 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneric Temporal Reasoning with Differential Analysis and Explanation
Dec 20, 2022



Temporal reasoning is the task of predicting temporal relations of event pairs with corresponding contexts. While some temporal reasoning models perform reasonably well on in-domain benchmarks, we have little idea of the systems' generalizability due to existing datasets' limitations. In this work, we introduce a novel task named TODAY that bridges this gap with temporal differential analysis, which as the name suggests, evaluates if systems can correctly understand the effect of incremental changes. Specifically, TODAY makes slight context changes for given event pairs, and systems need to tell how this subtle contextual change will affect temporal relation distributions. To facilitate learning, TODAY also annotates human explanations. We show that existing models, including GPT-3, drop to random guessing on TODAY, suggesting that they heavily rely on spurious information rather than proper reasoning for temporal predictions. On the other hand, we show that TODAY's supervision style and explanation annotations can be used in joint learning and encourage models to use more appropriate signals during training and outperform across several benchmarks. TODAY can also be used to train models to solicit incidental supervision from noisy sources such as GPT-3 and moves farther towards generic temporal reasoning systems.
Dialog2API: Task-Oriented Dialogue with API Description and Example Programs
Dec 20, 2022



Functionality and dialogue experience are two important factors of task-oriented dialogue systems. Conventional approaches with closed schema (e.g., conversational semantic parsing) often fail as both the functionality and dialogue experience are strongly constrained by the underlying schema. We introduce a new paradigm for task-oriented dialogue - Dialog2API - to greatly expand the functionality and provide seamless dialogue experience. The conversational model interacts with the environment by generating and executing programs triggering a set of pre-defined APIs. The model also manages the dialogue policy and interact with the user through generating appropriate natural language responses. By allowing generating free-form programs, Dialog2API supports composite goals by combining different APIs, whereas unrestricted program revision provides natural and robust dialogue experience. To facilitate Dialog2API, the core model is provided with API documents, an execution environment and optionally some example dialogues annotated with programs. We propose an approach tailored for the Dialog2API, where the dialogue states are represented by a stack of programs, with most recently mentioned program on the top of the stack. Dialog2API can work with many application scenarios such as software automation and customer service. In this paper, we construct a dataset for AWS S3 APIs and present evaluation results of in-context learning baselines.
Privacy Adhering Machine Un-learning in NLP
Dec 19, 2022



Regulations introduced by General Data Protection Regulation (GDPR) in the EU or California Consumer Privacy Act (CCPA) in the US have included provisions on the \textit{right to be forgotten} that mandates industry applications to remove data related to an individual from their systems. In several real world industry applications that use Machine Learning to build models on user data, such mandates require significant effort both in terms of data cleansing as well as model retraining while ensuring the models do not deteriorate in prediction quality due to removal of data. As a result, continuous removal of data and model retraining steps do not scale if these applications receive such requests at a very high frequency. Recently, a few researchers proposed the idea of \textit{Machine Unlearning} to tackle this challenge. Despite the significant importance of this task, the area of Machine Unlearning is under-explored in Natural Language Processing (NLP) tasks. In this paper, we explore the Unlearning framework on various GLUE tasks \cite{Wang:18}, such as, QQP, SST and MNLI. We propose computationally efficient approaches (SISA-FC and SISA-A) to perform \textit{guaranteed} Unlearning that provides significant reduction in terms of both memory (90-95\%), time (100x) and space consumption (99\%) in comparison to the baselines while keeping model performance constant.
Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale
Dec 18, 2022



Language models have been shown to perform better with an increase in scale on a wide variety of tasks via the in-context learning paradigm. In this paper, we investigate the hypothesis that the ability of a large language model to in-context learn-perform a task is not uniformly spread across all of its underlying components. Using a 66 billion parameter language model (OPT-66B) across a diverse set of 14 downstream tasks, we find this is indeed the case: $\sim$70% of attention heads and $\sim$20% of feed forward networks can be removed with minimal decline in task performance. We find substantial overlap in the set of attention heads (un)important for in-context learning across tasks and number of in-context examples. We also address our hypothesis through a task-agnostic lens, finding that a small set of attention heads in OPT-66B score highly on their ability to perform primitive induction operations associated with in-context learning, namely, prefix matching and copying. These induction heads overlap with task-specific important heads, suggesting that induction heads are among the heads capable of more sophisticated behaviors associated with in-context learning. Overall, our study provides several insights that indicate large language models may be under-trained to perform in-context learning and opens up questions on how to pre-train language models to more effectively perform in-context learning.
LawngNLI: A Long-Premise Benchmark for In-Domain Generalization from Short to Long Contexts and for Implication-Based Retrieval
Dec 06, 2022



Natural language inference has trended toward studying contexts beyond the sentence level. An important application area is law: past cases often do not foretell how they apply to new situations and implications must be inferred. This paper introduces LawngNLI, constructed from U.S. legal opinions with automatic labels with high human-validated accuracy. Premises are long and multigranular. Experiments show two use cases. First, LawngNLI can benchmark for in-domain generalization from short to long contexts. It has remained unclear if large-scale long-premise NLI datasets actually need to be constructed: near-top performance on long premises could be achievable by fine-tuning using short premises. Without multigranularity, benchmarks cannot distinguish lack of fine-tuning on long premises versus domain shift between short and long datasets. In contrast, our long and short premises share the same examples and domain. Models fine-tuned using several past NLI datasets and/or our short premises fall short of top performance on our long premises. So for at least certain domains (such as ours), large-scale long-premise datasets are needed. Second, LawngNLI can benchmark for implication-based retrieval. Queries are entailed or contradicted by target documents, allowing users to move between arguments and evidence. Leading retrieval models perform reasonably zero shot on a LawngNLI-derived retrieval task. We compare different systems for re-ranking, including lexical overlap and cross-encoders fine-tuned using a modified LawngNLI or past NLI datasets. LawngNLI can train and test systems for implication-based case retrieval and argumentation.
Investigating Fairness Disparities in Peer Review: A Language Model Enhanced Approach
Nov 07, 2022Double-blind peer review mechanism has become the skeleton of academic research across multiple disciplines including computer science, yet several studies have questioned the quality of peer reviews and raised concerns on potential biases in the process. In this paper, we conduct a thorough and rigorous study on fairness disparities in peer review with the help of large language models (LMs). We collect, assemble, and maintain a comprehensive relational database for the International Conference on Learning Representations (ICLR) conference from 2017 to date by aggregating data from OpenReview, Google Scholar, arXiv, and CSRanking, and extracting high-level features using language models. We postulate and study fairness disparities on multiple protective attributes of interest, including author gender, geography, author, and institutional prestige. We observe that the level of disparity differs and textual features are essential in reducing biases in the predictive modeling. We distill several insights from our analysis on study the peer review process with the help of large LMs. Our database also provides avenues for studying new natural language processing (NLP) methods that facilitate the understanding of the peer review mechanism. We study a concrete example towards automatic machine review systems and provide baseline models for the review generation and scoring tasks such that the database can be used as a benchmark.
Learning to Decompose: Hypothetical Question Decomposition Based on Comparable Texts
Oct 30, 2022Explicit decomposition modeling, which involves breaking down complex tasks into more straightforward and often more interpretable sub-tasks, has long been a central theme in developing robust and interpretable NLU systems. However, despite the many datasets and resources built as part of this effort, the majority have small-scale annotations and limited scope, which is insufficient to solve general decomposition tasks. In this paper, we look at large-scale intermediate pre-training of decomposition-based transformers using distant supervision from comparable texts, particularly large-scale parallel news. We show that with such intermediate pre-training, developing robust decomposition-based models for a diverse range of tasks becomes more feasible. For example, on semantic parsing, our model, DecompT5, improves 20% to 30% on two datasets, Overnight and TORQUE, over the baseline language model. We further use DecompT5 to build a novel decomposition-based QA system named DecompEntail, improving over state-of-the-art models, including GPT-3, on both HotpotQA and StrategyQA by 8% and 4%, respectively.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022



We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
On the Limitations of Reference-Free Evaluations of Generated Text
Oct 22, 2022There is significant interest in developing evaluation metrics which accurately estimate the quality of generated text without the aid of a human-written reference text, which can be time consuming and expensive to collect or entirely unavailable in online applications. However, in this work, we demonstrate that these reference-free metrics are inherently biased and limited in their ability to evaluate generated text, and we argue that they should not be used to measure progress on tasks like machine translation or summarization. We show how reference-free metrics are equivalent to using one generation model to evaluate another, which has several limitations: (1) the metrics can be optimized at test time to find the approximate best-possible output, (2) they are inherently biased toward models which are more similar to their own, and (3) they can be biased against higher-quality outputs, including those written by humans. Therefore, we recommend that reference-free metrics should be used as diagnostic tools for analyzing and understanding model behavior instead of measures of how well models perform a task, in which the goal is to achieve as high of a score as possible.
Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis
Oct 12, 2022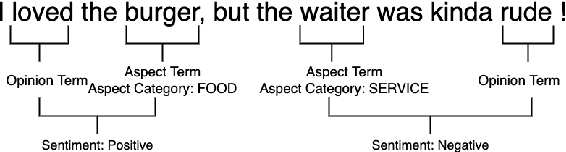
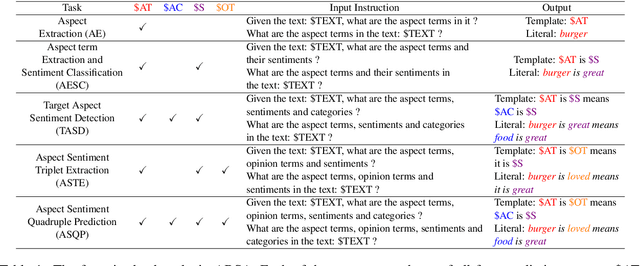
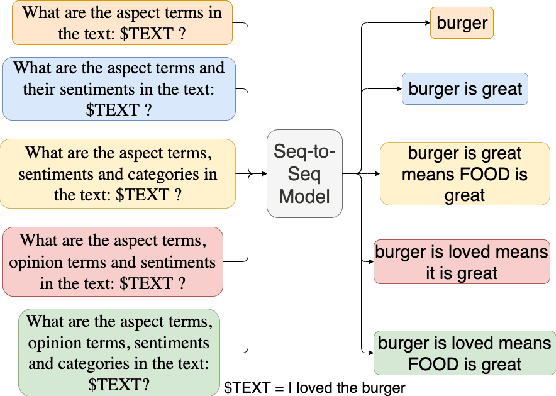
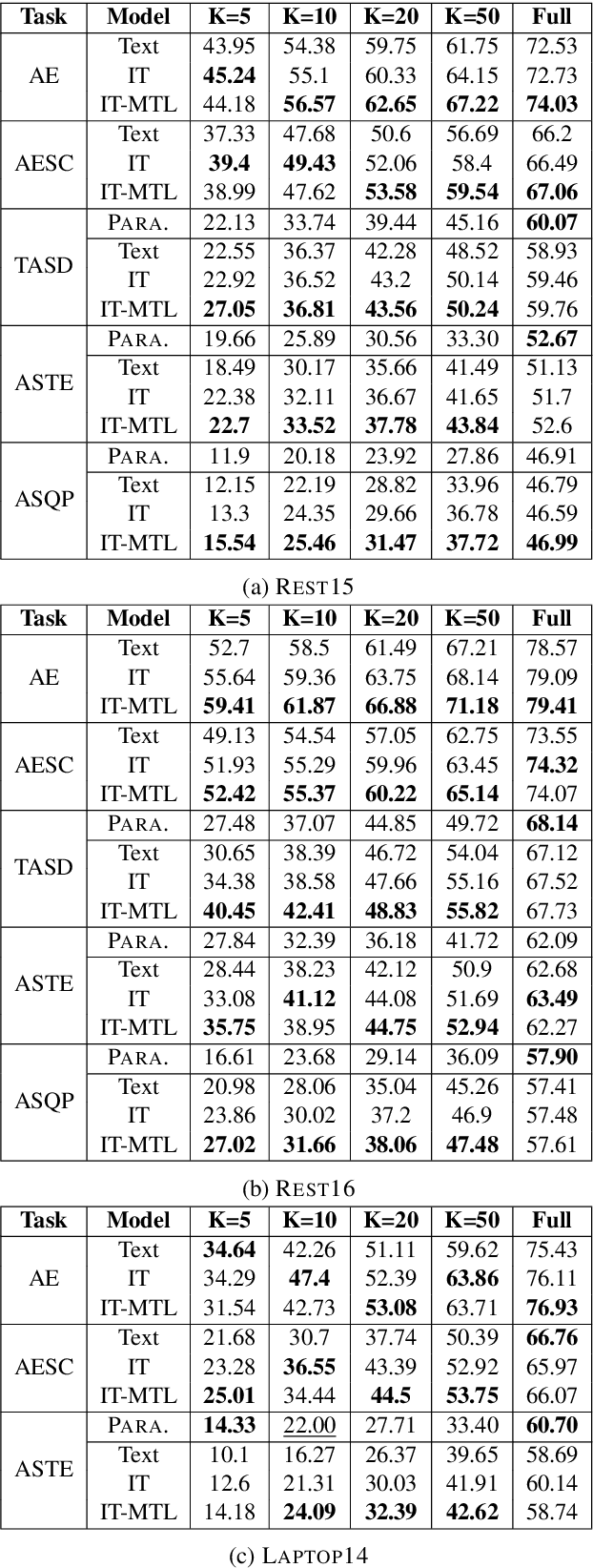
Aspect-based Sentiment Analysis (ABSA) is a fine-grained sentiment analysis task which involves four elements from user-generated texts: aspect term, aspect category, opinion term, and sentiment polarity. Most computational approaches focus on some of the ABSA sub-tasks such as tuple (aspect term, sentiment polarity) or triplet (aspect term, opinion term, sentiment polarity) extraction using either pipeline or joint modeling approaches. Recently, generative approaches have been proposed to extract all four elements as (one or more) quadruplets from text as a single task. In this work, we take a step further and propose a unified framework for solving ABSA, and the associated sub-tasks to improve the performance in few-shot scenarios. To this end, we fine-tune a T5 model with instructional prompts in a multi-task learning fashion covering all the sub-tasks, as well as the entire quadruple prediction task. In experiments with multiple benchmark data sets, we show that the proposed multi-task prompting approach brings performance boost (by absolute $6.75$ F1) in the few-shot learning setting.