 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Re-Modulation for Few-Shot Generative Domain Adaptation
Feb 07, 2023In this study, we investigate the task of few-shot Generative Domain Adaptation (GDA), which involves transferring a pre-trained generator from one domain to a new domain using one or a few reference images. Building upon previous research that has focused on Target-domain Consistency, Large Diversity, and Cross-domain Consistency, we conclude two additional desired properties for GDA: Memory and Domain Association. To meet these properties, we proposed a novel method Domain Re-Modulation (DoRM). Specifically, DoRM freezes the source generator and employs additional mapping and affine modules (M&A module) to capture the attributes of the target domain, resulting in a linearly combinable domain shift in style space. This allows for high-fidelity multi-domain and hybrid-domain generation by integrating multiple M&A modules in a single generator. DoRM is lightweight and easy to implement. Extensive experiments demonstrated the superior performance of DoRM on both one-shot and 10-shot GDA, both quantitatively and qualitatively. Additionally, for the first time, multi-domain and hybrid-domain generation can be achieved with a minimal storage cost by using a single model. The code will be available at https://github.com/wuyi2020/DoRM.
AniPixel: Towards Animatable Pixel-Aligned Human Avatar
Feb 07, 2023Neural radiance field using pixel-aligned features can render photo-realistic novel views. However, when pixel-aligned features are directly introduced to human avatar reconstruction, the rendering can only be conducted for still humans, rather than animatable avatars. In this paper, we propose AniPixel, a novel animatable and generalizable human avatar reconstruction method that leverages pixel-aligned features for body geometry prediction and RGB color blending. Technically, to align the canonical space with the target space and the observation space, we propose a bidirectional neural skinning field based on skeleton-driven deformation to establish the target-to-canonical and canonical-to-observation correspondences. Then, we disentangle the canonical body geometry into a normalized neutral-sized body and a subject-specific residual for better generalizability. As the geometry and appearance are closely related, we introduce pixel-aligned features to facilitate the body geometry prediction and detailed surface normals to reinforce the RGB color blending. Moreover, we devise a pose-dependent and view direction-related shading module to represent the local illumination variance. Experiments show that our AniPixel renders comparable novel views while delivering better novel pose animation results than state-of-the-art methods. The code will be released.
Neural Collapse Inspired Feature-Classifier Alignment for Few-Shot Class Incremental Learning
Feb 06, 2023



Few-shot class-incremental learning (FSCIL) has been a challenging problem as only a few training samples are accessible for each novel class in the new sessions. Finetuning the backbone or adjusting the classifier prototypes trained in the prior sessions would inevitably cause a misalignment between the feature and classifier of old classes, which explains the well-known catastrophic forgetting problem. In this paper, we deal with this misalignment dilemma in FSCIL inspired by the recently discovered phenomenon named neural collapse, which reveals that the last-layer features of the same class will collapse into a vertex, and the vertices of all classes are aligned with the classifier prototypes, which are formed as a simplex equiangular tight frame (ETF). It corresponds to an optimal geometric structure for classification due to the maximized Fisher Discriminant Ratio. We propose a neural collapse inspired framework for FSCIL. A group of classifier prototypes are pre-assigned as a simplex ETF for the whole label space, including the base session and all the incremental sessions. During training, the classifier prototypes are not learnable, and we adopt a novel loss function that drives the features into their corresponding prototypes. Theoretical analysis shows that our method holds the neural collapse optimality and does not break the feature-classifier alignment in an incremental fashion. Experiments on the miniImageNet, CUB-200, and CIFAR-100 datasets demonstrate that our proposed framework outperforms the state-of-the-art performances. Code address: https://github.com/NeuralCollapseApplications/FSCIL
SaFormer: A Conditional Sequence Modeling Approach to Offline Safe Reinforcement Learning
Jan 28, 2023



Offline safe RL is of great practical relevance for deploying agents in real-world applications. However, acquiring constraint-satisfying policies from the fixed dataset is non-trivial for conventional approaches. Even worse, the learned constraints are stationary and may become invalid when the online safety requirement changes. In this paper, we present a novel offline safe RL approach referred to as SaFormer, which tackles the above issues via conditional sequence modeling. In contrast to existing sequence models, we propose cost-related tokens to restrict the action space and a posterior safety verification to enforce the constraint explicitly. Specifically, SaFormer performs a two-stage auto-regression conditioned by the maximum remaining cost to generate feasible candidates. It then filters out unsafe attempts and executes the optimal action with the highest expected return. Extensive experiments demonstrate the efficacy of SaFormer featuring (1) competitive returns with tightened constraint satisfaction; (2) adaptability to the in-range cost values of the offline data without retraining; (3) generalizability for constraints beyond the current dataset.
Global Nash Equilibrium in Non-convex Multi-player Game: Theory and Algorithms
Jan 19, 2023



Wide machine learning tasks can be formulated as non-convex multi-player games, where Nash equilibrium (NE) is an acceptable solution to all players, since no one can benefit from changing its strategy unilaterally. Attributed to the non-convexity, obtaining the existence condition of global NE is challenging, let alone designing theoretically guaranteed realization algorithms. This paper takes conjugate transformation to the formulation of non-convex multi-player games, and casts the complementary problem into a variational inequality (VI) problem with a continuous pseudo-gradient mapping. We then prove the existence condition of global NE: the solution to the VI problem satisfies a duality relation. Based on this VI formulation, we design a conjugate-based ordinary differential equation (ODE) to approach global NE, which is proved to have an exponential convergence rate. To make the dynamics more implementable, we further derive a discretized algorithm. We apply our algorithm to two typical scenarios: multi-player generalized monotone game and multi-player potential game. In the two settings, we prove that the step-size setting is required to be $\mathcal{O}(1/k)$ and $\mathcal{O}(1/\sqrt k)$ to yield the convergence rates of $\mathcal{O}(1/ k)$ and $\mathcal{O}(1/\sqrt k)$, respectively. Extensive experiments in robust neural network training and sensor localization are in full agreement with our theory.
A Comprehensive Survey to Dataset Distillation
Jan 13, 2023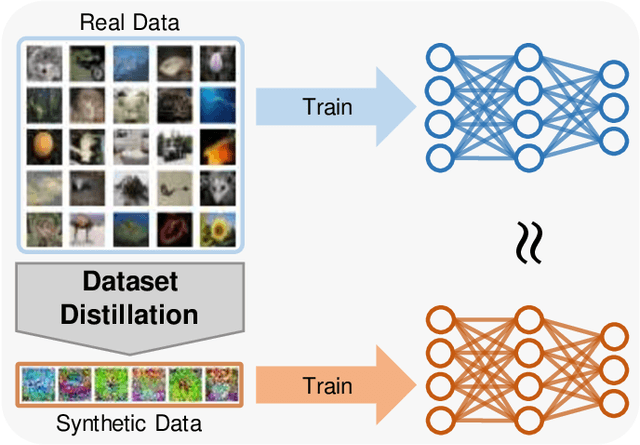
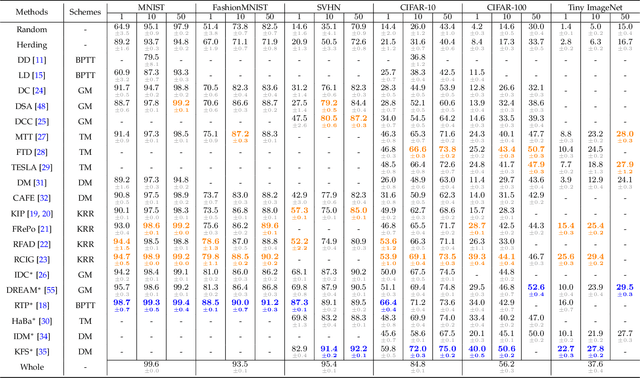
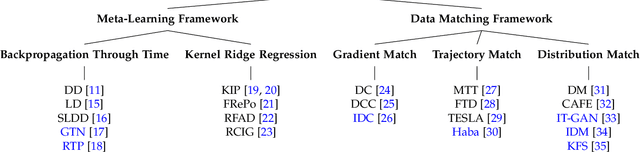
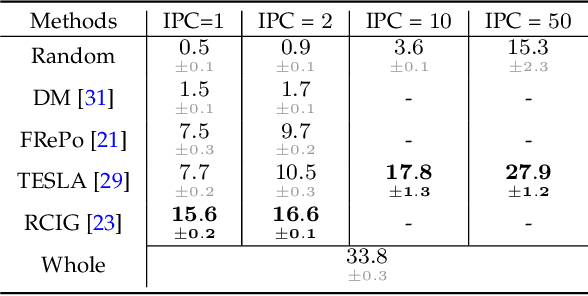
Deep learning technology has unprecedentedly developed in the last decade and has become the primary choice in many application domains. This progress is mainly attributed to a systematic collaboration that rapidly growing computing resources encourage advanced algorithms to deal with massive data. However, it gradually becomes challenging to cope with the unlimited growth of data with limited computing power. To this end, diverse approaches are proposed to improve data processing efficiency. Dataset distillation, one of the dataset reduction methods, tackles the problem via synthesising a small typical dataset from giant data and has attracted a lot of attention from the deep learning community. Existing dataset distillation methods can be taxonomised into meta-learning and data match framework according to whether explicitly mimic target data. Albeit dataset distillation has shown a surprising performance in compressing datasets, it still possesses several limitations such as distilling high-resolution data. This paper provides a holistic understanding of dataset distillation from multiple aspects, including distillation frameworks and algorithms, disentangled dataset distillation, performance comparison, and applications. Finally, we discuss challenges and promising directions to further promote future studies about dataset distillation.
A Survey of Self-Supervised Learning from Multiple Perspectives: Algorithms, Theory, Applications and Future Trends
Jan 13, 2023



Deep supervised learning algorithms generally require large numbers of labeled examples to attain satisfactory performance. To avoid the expensive cost incurred by collecting and labeling too many examples, as a subset of unsupervised learning, self-supervised learning (SSL) was proposed to learn good features from many unlabeled examples without any human-annotated labels. SSL has recently become a hot research topic, and many related algorithms have been proposed. However, few comprehensive studies have explained the connections among different SSL variants and how they have evolved. In this paper, we attempt to provide a review of the various SSL methods from the perspectives of algorithms, theory, applications, three main trends, and open questions. First, the motivations of most SSL algorithms are introduced in detail, and their commonalities and differences are compared. Second, the theoretical issues associated with SSL are investigated. Third, typical applications of SSL in areas such as image processing and computer vision (CV), as well as natural language processing (NLP), are discussed. Finally, the three main trends of SSL and the open research questions are discussed. A collection of useful materials is available at https://github.com/guijiejie/SSL.
PanopticPartFormer++: A Unified and Decoupled View for Panoptic Part Segmentation
Jan 03, 2023



Panoptic Part Segmentation (PPS) unifies panoptic segmentation and part segmentation into one task. Previous works utilize separated approaches to handle thing, stuff, and part predictions without shared computation and task association. We aim to unify these tasks at the architectural level, designing the first end-to-end unified framework named Panoptic-PartFormer. Moreover, we find the previous metric PartPQ biases to PQ. To handle both issues, we make the following contributions: Firstly, we design a meta-architecture that decouples part feature and things/stuff feature, respectively. We model things, stuff, and parts as object queries and directly learn to optimize all three forms of prediction as a unified mask prediction and classification problem. We term our model as Panoptic-PartFormer. Secondly, we propose a new metric Part-Whole Quality (PWQ) to better measure such task from both pixel-region and part-whole perspectives. It can also decouple the error for part segmentation and panoptic segmentation. Thirdly, inspired by Mask2Former, based on our meta-architecture, we propose Panoptic-PartFormer++ and design a new part-whole cross attention scheme to further boost part segmentation qualities. We design a new part-whole interaction method using masked cross attention. Finally, the extensive ablation studies and analysis demonstrate the effectiveness of both Panoptic-PartFormer and Panoptic-PartFormer++. Compared with previous Panoptic-PartFormer, our Panoptic-PartFormer++ achieves 2% PartPQ and 3% PWQ improvements on the Cityscapes PPS dataset and 5% PartPQ on the Pascal Context PPS dataset. On both datasets, Panoptic-PartFormer++ achieves new state-of-the-art results with a significant cost drop of 70% on GFlops and 50% on parameters. Our models can serve as a strong baseline and aid future research in PPS. Code will be available.
Demystify Problem-Dependent Power of Quantum Neural Networks on Multi-Class Classification
Dec 29, 2022



Quantum neural networks (QNNs) have become an important tool for understanding the physical world, but their advantages and limitations are not fully understood. Some QNNs with specific encoding methods can be efficiently simulated by classical surrogates, while others with quantum memory may perform better than classical classifiers. Here we systematically investigate the problem-dependent power of quantum neural classifiers (QCs) on multi-class classification tasks. Through the analysis of expected risk, a measure that weighs the training loss and the generalization error of a classifier jointly, we identify two key findings: first, the training loss dominates the power rather than the generalization ability; second, QCs undergo a U-shaped risk curve, in contrast to the double-descent risk curve of deep neural classifiers. We also reveal the intrinsic connection between optimal QCs and the Helstrom bound and the equiangular tight frame. Using these findings, we propose a method that uses loss dynamics to probe whether a QC may be more effective than a classical classifier on a particular learning task. Numerical results demonstrate the effectiveness of our approach to explain the superiority of QCs over multilayer Perceptron on parity datasets and their limitations over convolutional neural networks on image datasets. Our work sheds light on the problem-dependent power of QNNs and offers a practical tool for evaluating their potential merit.
On Transforming Reinforcement Learning by Transformer: The Development Trajectory
Dec 29, 2022



Transformer, originally devised for natural language processing, has also attested significant success in computer vision. Thanks to its super expressive power, researchers are investigating ways to deploy transformers to reinforcement learning (RL) and the transformer-based models have manifested their potential in representative RL benchmarks. In this paper, we collect and dissect recent advances on transforming RL by transformer (transformer-based RL or TRL), in order to explore its development trajectory and future trend. We group existing developments in two categories: architecture enhancement and trajectory optimization, and examine the main applications of TRL in robotic manipulation, text-based games, navigation and autonomous driving. For architecture enhancement, these methods consider how to apply the powerful transformer structure to RL problems under the traditional RL framework, which model agents and environments much more precisely than deep RL methods, but they are still limited by the inherent defects of traditional RL algorithms, such as bootstrapping and "deadly triad". For trajectory optimization, these methods treat RL problems as sequence modeling and train a joint state-action model over entire trajectories under the behavior cloning framework, which are able to extract policies from static datasets and fully use the long-sequence modeling capability of the transformer. Given these advancements, extensions and challenges in TRL are reviewed and proposals about future direction are discussed. We hope that this survey can provide a detailed introduction to TRL and motivate future research in this rapidly developing field.