 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Long Context Hallucination Detection
Apr 28, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various tasks. However, they are prone to contextual hallucination, generating information that is either unsubstantiated or contradictory to the given context. Although many studies have investigated contextual hallucinations in LLMs, addressing them in long-context inputs remains an open problem. In this work, we take an initial step toward solving this problem by constructing a dataset specifically designed for long-context hallucination detection. Furthermore, we propose a novel architecture that enables pre-trained encoder models, such as BERT, to process long contexts and effectively detect contextual hallucinations through a decomposition and aggregation mechanism. Our experimental results show that the proposed architecture significantly outperforms previous models of similar size as well as LLM-based models across various metrics, while providing substantially faster inference.
Exploration of Plan-Guided Summarization for Narrative Texts: the Case of Small Language Models
Apr 12, 2025



Plan-guided summarization attempts to reduce hallucinations in small language models (SLMs) by grounding generated summaries to the source text, typically by targeting fine-grained details such as dates or named entities. In this work, we investigate whether plan-based approaches in SLMs improve summarization in long document, narrative tasks. Narrative texts' length and complexity often mean they are difficult to summarize faithfully. We analyze existing plan-guided solutions targeting fine-grained details, and also propose our own higher-level, narrative-based plan formulation. Our results show that neither approach significantly improves on a baseline without planning in either summary quality or faithfulness. Human evaluation reveals that while plan-guided approaches are often well grounded to their plan, plans are equally likely to contain hallucinations compared to summaries. As a result, the plan-guided summaries are just as unfaithful as those from models without planning. Our work serves as a cautionary tale to plan-guided approaches to summarization, especially for long, complex domains such as narrative texts.
DiverseAgentEntropy: Quantifying Black-Box LLM Uncertainty through Diverse Perspectives and Multi-Agent Interaction
Dec 12, 2024



Quantifying the uncertainty in the factual parametric knowledge of Large Language Models (LLMs), especially in a black-box setting, poses a significant challenge. Existing methods, which gauge a model's uncertainty through evaluating self-consistency in responses to the original query, do not always capture true uncertainty. Models might respond consistently to the origin query with a wrong answer, yet respond correctly to varied questions from different perspectives about the same query, and vice versa. In this paper, we propose a novel method, DiverseAgentEntropy, for evaluating a model's uncertainty using multi-agent interaction under the assumption that if a model is certain, it should consistently recall the answer to the original query across a diverse collection of questions about the same original query. We further implement an abstention policy to withhold responses when uncertainty is high. Our method offers a more accurate prediction of the model's reliability and further detects hallucinations, outperforming other self-consistency-based methods. Additionally, it demonstrates that existing models often fail to consistently retrieve the correct answer to the same query under diverse varied questions even when knowing the correct answer.
Inference time LLM alignment in single and multidomain preference spectrum
Oct 24, 2024



Aligning Large Language Models (LLM) to address subjectivity and nuanced preference levels requires adequate flexibility and control, which can be a resource-intensive and time-consuming procedure. Existing training-time alignment methods require full re-training when a change is needed and inference-time ones typically require access to the reward model at each inference step. To address these limitations, we introduce inference-time model alignment method that learns encoded representations of preference dimensions, called \textit{Alignment Vectors} (AV). These representations are computed by subtraction of the base model from the aligned model as in model editing enabling dynamically adjusting the model behavior during inference through simple linear operations. Even though the preference dimensions can span various granularity levels, here we focus on three gradual response levels across three specialized domains: medical, legal, and financial, exemplifying its practical potential. This new alignment paradigm introduces adjustable preference knobs during inference, allowing users to tailor their LLM outputs while reducing the inference cost by half compared to the prompt engineering approach. Additionally, we find that AVs are transferable across different fine-tuning stages of the same model, demonstrating their flexibility. AVs also facilitate multidomain, diverse preference alignment, making the process 12x faster than the retraining approach.
Open Domain Question Answering with Conflicting Contexts
Oct 16, 2024



Open domain question answering systems frequently rely on information retrieved from large collections of text (such as the Web) to answer questions. However, such collections of text often contain conflicting information, and indiscriminately depending on this information may result in untruthful and inaccurate answers. To understand the gravity of this problem, we collect a human-annotated dataset, Question Answering with Conflicting Contexts (QACC), and find that as much as 25% of unambiguous, open domain questions can lead to conflicting contexts when retrieved using Google Search. We evaluate and benchmark three powerful Large Language Models (LLMs) with our dataset QACC and demonstrate their limitations in effectively addressing questions with conflicting information. To explore how humans reason through conflicting contexts, we request our annotators to provide explanations for their selections of correct answers. We demonstrate that by finetuning LLMs to explain their answers, we can introduce richer information into their training that guide them through the process of reasoning with conflicting contexts.
Characterizing and Measuring Linguistic Dataset Drift
May 26, 2023


NLP models often degrade in performance when real world data distributions differ markedly from training data. However, existing dataset drift metrics in NLP have generally not considered specific dimensions of linguistic drift that affect model performance, and they have not been validated in their ability to predict model performance at the individual example level, where such metrics are often used in practice. In this paper, we propose three dimensions of linguistic dataset drift: vocabulary, structural, and semantic drift. These dimensions correspond to content word frequency divergences, syntactic divergences, and meaning changes not captured by word frequencies (e.g. lexical semantic change). We propose interpretable metrics for all three drift dimensions, and we modify past performance prediction methods to predict model performance at both the example and dataset level for English sentiment classification and natural language inference. We find that our drift metrics are more effective than previous metrics at predicting out-of-domain model accuracies (mean 16.8% root mean square error decrease), particularly when compared to popular fine-tuned embedding distances (mean 47.7% error decrease). Fine-tuned embedding distances are much more effective at ranking individual examples by expected performance, but decomposing into vocabulary, structural, and semantic drift produces the best example rankings of all considered model-agnostic drift metrics (mean 6.7% ROC AUC increase).
A Weak Supervision Approach for Few-Shot Aspect Based Sentiment
May 19, 2023



We explore how weak supervision on abundant unlabeled data can be leveraged to improve few-shot performance in aspect-based sentiment analysis (ABSA) tasks. We propose a pipeline approach to construct a noisy ABSA dataset, and we use it to adapt a pre-trained sequence-to-sequence model to the ABSA tasks. We test the resulting model on three widely used ABSA datasets, before and after fine-tuning. Our proposed method preserves the full fine-tuning performance while showing significant improvements (15.84% absolute F1) in the few-shot learning scenario for the harder tasks. In zero-shot (i.e., without fine-tuning), our method outperforms the previous state of the art on the aspect extraction sentiment classification (AESC) task and is, additionally, capable of performing the harder aspect sentiment triplet extraction (ASTE) task.
Task-Specific Embeddings for Ante-Hoc Explainable Text Classification
Nov 30, 2022



Current state-of-the-art approaches to text classification typically leverage BERT-style Transformer models with a softmax classifier, jointly fine-tuned to predict class labels of a target task. In this paper, we instead propose an alternative training objective in which we learn task-specific embeddings of text: our proposed objective learns embeddings such that all texts that share the same target class label should be close together in the embedding space, while all others should be far apart. This allows us to replace the softmax classifier with a more interpretable k-nearest-neighbor classification approach. In a series of experiments, we show that this yields a number of interesting benefits: (1) The resulting order induced by distances in the embedding space can be used to directly explain classification decisions. (2) This facilitates qualitative inspection of the training data, helping us to better understand the problem space and identify labelling quality issues. (3) The learned distances to some degree generalize to unseen classes, allowing us to incrementally add new classes without retraining the model. We present extensive experiments which show that the benefits of ante-hoc explainability and incremental learning come at no cost in overall classification accuracy, thus pointing to practical applicability of our proposed approach.
Enhancing Product Safety in E-Commerce with NLP
Oct 25, 2022Ensuring safety of the products offered to the customers is of paramount importance to any e- commerce platform. Despite stringent quality and safety checking of products listed on these platforms, occasionally customers might receive a product that can pose a safety issue arising out of its use. In this paper, we present an innovative mechanism of how a large scale multinational e-commerce platform, Zalando, uses Natural Language Processing techniques to assist timely investigation of the potentially unsafe products mined directly from customer written claims in unstructured plain text. We systematically describe the types of safety issues that concern Zalando customers. We demonstrate how we map this core business problem into a supervised text classification problem with highly imbalanced, noisy, multilingual data in a AI-in-the-loop setup with a focus on Key Performance Indicator (KPI) driven evaluation. Finally, we present detailed ablation studies to show a comprehensive comparison between different classification techniques. We conclude the work with how this NLP model was deployed.
Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis
Oct 12, 2022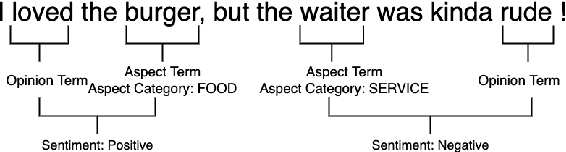
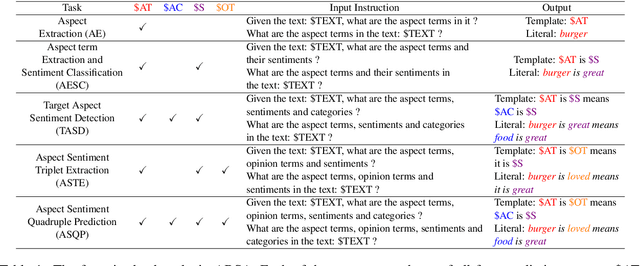
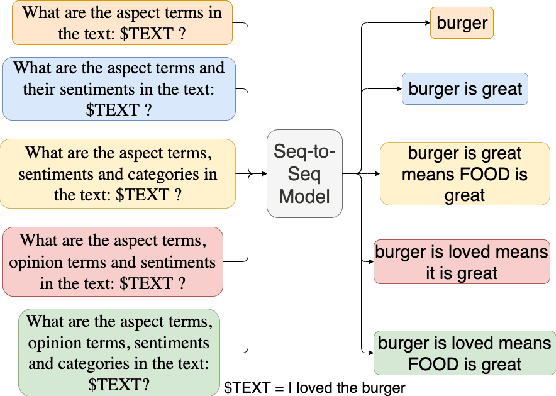
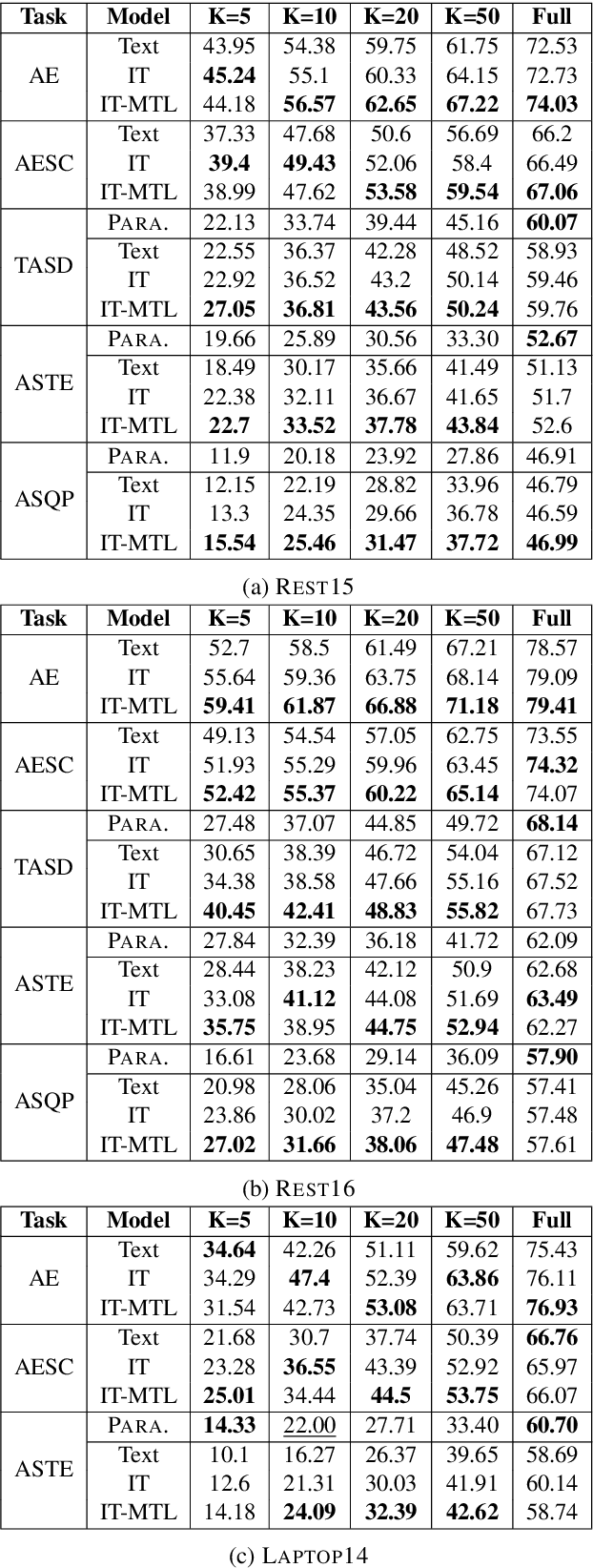
Aspect-based Sentiment Analysis (ABSA) is a fine-grained sentiment analysis task which involves four elements from user-generated texts: aspect term, aspect category, opinion term, and sentiment polarity. Most computational approaches focus on some of the ABSA sub-tasks such as tuple (aspect term, sentiment polarity) or triplet (aspect term, opinion term, sentiment polarity) extraction using either pipeline or joint modeling approaches. Recently, generative approaches have been proposed to extract all four elements as (one or more) quadruplets from text as a single task. In this work, we take a step further and propose a unified framework for solving ABSA, and the associated sub-tasks to improve the performance in few-shot scenarios. To this end, we fine-tune a T5 model with instructional prompts in a multi-task learning fashion covering all the sub-tasks, as well as the entire quadruple prediction task. In experiments with multiple benchmark data sets, we show that the proposed multi-task prompting approach brings performance boost (by absolute $6.75$ F1) in the few-shot learning setting.