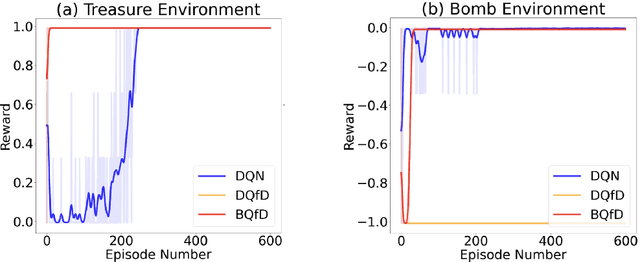

Guided exploration with expert demonstrations improves data efficiency for reinforcement learning, but current algorithms often overuse expert information. We propose a novel algorithm to speed up Q-learning with the help of a limited amount of imperfect expert demonstrations. The algorithm avoids excessive reliance on expert data by relaxing the optimal expert assumption and gradually reducing the usage of uninformative expert data. Experimentally, we evaluate our approach on a sparse-reward chain environment and six more complicated Atari games with delayed rewards. With the proposed methods, we can achieve better results than Deep Q-learning from Demonstrations (Hester et al., 2017) in most environments.
Continuous MDP Homomorphisms and Homomorphic Policy Gradient
Sep 15, 2022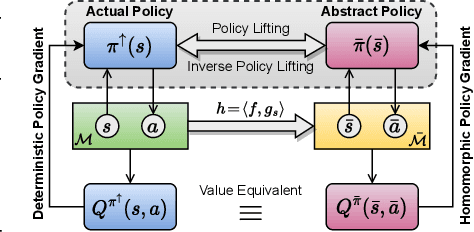
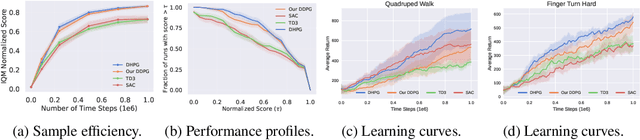
Abstraction has been widely studied as a way to improve the efficiency and generalization of reinforcement learning algorithms. In this paper, we study abstraction in the continuous-control setting. We extend the definition of MDP homomorphisms to encompass continuous actions in continuous state spaces. We derive a policy gradient theorem on the abstract MDP, which allows us to leverage approximate symmetries of the environment for policy optimization. Based on this theorem, we propose an actor-critic algorithm that is able to learn the policy and the MDP homomorphism map simultaneously, using the lax bisimulation metric. We demonstrate the effectiveness of our method on benchmark tasks in the DeepMind Control Suite. Our method's ability to utilize MDP homomorphisms for representation learning leads to improved performance when learning from pixel observations.
Distributional Hamilton-Jacobi-Bellman Equations for Continuous-Time Reinforcement Learning
May 24, 2022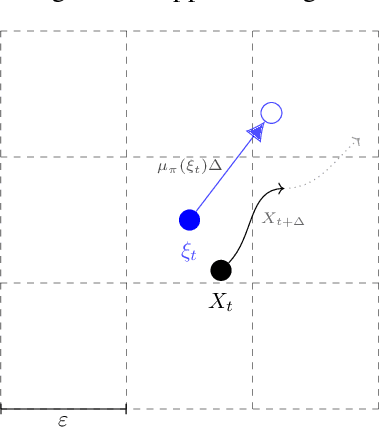
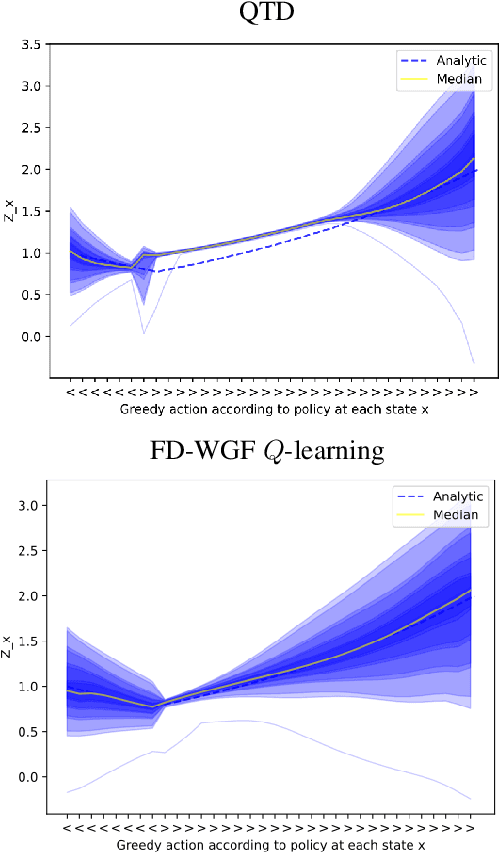
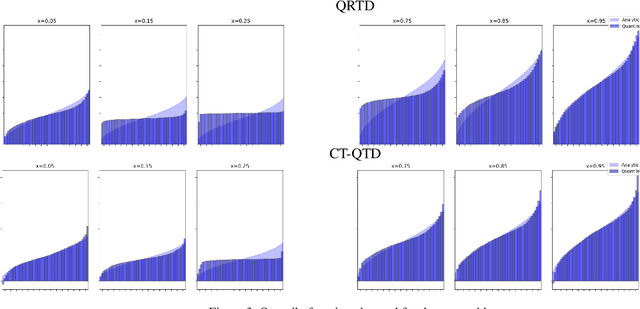
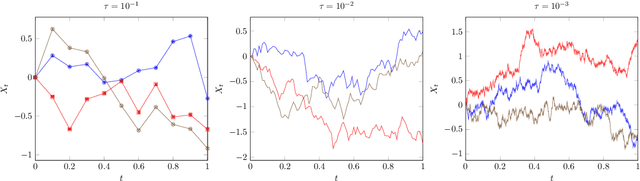
Continuous-time reinforcement learning offers an appealing formalism for describing control problems in which the passage of time is not naturally divided into discrete increments. Here we consider the problem of predicting the distribution of returns obtained by an agent interacting in a continuous-time, stochastic environment. Accurate return predictions have proven useful for determining optimal policies for risk-sensitive control, learning state representations, multiagent coordination, and more. We begin by establishing the distributional analogue of the Hamilton-Jacobi-Bellman (HJB) equation for It\^o diffusions and the broader class of Feller-Dynkin processes. We then specialize this equation to the setting in which the return distribution is approximated by $N$ uniformly-weighted particles, a common design choice in distributional algorithms. Our derivation highlights additional terms due to statistical diffusivity which arise from the proper handling of distributions in the continuous-time setting. Based on this, we propose a tractable algorithm for approximately solving the distributional HJB based on a JKO scheme, which can be implemented in an online control algorithm. We demonstrate the effectiveness of such an algorithm in a synthetic control problem.
IL-flOw: Imitation Learning from Observation using Normalizing Flows
May 19, 2022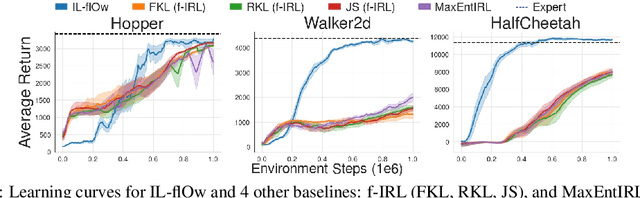
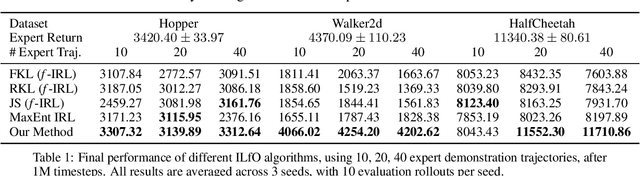
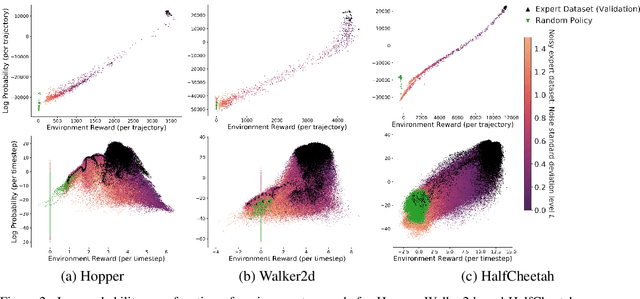
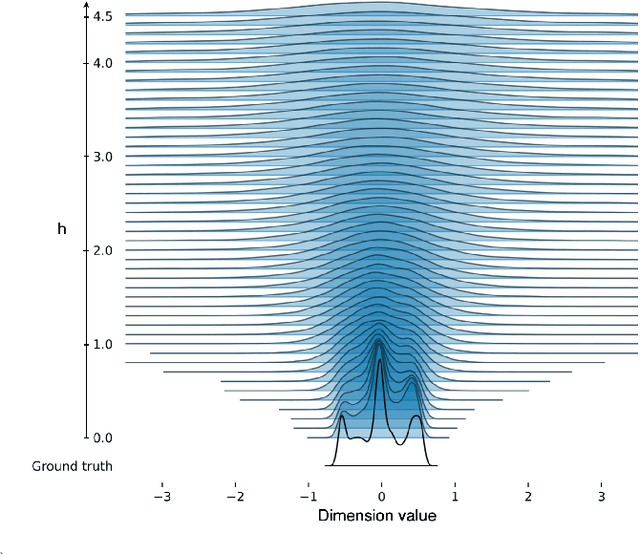
We present an algorithm for Inverse Reinforcement Learning (IRL) from expert state observations only. Our approach decouples reward modelling from policy learning, unlike state-of-the-art adversarial methods which require updating the reward model during policy search and are known to be unstable and difficult to optimize. Our method, IL-flOw, recovers the expert policy by modelling state-state transitions, by generating rewards using deep density estimators trained on the demonstration trajectories, avoiding the instability issues of adversarial methods. We demonstrate that using the state transition log-probability density as a reward signal for forward reinforcement learning translates to matching the trajectory distribution of the expert demonstrations, and experimentally show good recovery of the true reward signal as well as state of the art results for imitation from observation on locomotion and robotic continuous control tasks.
Why Should I Trust You, Bellman? The Bellman Error is a Poor Replacement for Value Error
Jan 28, 2022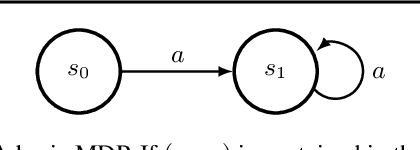
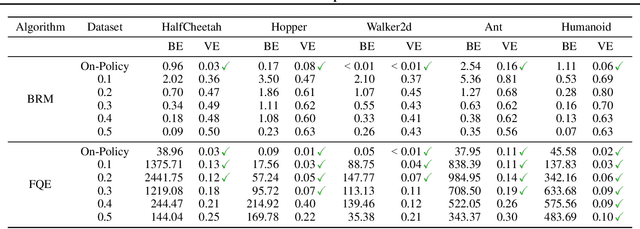
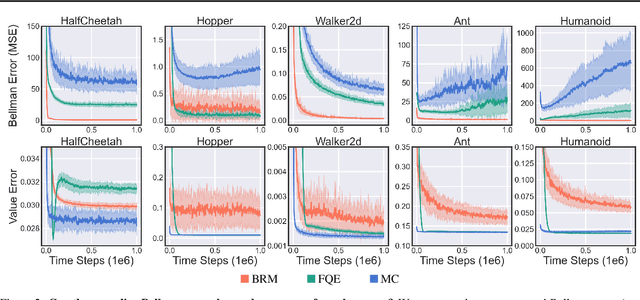
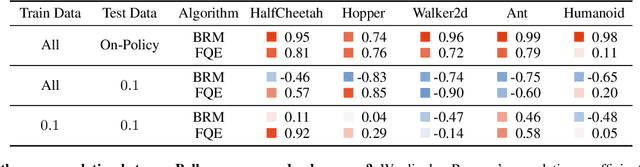
In this work, we study the use of the Bellman equation as a surrogate objective for value prediction accuracy. While the Bellman equation is uniquely solved by the true value function over all state-action pairs, we find that the Bellman error (the difference between both sides of the equation) is a poor proxy for the accuracy of the value function. In particular, we show that (1) due to cancellations from both sides of the Bellman equation, the magnitude of the Bellman error is only weakly related to the distance to the true value function, even when considering all state-action pairs, and (2) in the finite data regime, the Bellman equation can be satisfied exactly by infinitely many suboptimal solutions. This means that the Bellman error can be minimized without improving the accuracy of the value function. We demonstrate these phenomena through a series of propositions, illustrative toy examples, and empirical analysis in standard benchmark domains.
Trajectory-Constrained Deep Latent Visual Attention for Improved Local Planning in Presence of Heterogeneous Terrain
Dec 09, 2021
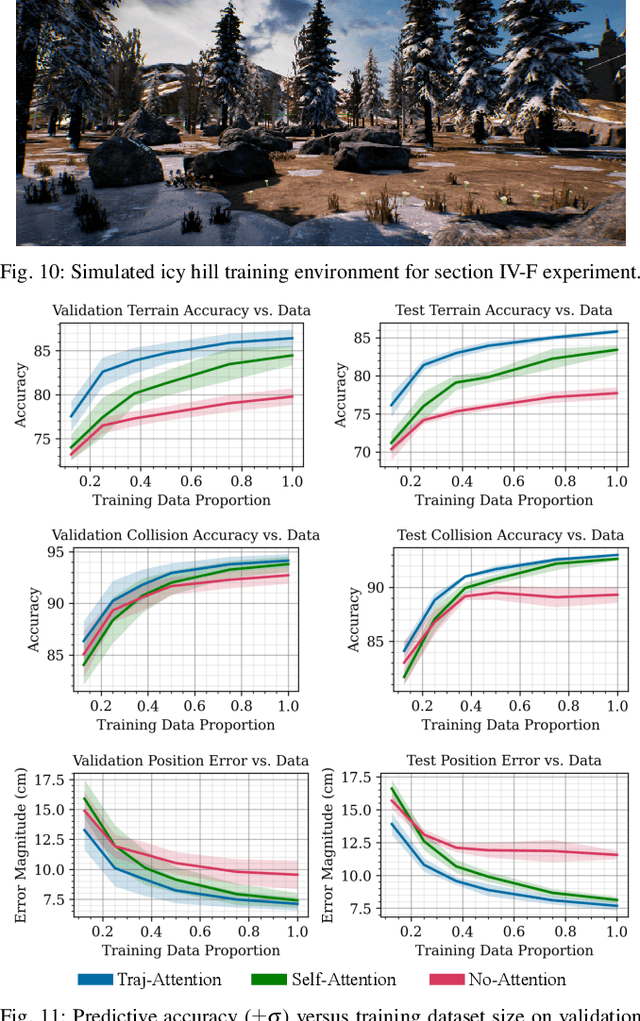
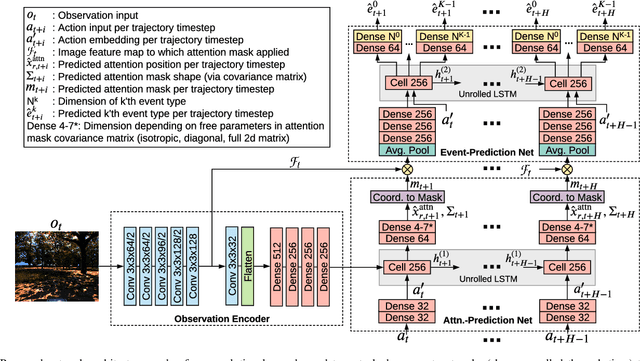

We present a reward-predictive, model-based deep learning method featuring trajectory-constrained visual attention for use in mapless, local visual navigation tasks. Our method learns to place visual attention at locations in latent image space which follow trajectories caused by vehicle control actions to enhance predictive accuracy during planning. The attention model is jointly optimized by the task-specific loss and an additional trajectory-constraint loss, allowing adaptability yet encouraging a regularized structure for improved generalization and reliability. Importantly, visual attention is applied in latent feature map space instead of raw image space to promote efficient planning. We validated our model in visual navigation tasks of planning low turbulence, collision-free trajectories in off-road settings and hill climbing with locking differentials in the presence of slippery terrain. Experiments involved randomized procedural generated simulation and real-world environments. We found our method improved generalization and learning efficiency when compared to no-attention and self-attention alternatives.
An Autonomous Probing System for Collecting Measurements at Depth from Small Surface Vehicles
Oct 27, 2021

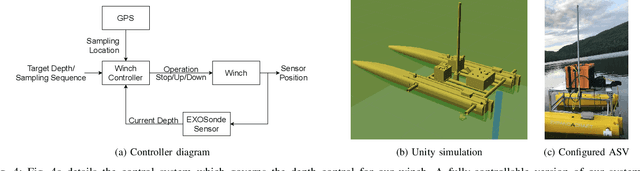
This paper presents the portable autonomous probing system (APS), a low-cost robotic design for collecting water quality measurements at targeted depths from an autonomous surface vehicle (ASV). This system fills an important but often overlooked niche in marine sampling by enabling mobile sensor observations throughout the near-surface water column without the need for advanced underwater equipment. We present a probe delivery mechanism built with commercially available components and describe the corresponding open-source simulator and winch controller. Finally, we demonstrate the system in a field deployment and discuss design trade-offs and areas for future improvement. Project details are available on https://johannah.github.io/publication/sample-at-depth our website
Active 3D Shape Reconstruction from Vision and Touch
Jul 20, 2021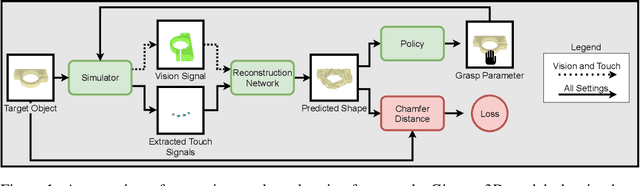
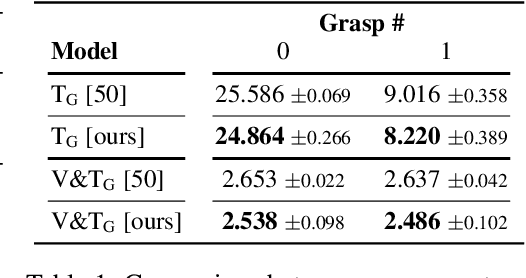
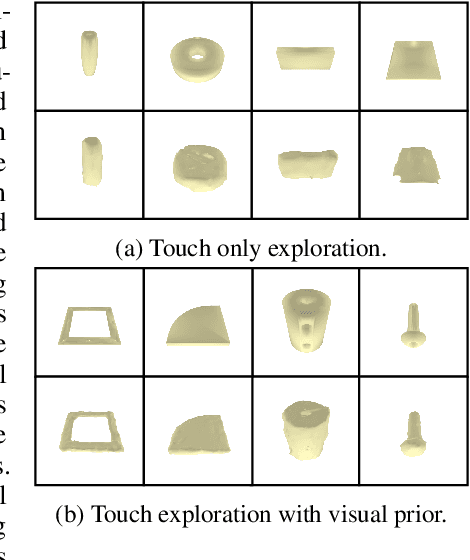
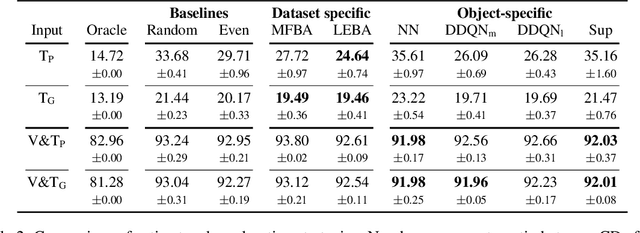
Humans build 3D understandings of the world through active object exploration, using jointly their senses of vision and touch. However, in 3D shape reconstruction, most recent progress has relied on static datasets of limited sensory data such as RGB images, depth maps or haptic readings, leaving the active exploration of the shape largely unexplored. In active touch sensing for 3D reconstruction, the goal is to actively select the tactile readings that maximize the improvement in shape reconstruction accuracy. However, the development of deep learning-based active touch models is largely limited by the lack of frameworks for shape exploration. In this paper, we focus on this problem and introduce a system composed of: 1) a haptic simulator leveraging high spatial resolution vision-based tactile sensors for active touching of 3D objects; 2) a mesh-based 3D shape reconstruction model that relies on tactile or visuotactile signals; and 3) a set of data-driven solutions with either tactile or visuotactile priors to guide the shape exploration. Our framework enables the development of the first fully data-driven solutions to active touch on top of learned models for object understanding. Our experiments show the benefits of such solutions in the task of 3D shape understanding where our models consistently outperform natural baselines. We provide our framework as a tool to foster future research in this direction.