 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAAKT: Enhancing Knowledge Tracing with Alternate Autoregressive Modeling
Feb 17, 2025



Knowledge Tracing (KT) aims to predict students' future performances based on their former exercises and additional information in educational settings. KT has received significant attention since it facilitates personalized experiences in educational situations. Simultaneously, the autoregressive modeling on the sequence of former exercises has been proven effective for this task. One of the primary challenges in autoregressive modeling for Knowledge Tracing is effectively representing the anterior (pre-response) and posterior (post-response) states of learners across exercises. Existing methods often employ complex model architectures to update learner states using question and response records. In this study, we propose a novel perspective on knowledge tracing task by treating it as a generative process, consistent with the principles of autoregressive models. We demonstrate that knowledge states can be directly represented through autoregressive encodings on a question-response alternate sequence, where model generate the most probable representation in hidden state space by analyzing history interactions. This approach underpins our framework, termed Alternate Autoregressive Knowledge Tracing (AAKT). Additionally, we incorporate supplementary educational information, such as question-related skills, into our framework through an auxiliary task, and include extra exercise details, like response time, as additional inputs. Our proposed framework is implemented using advanced autoregressive technologies from Natural Language Generation (NLG) for both training and prediction. Empirical evaluations on four real-world KT datasets indicate that AAKT consistently outperforms all baseline models in terms of AUC, ACC, and RMSE. Furthermore, extensive ablation studies and visualized analysis validate the effectiveness of key components in AAKT.
Horizon-Length Prediction: Advancing Fill-in-the-Middle Capabilities for Code Generation with Lookahead Planning
Oct 04, 2024Fill-in-the-Middle (FIM) has become integral to code language models, enabling generation of missing code given both left and right contexts. However, the current FIM training paradigm, which reorders original training sequences and then performs regular next-token prediction (NTP), often leads to models struggling to generate content that aligns smoothly with the surrounding context. Crucially, while existing works rely on rule-based post-processing to circumvent this weakness, such methods are not practically usable in open-domain code completion tasks as they depend on restrictive, dataset-specific assumptions (e.g., generating the same number of lines as in the ground truth). Moreover, model performance on FIM tasks deteriorates significantly without these unrealistic assumptions. We hypothesize that NTP alone is insufficient for models to learn effective planning conditioned on the distant right context, a critical factor for successful code infilling. To overcome this, we propose Horizon-Length Prediction (HLP), a novel training objective that teaches models to predict the number of remaining middle tokens (i.e., horizon length) at each step. HLP advances FIM with lookahead planning, enabling models to inherently learn infilling boundaries for arbitrary left and right contexts without relying on dataset-specific post-processing. Our evaluation across different models and sizes shows that HLP significantly improves FIM performance by up to 24% relatively on diverse benchmarks, across file-level and repository-level, and without resorting to unrealistic post-processing methods. Furthermore, the enhanced planning capability gained through HLP boosts model performance on code reasoning. Importantly, HLP only incurs negligible training overhead and no additional inference cost, ensuring its practicality for real-world scenarios.
Accelerating Full Waveform Inversion By Transfer Learning
Aug 01, 2024



Full waveform inversion (FWI) is a powerful tool for reconstructing material fields based on sparsely measured data obtained by wave propagation. For specific problems, discretizing the material field with a neural network (NN) improves the robustness and reconstruction quality of the corresponding optimization problem. We call this method NN-based FWI. Starting from an initial guess, the weights of the NN are iteratively updated to fit the simulated wave signals to the sparsely measured data set. For gradient-based optimization, a suitable choice of the initial guess, i.e., a suitable NN weight initialization, is crucial for fast and robust convergence. In this paper, we introduce a novel transfer learning approach to further improve NN-based FWI. This approach leverages supervised pretraining to provide a better NN weight initialization, leading to faster convergence of the subsequent optimization problem. Moreover, the inversions yield physically more meaningful local minima. The network is pretrained to predict the unknown material field using the gradient information from the first iteration of conventional FWI. In our computational experiments on two-dimensional domains, the training data set consists of reference simulations with arbitrarily positioned elliptical voids of different shapes and orientations. We compare the performance of the proposed transfer learning NN-based FWI with three other methods: conventional FWI, NN-based FWI without pretraining and conventional FWI with an initial guess predicted from the pretrained NN. Our results show that transfer learning NN-based FWI outperforms the other methods in terms of convergence speed and reconstruction quality.
Bifurcated Attention for Single-Context Large-Batch Sampling
Mar 13, 2024In our study, we present bifurcated attention, a method developed for language model inference in single-context batch sampling contexts. This approach aims to reduce redundant memory IO costs, a significant factor in latency for high batch sizes and long context lengths. Bifurcated attention achieves this by dividing the attention mechanism during incremental decoding into two distinct GEMM operations, focusing on the KV cache from prefill and the decoding process. This method ensures precise computation and maintains the usual computational load (FLOPs) of standard attention mechanisms, but with reduced memory IO. Bifurcated attention is also compatible with multi-query attention mechanism known for reduced memory IO for KV cache, further enabling higher batch size and context length. The resulting efficiency leads to lower latency, improving suitability for real-time applications, e.g., enabling massively-parallel answer generation without substantially increasing latency, enhancing performance when integrated with postprocessing techniques such as reranking.
Elastic Multi-Gradient Descent for Parallel Continual Learning
Jan 02, 2024



The goal of Continual Learning (CL) is to continuously learn from new data streams and accomplish the corresponding tasks. Previously studied CL assumes that data are given in sequence nose-to-tail for different tasks, thus indeed belonging to Serial Continual Learning (SCL). This paper studies the novel paradigm of Parallel Continual Learning (PCL) in dynamic multi-task scenarios, where a diverse set of tasks is encountered at different time points. PCL presents challenges due to the training of an unspecified number of tasks with varying learning progress, leading to the difficulty of guaranteeing effective model updates for all encountered tasks. In our previous conference work, we focused on measuring and reducing the discrepancy among gradients in a multi-objective optimization problem, which, however, may still contain negative transfers in every model update. To address this issue, in the dynamic multi-objective optimization problem, we introduce task-specific elastic factors to adjust the descent direction towards the Pareto front. The proposed method, called Elastic Multi-Gradient Descent (EMGD), ensures that each update follows an appropriate Pareto descent direction, minimizing any negative impact on previously learned tasks. To balance the training between old and new tasks, we also propose a memory editing mechanism guided by the gradient computed using EMGD. This editing process updates the stored data points, reducing interference in the Pareto descent direction from previous tasks. Experiments on public datasets validate the effectiveness of our EMGD in the PCL setting.
Exploring Continual Learning for Code Generation Models
Jul 05, 2023



Large-scale code generation models such as Codex and CodeT5 have achieved impressive performance. However, libraries are upgraded or deprecated very frequently and re-training large-scale language models is computationally expensive. Therefore, Continual Learning (CL) is an important aspect that remains underexplored in the code domain. In this paper, we introduce a benchmark called CodeTask-CL that covers a wide range of tasks, including code generation, translation, summarization, and refinement, with different input and output programming languages. Next, on our CodeTask-CL benchmark, we compare popular CL techniques from NLP and Vision domains. We find that effective methods like Prompt Pooling (PP) suffer from catastrophic forgetting due to the unstable training of the prompt selection mechanism caused by stark distribution shifts in coding tasks. We address this issue with our proposed method, Prompt Pooling with Teacher Forcing (PP-TF), that stabilizes training by enforcing constraints on the prompt selection mechanism and leads to a 21.54% improvement over Prompt Pooling. Along with the benchmark, we establish a training pipeline that can be used for CL on code models, which we believe can motivate further development of CL methods for code models. Our code is available at https://github.com/amazon-science/codetaskcl-pptf
Sampling weights of deep neural networks
Jun 29, 2023



We introduce a probability distribution, combined with an efficient sampling algorithm, for weights and biases of fully-connected neural networks. In a supervised learning context, no iterative optimization or gradient computations of internal network parameters are needed to obtain a trained network. The sampling is based on the idea of random feature models. However, instead of a data-agnostic distribution, e.g., a normal distribution, we use both the input and the output training data of the supervised learning problem to sample both shallow and deep networks. We prove that the sampled networks we construct are universal approximators. We also show that our sampling scheme is invariant to rigid body transformations and scaling of the input data. This implies many popular pre-processing techniques are no longer required. For Barron functions, we show that the $L^2$-approximation error of sampled shallow networks decreases with the square root of the number of neurons. In numerical experiments, we demonstrate that sampled networks achieve comparable accuracy as iteratively trained ones, but can be constructed orders of magnitude faster. Our test cases involve a classification benchmark from OpenML, sampling of neural operators to represent maps in function spaces, and transfer learning using well-known architectures.
Greener yet Powerful: Taming Large Code Generation Models with Quantization
Mar 09, 2023



ML-powered code generation aims to assist developers to write code in a more productive manner, by intelligently generating code blocks based on natural language prompts. Recently, large pretrained deep learning models have substantially pushed the boundary of code generation and achieved impressive performance. Despite their great power, the huge number of model parameters poses a significant threat to adapting them in a regular software development environment, where a developer might use a standard laptop or mid-size server to develop her code. Such large models incur significant resource usage (in terms of memory, latency, and dollars) as well as carbon footprint. Model compression is a promising approach to address these challenges. Several techniques are proposed to compress large pretrained models typically used for vision or textual data. Out of many available compression techniques, we identified that quantization is mostly applicable for code generation task as it does not require significant retraining cost. As quantization represents model parameters with lower-bit integer (e.g., int8), the model size and runtime latency would both benefit from such int representation. We extensively study the impact of quantized model on code generation tasks across different dimension: (i) resource usage and carbon footprint, (ii) accuracy, and (iii) robustness. To this end, through systematic experiments we find a recipe of quantization technique that could run even a $6$B model in a regular laptop without significant accuracy or robustness degradation. We further found the recipe is readily applicable to code summarization task as well.
Multi-lingual Evaluation of Code Generation Models
Oct 26, 2022



We present MBXP, an execution-based code completion benchmark in 10+ programming languages. This collection of datasets is generated by our conversion framework that translates prompts and test cases from the original MBPP dataset to the corresponding data in a target language. Based on this benchmark, we are able to evaluate code generation models in a multi-lingual fashion, and in particular discover generalization ability of language models on out-of-domain languages, advantages of large multi-lingual models over mono-lingual, benefits of few-shot prompting, and zero-shot translation abilities. In addition, we use our code generation model to perform large-scale bootstrapping to obtain synthetic canonical solutions in several languages. These solutions can be used for other code-related evaluations such as insertion-based, summarization, or code translation tasks where we demonstrate results and release as part of our benchmark.
Exploring Example Influence in Continual Learning
Sep 25, 2022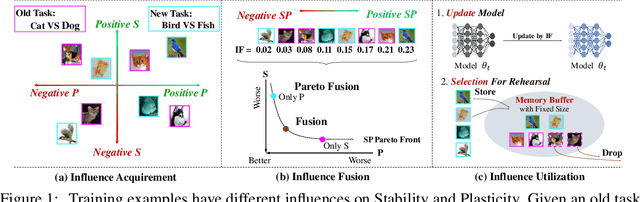
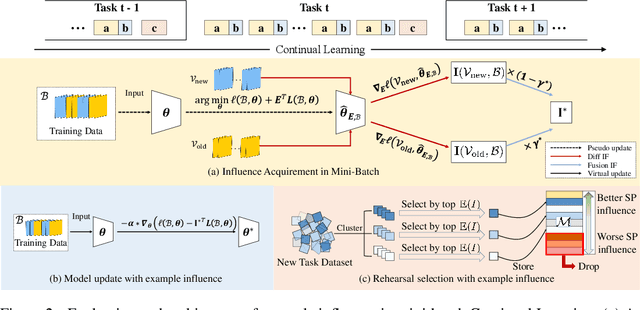
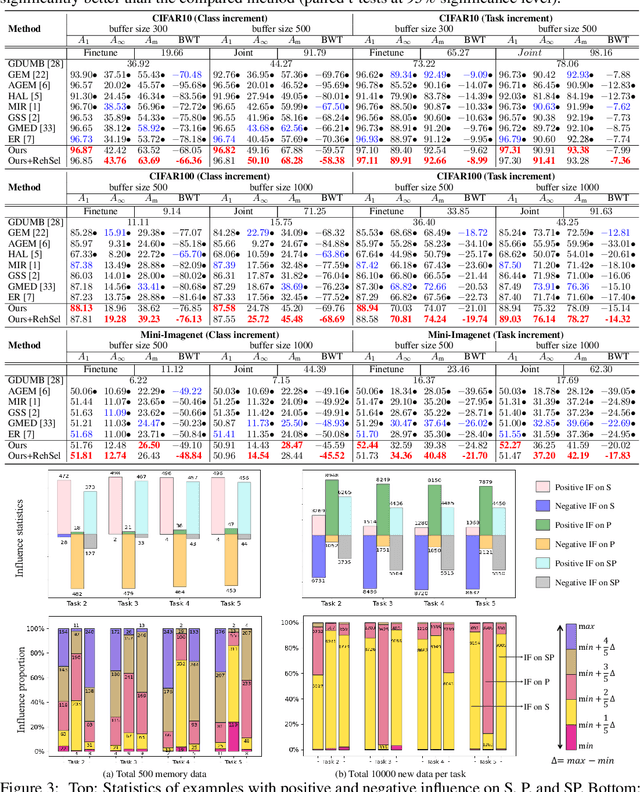
Continual Learning (CL) sequentially learns new tasks like human beings, with the goal to achieve better Stability (S, remembering past tasks) and Plasticity (P, adapting to new tasks). Due to the fact that past training data is not available, it is valuable to explore the influence difference on S and P among training examples, which may improve the learning pattern towards better SP. Inspired by Influence Function (IF), we first study example influence via adding perturbation to example weight and computing the influence derivation. To avoid the storage and calculation burden of Hessian inverse in neural networks, we propose a simple yet effective MetaSP algorithm to simulate the two key steps in the computation of IF and obtain the S- and P-aware example influence. Moreover, we propose to fuse two kinds of example influence by solving a dual-objective optimization problem, and obtain a fused influence towards SP Pareto optimality. The fused influence can be used to control the update of model and optimize the storage of rehearsal. Empirical results show that our algorithm significantly outperforms state-of-the-art methods on both task- and class-incremental benchmark CL datasets.