 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-FIX: Text-Based Explanations with Features Interpretable to eXperts
Nov 06, 2025As LLMs are deployed in knowledge-intensive settings (e.g., surgery, astronomy, therapy), users expect not just answers, but also meaningful explanations for those answers. In these settings, users are often domain experts (e.g., doctors, astrophysicists, psychologists) who require explanations that reflect expert-level reasoning. However, current evaluation schemes primarily emphasize plausibility or internal faithfulness of the explanation, which fail to capture whether the content of the explanation truly aligns with expert intuition. We formalize expert alignment as a criterion for evaluating explanations with T-FIX, a benchmark spanning seven knowledge-intensive domains. In collaboration with domain experts, we develop novel metrics to measure the alignment of LLM explanations with expert judgment.
Probabilistic Stability Guarantees for Feature Attributions
Apr 18, 2025Stability guarantees are an emerging tool for evaluating feature attributions, but existing certification methods rely on smoothed classifiers and often yield conservative guarantees. To address these limitations, we introduce soft stability and propose a simple, model-agnostic, and sample-efficient stability certification algorithm (SCA) that provides non-trivial and interpretable guarantees for any attribution. Moreover, we show that mild smoothing enables a graceful tradeoff between accuracy and stability, in contrast to prior certification methods that require a more aggressive compromise. Using Boolean function analysis, we give a novel characterization of stability under smoothing. We evaluate SCA on vision and language tasks, and demonstrate the effectiveness of soft stability in measuring the robustness of explanation methods.
Adaptively evaluating models with task elicitation
Mar 03, 2025



Manual curation of evaluation datasets is struggling to keep up with the rapidly expanding capabilities and deployment scenarios of language models. Towards scalable model profiling, we introduce and validate a framework for evaluating LLMs, called Adaptive Evaluations. Adaptive evaluations use scaffolded language models (evaluator agents) to search through a target model's behavior on a domain dataset and create difficult questions (tasks) that can discover and probe the model's failure modes. We find that frontier models lack consistency when adaptively probed with our framework on a diverse suite of datasets and tasks, including but not limited to legal reasoning, forecasting, and online harassment. Generated questions pass human validity checks and often transfer to other models with different capability profiles, demonstrating that adaptive evaluations can also be used to create difficult domain-specific datasets.
The FIX Benchmark: Extracting Features Interpretable to eXperts
Sep 20, 2024



Feature-based methods are commonly used to explain model predictions, but these methods often implicitly assume that interpretable features are readily available. However, this is often not the case for high-dimensional data, and it can be hard even for domain experts to mathematically specify which features are important. Can we instead automatically extract collections or groups of features that are aligned with expert knowledge? To address this gap, we present FIX (Features Interpretable to eXperts), a benchmark for measuring how well a collection of features aligns with expert knowledge. In collaboration with domain experts, we have developed feature interpretability objectives across diverse real-world settings and unified them into a single framework that is the FIX benchmark. We find that popular feature-based explanation methods have poor alignment with expert-specified knowledge, highlighting the need for new methods that can better identify features interpretable to experts.
Linguistic Properties of Truthful Response
May 25, 2023



We investigate the phenomenon of an LLM's untruthful response using a large set of 220 handcrafted linguistic features. We focus on GPT-3 models and find that the linguistic profiles of responses are similar across model sizes. That is, how varying-sized LLMs respond to given prompts stays similar on the linguistic properties level. We expand upon this finding by training support vector machines that rely only upon the stylistic components of model responses to classify the truthfulness of statements. Though the dataset size limits our current findings, we present promising evidence that truthfulness detection is possible without evaluating the content itself.
Generic Temporal Reasoning with Differential Analysis and Explanation
Dec 20, 2022



Temporal reasoning is the task of predicting temporal relations of event pairs with corresponding contexts. While some temporal reasoning models perform reasonably well on in-domain benchmarks, we have little idea of the systems' generalizability due to existing datasets' limitations. In this work, we introduce a novel task named TODAY that bridges this gap with temporal differential analysis, which as the name suggests, evaluates if systems can correctly understand the effect of incremental changes. Specifically, TODAY makes slight context changes for given event pairs, and systems need to tell how this subtle contextual change will affect temporal relation distributions. To facilitate learning, TODAY also annotates human explanations. We show that existing models, including GPT-3, drop to random guessing on TODAY, suggesting that they heavily rely on spurious information rather than proper reasoning for temporal predictions. On the other hand, we show that TODAY's supervision style and explanation annotations can be used in joint learning and encourage models to use more appropriate signals during training and outperform across several benchmarks. TODAY can also be used to train models to solicit incidental supervision from noisy sources such as GPT-3 and moves farther towards generic temporal reasoning systems.
Artificial Perceptual Learning: Image Categorization with Weak Supervision
Jun 02, 2021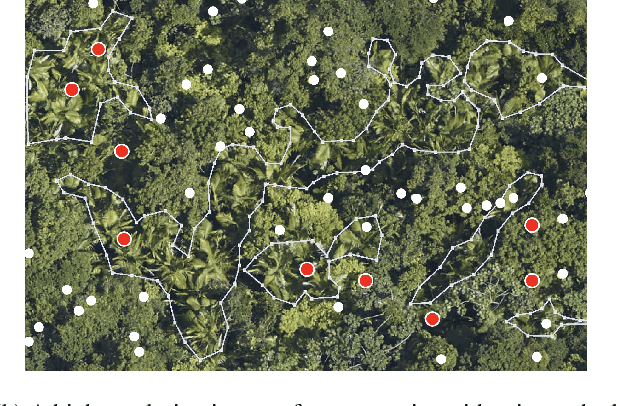
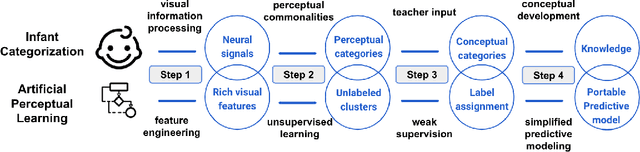

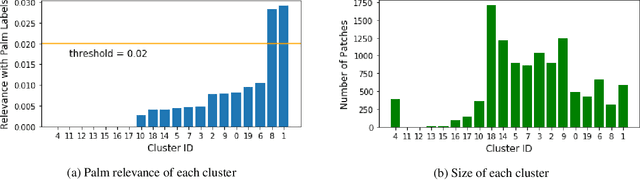
Machine learning has achieved much success on supervised learning tasks with large sets of well-annotated training samples. However, in many practical situations, such strong and high-quality supervision provided by training data is unavailable due to the expensive and labor-intensive labeling process. Automatically identifying and recognizing object categories in a large volume of unlabeled images with weak supervision remains an important, yet unsolved challenge in computer vision. In this paper, we propose a novel machine learning framework, artificial perceptual learning (APL), to tackle the problem of weakly supervised image categorization. The proposed APL framework is constructed using state-of-the-art machine learning algorithms as building blocks to mimic the cognitive development process known as infant categorization. We develop and illustrate the proposed framework by implementing a wide-field fine-grain ecological survey of tree species over an 8,000-hectare area of the El Yunque rainforest in Puerto Rico. It is based on unlabeled high-resolution aerial images of the tree canopy. Misplaced ground-based labels were available for less than 1% of these images, which serve as the only weak supervision for this learning framework. We validate the proposed framework using a small set of images with high quality human annotations and show that the proposed framework attains human-level cognitive economy.