 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Multi-objective Policy Optimization as a Tool for Reinforcement Learning
Jun 15, 2021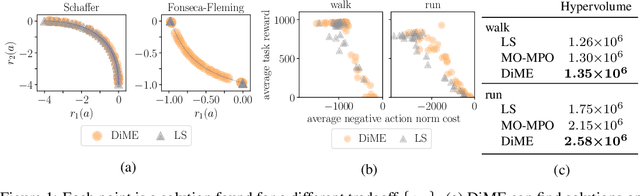
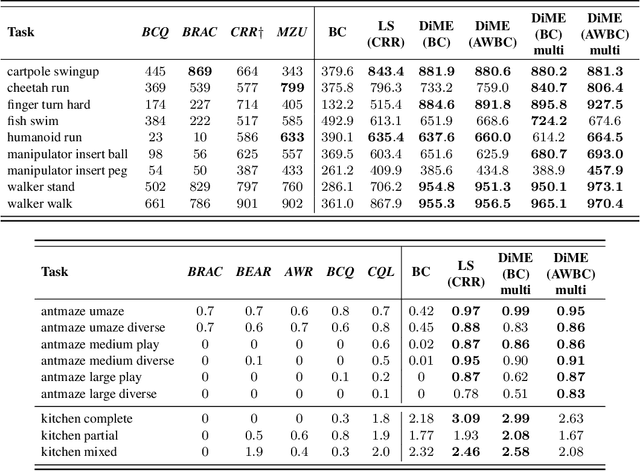
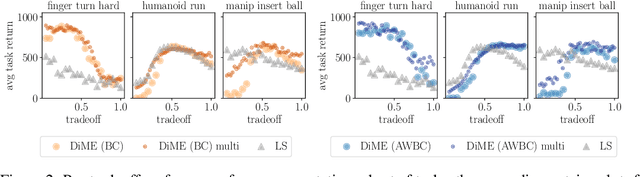

Many advances that have improved the robustness and efficiency of deep reinforcement learning (RL) algorithms can, in one way or another, be understood as introducing additional objectives, or constraints, in the policy optimization step. This includes ideas as far ranging as exploration bonuses, entropy regularization, and regularization toward teachers or data priors when learning from experts or in offline RL. Often, task reward and auxiliary objectives are in conflict with each other and it is therefore natural to treat these examples as instances of multi-objective (MO) optimization problems. We study the principles underlying MORL and introduce a new algorithm, Distillation of a Mixture of Experts (DiME), that is intuitive and scale-invariant under some conditions. We highlight its strengths on standard MO benchmark problems and consider case studies in which we recast offline RL and learning from experts as MO problems. This leads to a natural algorithmic formulation that sheds light on the connection between existing approaches. For offline RL, we use the MO perspective to derive a simple algorithm, that optimizes for the standard RL objective plus a behavioral cloning term. This outperforms state-of-the-art on two established offline RL benchmarks.
Leveraging Non-uniformity in First-order Non-convex Optimization
May 13, 2021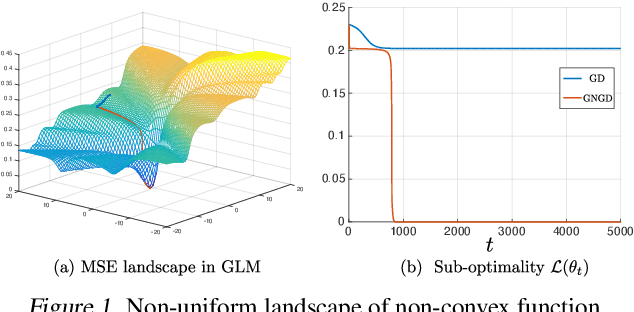
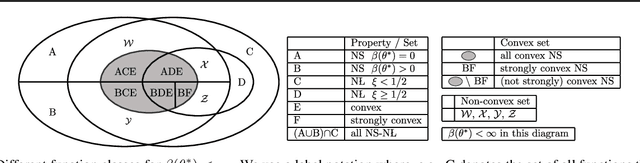
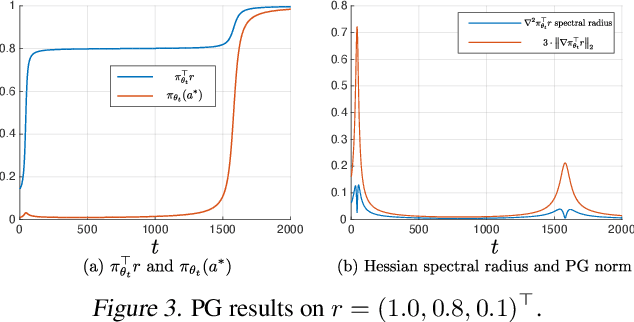
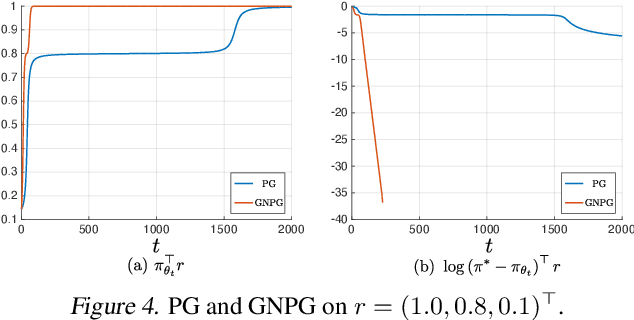
Classical global convergence results for first-order methods rely on uniform smoothness and the \L{}ojasiewicz inequality. Motivated by properties of objective functions that arise in machine learning, we propose a non-uniform refinement of these notions, leading to \emph{Non-uniform Smoothness} (NS) and \emph{Non-uniform \L{}ojasiewicz inequality} (N\L{}). The new definitions inspire new geometry-aware first-order methods that are able to converge to global optimality faster than the classical $\Omega(1/t^2)$ lower bounds. To illustrate the power of these geometry-aware methods and their corresponding non-uniform analysis, we consider two important problems in machine learning: policy gradient optimization in reinforcement learning (PG), and generalized linear model training in supervised learning (GLM). For PG, we find that normalizing the gradient ascent method can accelerate convergence to $O(e^{-t})$ while incurring less overhead than existing algorithms. For GLM, we show that geometry-aware normalized gradient descent can also achieve a linear convergence rate, which significantly improves the best known results. We additionally show that the proposed geometry-aware descent methods escape landscape plateaus faster than standard gradient descent. Experimental results are used to illustrate and complement the theoretical findings.
On the Optimality of Batch Policy Optimization Algorithms
Apr 06, 2021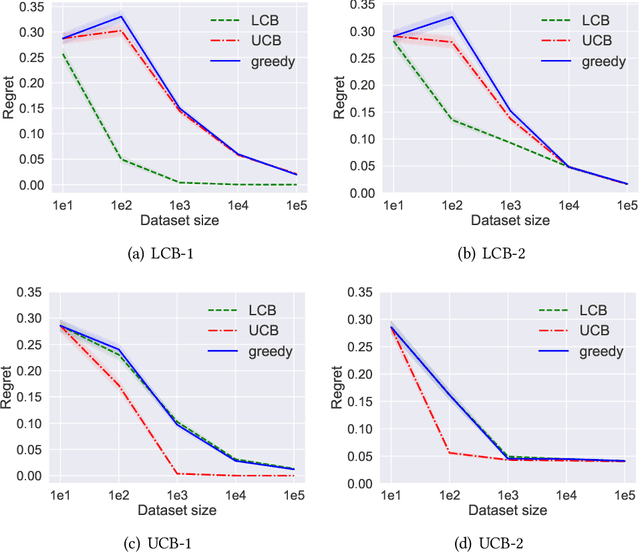
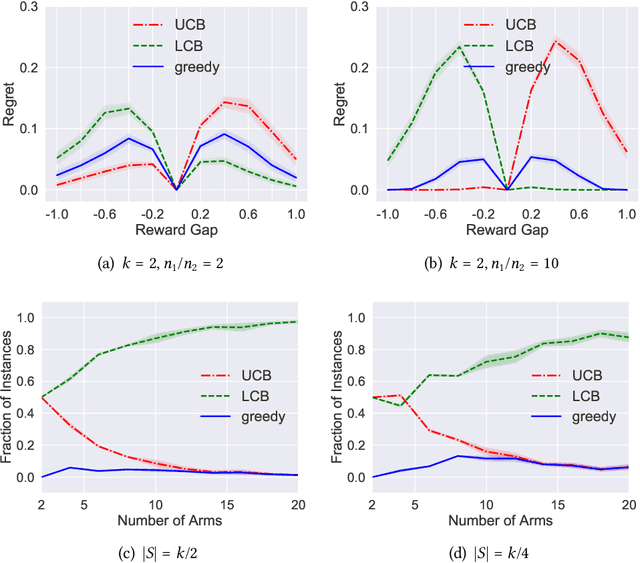
Batch policy optimization considers leveraging existing data for policy construction before interacting with an environment. Although interest in this problem has grown significantly in recent years, its theoretical foundations remain under-developed. To advance the understanding of this problem, we provide three results that characterize the limits and possibilities of batch policy optimization in the finite-armed stochastic bandit setting. First, we introduce a class of confidence-adjusted index algorithms that unifies optimistic and pessimistic principles in a common framework, which enables a general analysis. For this family, we show that any confidence-adjusted index algorithm is minimax optimal, whether it be optimistic, pessimistic or neutral. Our analysis reveals that instance-dependent optimality, commonly used to establish optimality of on-line stochastic bandit algorithms, cannot be achieved by any algorithm in the batch setting. In particular, for any algorithm that performs optimally in some environment, there exists another environment where the same algorithm suffers arbitrarily larger regret. Therefore, to establish a framework for distinguishing algorithms, we introduce a new weighted-minimax criterion that considers the inherent difficulty of optimal value prediction. We demonstrate how this criterion can be used to justify commonly used pessimistic principles for batch policy optimization.
Improved Regret Bound and Experience Replay in Regularized Policy Iteration
Feb 25, 2021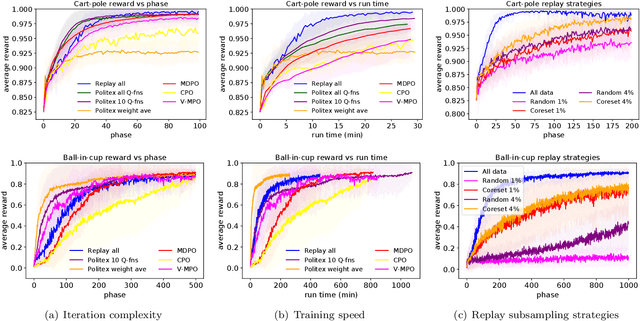
In this work, we study algorithms for learning in infinite-horizon undiscounted Markov decision processes (MDPs) with function approximation. We first show that the regret analysis of the Politex algorithm (a version of regularized policy iteration) can be sharpened from $O(T^{3/4})$ to $O(\sqrt{T})$ under nearly identical assumptions, and instantiate the bound with linear function approximation. Our result provides the first high-probability $O(\sqrt{T})$ regret bound for a computationally efficient algorithm in this setting. The exact implementation of Politex with neural network function approximation is inefficient in terms of memory and computation. Since our analysis suggests that we need to approximate the average of the action-value functions of past policies well, we propose a simple efficient implementation where we train a single Q-function on a replay buffer with past data. We show that this often leads to superior performance over other implementation choices, especially in terms of wall-clock time. Our work also provides a novel theoretical justification for using experience replay within policy iteration algorithms.
On the Convergence and Sample Efficiency of Variance-Reduced Policy Gradient Method
Feb 17, 2021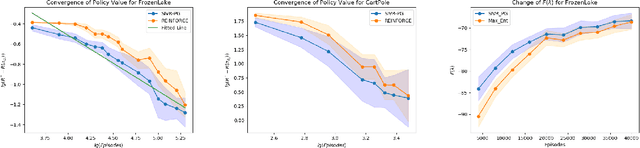
Policy gradient gives rise to a rich class of reinforcement learning (RL) methods, for example the REINFORCE. Yet the best known sample complexity result for such methods to find an $\epsilon$-optimal policy is $\mathcal{O}(\epsilon^{-3})$, which is suboptimal. In this paper, we study the fundamental convergence properties and sample efficiency of first-order policy optimization method. We focus on a generalized variant of policy gradient method, which is able to maximize not only a cumulative sum of rewards but also a general utility function over a policy's long-term visiting distribution. By exploiting the problem's hidden convex nature and leveraging techniques from composition optimization, we propose a Stochastic Incremental Variance-Reduced Policy Gradient (SIVR-PG) approach that improves a sequence of policies to provably converge to the global optimal solution and finds an $\epsilon$-optimal policy using $\tilde{\mathcal{O}}(\epsilon^{-2})$ samples.
Meta-Thompson Sampling
Feb 11, 2021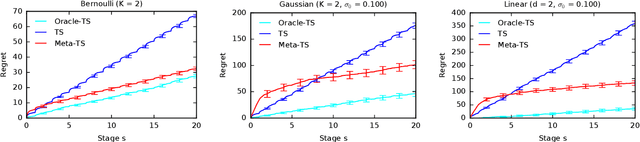
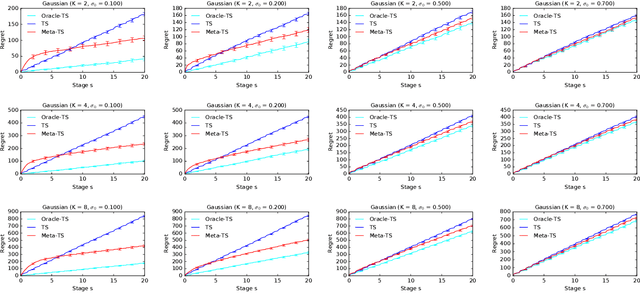
Efficient exploration in multi-armed bandits is a fundamental online learning problem. In this work, we propose a variant of Thompson sampling that learns to explore better as it interacts with problem instances drawn from an unknown prior distribution. Our algorithm meta-learns the prior and thus we call it Meta-TS. We propose efficient implementations of Meta-TS and analyze it in Gaussian bandits. Our analysis shows the benefit of meta-learning the prior and is of a broader interest, because we derive the first prior-dependent upper bound on the Bayes regret of Thompson sampling. This result is complemented by empirical evaluation, which shows that Meta-TS quickly adapts to the unknown prior.
Nearly Minimax Optimal Reinforcement Learning for Linear Mixture Markov Decision Processes
Jan 07, 2021
We study reinforcement learning (RL) with linear function approximation where the underlying transition probability kernel of the Markov decision process (MDP) is a linear mixture model (Jia et al., 2020; Ayoub et al., 2020; Zhou et al., 2020) and the learning agent has access to either an integration or a sampling oracle of the individual basis kernels. We propose a new Bernstein-type concentration inequality for self-normalized martingales for linear bandit problems with bounded noise. Based on the new inequality, we propose a new, computationally efficient algorithm with linear function approximation named $\text{UCRL-VTR}^{+}$ for the aforementioned linear mixture MDPs in the episodic undiscounted setting. We show that $\text{UCRL-VTR}^{+}$ attains an $\tilde O(dH\sqrt{T})$ regret where $d$ is the dimension of feature mapping, $H$ is the length of the episode and $T$ is the number of interactions with the MDP. We also prove a matching lower bound $\Omega(dH\sqrt{T})$ for this setting, which shows that $\text{UCRL-VTR}^{+}$ is minimax optimal up to logarithmic factors. In addition, we propose the $\text{UCLK}^{+}$ algorithm for the same family of MDPs under discounting and show that it attains an $\tilde O(d\sqrt{T}/(1-\gamma)^{1.5})$ regret, where $\gamma\in [0,1)$ is the discount factor. Our upper bound matches the lower bound $\Omega(d\sqrt{T}/(1-\gamma)^{1.5})$ proved by Zhou et al. (2020) up to logarithmic factors, suggesting that $\text{UCLK}^{+}$ is nearly minimax optimal. To the best of our knowledge, these are the first computationally efficient, nearly minimax optimal algorithms for RL with linear function approximation.
Variational Policy Gradient Method for Reinforcement Learning with General Utilities
Jul 04, 2020
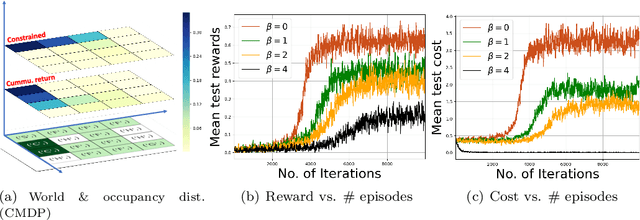
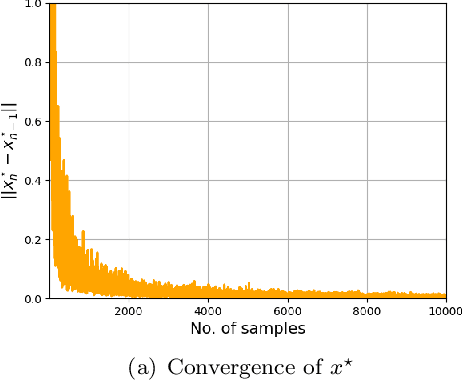
In recent years, reinforcement learning (RL) systems with general goals beyond a cumulative sum of rewards have gained traction, such as in constrained problems, exploration, and acting upon prior experiences. In this paper, we consider policy optimization in Markov Decision Problems, where the objective is a general concave utility function of the state-action occupancy measure, which subsumes several of the aforementioned examples as special cases. Such generality invalidates the Bellman equation. As this means that dynamic programming no longer works, we focus on direct policy search. Analogously to the Policy Gradient Theorem \cite{sutton2000policy} available for RL with cumulative rewards, we derive a new Variational Policy Gradient Theorem for RL with general utilities, which establishes that the parametrized policy gradient may be obtained as the solution of a stochastic saddle point problem involving the Fenchel dual of the utility function. We develop a variational Monte Carlo gradient estimation algorithm to compute the policy gradient based on sample paths. We prove that the variational policy gradient scheme converges globally to the optimal policy for the general objective, though the optimization problem is nonconvex. We also establish its rate of convergence of the order $O(1/t)$ by exploiting the hidden convexity of the problem, and proves that it converges exponentially when the problem admits hidden strong convexity. Our analysis applies to the standard RL problem with cumulative rewards as a special case, in which case our result improves the available convergence rate.
PAC-Bayes Analysis Beyond the Usual Bounds
Jun 23, 2020We focus on a stochastic learning model where the learner observes a finite set of training examples and the output of the learning process is a data-dependent distribution over a space of hypotheses. The learned data-dependent distribution is then used to make randomized predictions, and the high-level theme addressed here is guaranteeing the quality of predictions on examples that were not seen during training, i.e. generalization. In this setting the unknown quantity of interest is the expected risk of the data-dependent randomized predictor, for which upper bounds can be derived via a PAC-Bayes analysis, leading to PAC-Bayes bounds. Specifically, we present a basic PAC-Bayes inequality for stochastic kernels, from which one may derive extensions of various known PAC-Bayes bounds as well as novel bounds. We clarify the role of the requirement of fixed `data-free' priors and illustrate the use of data-dependent priors. We also present a simple bound that is valid for a loss function with unbounded range. Our analysis clarifies that those two requirements were used to upper-bound an exponential moment term, while the basic PAC-Bayes inequality remains valid with those restrictions removed.
Differentiable Meta-Learning in Contextual Bandits
Jun 09, 2020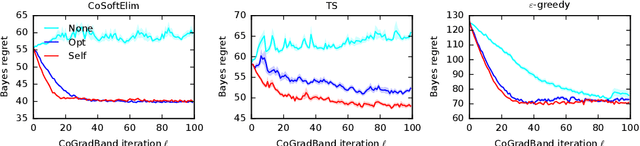
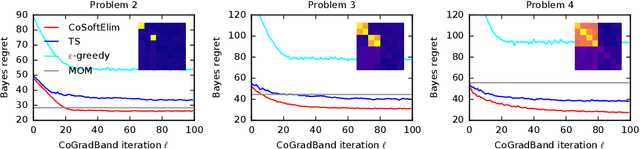
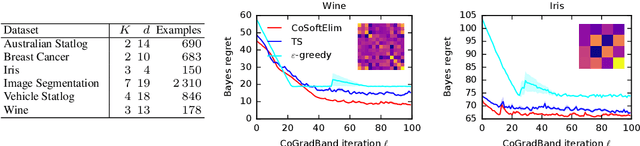
We study a contextual bandit setting where the learning agent has access to sampled bandit instances from an unknown prior distribution $\mathcal{P}$. The goal of the agent is to achieve high reward on average over the instances drawn from $\mathcal{P}$. This setting is of a particular importance because it formalizes the offline optimization of bandit policies, to perform well on average over anticipated bandit instances. The main idea in our work is to optimize differentiable bandit policies by policy gradients. We derive reward gradients that reflect the structure of our problem, and propose contextual policies that are parameterized in a differentiable way and have low regret. Our algorithmic and theoretical contributions are supported by extensive experiments that show the importance of baseline subtraction, learned biases, and the practicality of our approach on a range of classification tasks.