 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the geometry and topology of representations: the manifolds of modular addition
Dec 31, 2025The Clock and Pizza interpretations, associated with architectures differing in either uniform or learnable attention, were introduced to argue that different architectural designs can yield distinct circuits for modular addition. In this work, we show that this is not the case, and that both uniform attention and trainable attention architectures implement the same algorithm via topologically and geometrically equivalent representations. Our methodology goes beyond the interpretation of individual neurons and weights. Instead, we identify all of the neurons corresponding to each learned representation and then study the collective group of neurons as one entity. This method reveals that each learned representation is a manifold that we can study utilizing tools from topology. Based on this insight, we can statistically analyze the learned representations across hundreds of circuits to demonstrate the similarity between learned modular addition circuits that arise naturally from common deep learning paradigms.
KerJEPA: Kernel Discrepancies for Euclidean Self-Supervised Learning
Dec 22, 2025Recent breakthroughs in self-supervised Joint-Embedding Predictive Architectures (JEPAs) have established that regularizing Euclidean representations toward isotropic Gaussian priors yields provable gains in training stability and downstream generalization. We introduce a new, flexible family of KerJEPAs, self-supervised learning algorithms with kernel-based regularizers. One instance of this family corresponds to the recently-introduced LeJEPA Epps-Pulley regularizer which approximates a sliced maximum mean discrepancy (MMD) with a Gaussian prior and Gaussian kernel. By expanding the class of viable kernels and priors and computing the closed-form high-dimensional limit of sliced MMDs, we develop alternative KerJEPAs with a number of favorable properties including improved training stability and design flexibility.
Tractable Representations for Convergent Approximation of Distributional HJB Equations
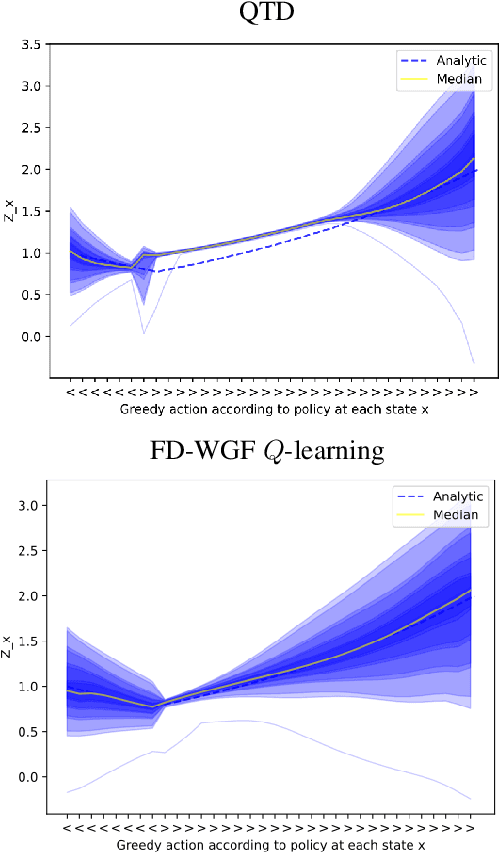
Mar 07, 2025In reinforcement learning (RL), the long-term behavior of decision-making policies is evaluated based on their average returns. Distributional RL has emerged, presenting techniques for learning return distributions, which provide additional statistics for evaluating policies, incorporating risk-sensitive considerations. When the passage of time cannot naturally be divided into discrete time increments, researchers have studied the continuous-time RL (CTRL) problem, where agent states and decisions evolve continuously. In this setting, the Hamilton-Jacobi-Bellman (HJB) equation is well established as the characterization of the expected return, and many solution methods exist. However, the study of distributional RL in the continuous-time setting is in its infancy. Recent work has established a distributional HJB (DHJB) equation, providing the first characterization of return distributions in CTRL. These equations and their solutions are intractable to solve and represent exactly, requiring novel approximation techniques. This work takes strides towards this end, establishing conditions on the method of parameterizing return distributions under which the DHJB equation can be approximately solved. Particularly, we show that under a certain topological property of the mapping between statistics learned by a distributional RL algorithm and corresponding distributions, approximation of these statistics leads to close approximations of the solution of the DHJB equation. Concretely, we demonstrate that the quantile representation common in distributional RL satisfies this topological property, certifying an efficient approximation algorithm for continuous-time distributional RL.
Non-Adversarial Inverse Reinforcement Learning via Successor Feature Matching
Nov 11, 2024



In inverse reinforcement learning (IRL), an agent seeks to replicate expert demonstrations through interactions with the environment. Traditionally, IRL is treated as an adversarial game, where an adversary searches over reward models, and a learner optimizes the reward through repeated RL procedures. This game-solving approach is both computationally expensive and difficult to stabilize. In this work, we propose a novel approach to IRL by direct policy optimization: exploiting a linear factorization of the return as the inner product of successor features and a reward vector, we design an IRL algorithm by policy gradient descent on the gap between the learner and expert features. Our non-adversarial method does not require learning a reward function and can be solved seamlessly with existing actor-critic RL algorithms. Remarkably, our approach works in state-only settings without expert action labels, a setting which behavior cloning (BC) cannot solve. Empirical results demonstrate that our method learns from as few as a single expert demonstration and achieves improved performance on various control tasks.
Action Gaps and Advantages in Continuous-Time Distributional Reinforcement Learning
Oct 14, 2024When decisions are made at high frequency, traditional reinforcement learning (RL) methods struggle to accurately estimate action values. In turn, their performance is inconsistent and often poor. Whether the performance of distributional RL (DRL) agents suffers similarly, however, is unknown. In this work, we establish that DRL agents are sensitive to the decision frequency. We prove that action-conditioned return distributions collapse to their underlying policy's return distribution as the decision frequency increases. We quantify the rate of collapse of these return distributions and exhibit that their statistics collapse at different rates. Moreover, we define distributional perspectives on action gaps and advantages. In particular, we introduce the superiority as a probabilistic generalization of the advantage -- the core object of approaches to mitigating performance issues in high-frequency value-based RL. In addition, we build a superiority-based DRL algorithm. Through simulations in an option-trading domain, we validate that proper modeling of the superiority distribution produces improved controllers at high decision frequencies.
Foundations of Multivariate Distributional Reinforcement Learning
Aug 31, 2024



In reinforcement learning (RL), the consideration of multivariate reward signals has led to fundamental advancements in multi-objective decision-making, transfer learning, and representation learning. This work introduces the first oracle-free and computationally-tractable algorithms for provably convergent multivariate distributional dynamic programming and temporal difference learning. Our convergence rates match the familiar rates in the scalar reward setting, and additionally provide new insights into the fidelity of approximate return distribution representations as a function of the reward dimension. Surprisingly, when the reward dimension is larger than $1$, we show that standard analysis of categorical TD learning fails, which we resolve with a novel projection onto the space of mass-$1$ signed measures. Finally, with the aid of our technical results and simulations, we identify tradeoffs between distribution representations that influence the performance of multivariate distributional RL in practice.
A Distributional Analogue to the Successor Representation
Feb 13, 2024



This paper contributes a new approach for distributional reinforcement learning which elucidates a clean separation of transition structure and reward in the learning process. Analogous to how the successor representation (SR) describes the expected consequences of behaving according to a given policy, our distributional successor measure (SM) describes the distributional consequences of this behaviour. We formulate the distributional SM as a distribution over distributions and provide theory connecting it with distributional and model-based reinforcement learning. Moreover, we propose an algorithm that learns the distributional SM from data by minimizing a two-level maximum mean discrepancy. Key to our method are a number of algorithmic techniques that are independently valuable for learning generative models of state. As an illustration of the usefulness of the distributional SM, we show that it enables zero-shot risk-sensitive policy evaluation in a way that was not previously possible.
Policy Optimization in a Noisy Neighborhood: On Return Landscapes in Continuous Control
Sep 26, 2023



Deep reinforcement learning agents for continuous control are known to exhibit significant instability in their performance over time. In this work, we provide a fresh perspective on these behaviors by studying the return landscape: the mapping between a policy and a return. We find that popular algorithms traverse noisy neighborhoods of this landscape, in which a single update to the policy parameters leads to a wide range of returns. By taking a distributional view of these returns, we map the landscape, characterizing failure-prone regions of policy space and revealing a hidden dimension of policy quality. We show that the landscape exhibits surprising structure by finding simple paths in parameter space which improve the stability of a policy. To conclude, we develop a distribution-aware procedure which finds such paths, navigating away from noisy neighborhoods in order to improve the robustness of a policy. Taken together, our results provide new insight into the optimization, evaluation, and design of agents.
Distributional Hamilton-Jacobi-Bellman Equations for Continuous-Time Reinforcement Learning
May 24, 2022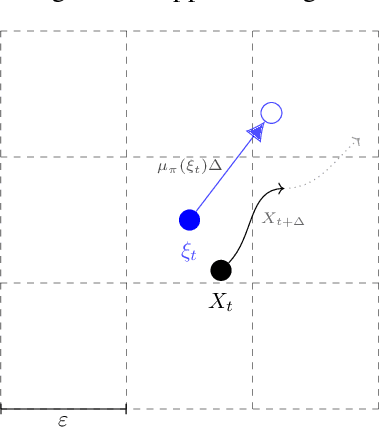
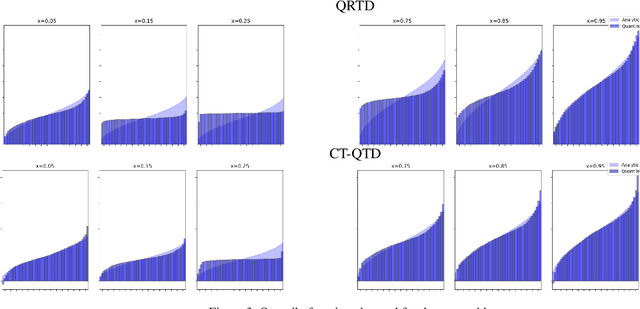
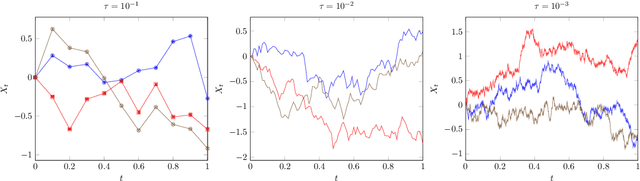
Continuous-time reinforcement learning offers an appealing formalism for describing control problems in which the passage of time is not naturally divided into discrete increments. Here we consider the problem of predicting the distribution of returns obtained by an agent interacting in a continuous-time, stochastic environment. Accurate return predictions have proven useful for determining optimal policies for risk-sensitive control, learning state representations, multiagent coordination, and more. We begin by establishing the distributional analogue of the Hamilton-Jacobi-Bellman (HJB) equation for It\^o diffusions and the broader class of Feller-Dynkin processes. We then specialize this equation to the setting in which the return distribution is approximated by $N$ uniformly-weighted particles, a common design choice in distributional algorithms. Our derivation highlights additional terms due to statistical diffusivity which arise from the proper handling of distributions in the continuous-time setting. Based on this, we propose a tractable algorithm for approximately solving the distributional HJB based on a JKO scheme, which can be implemented in an online control algorithm. We demonstrate the effectiveness of such an algorithm in a synthetic control problem.