 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALSA: Soup-based Alignment Learning for Stronger Adaptation in RLHF
Nov 04, 2024



In Large Language Model (LLM) development, Reinforcement Learning from Human Feedback (RLHF) is crucial for aligning models with human values and preferences. RLHF traditionally relies on the Kullback-Leibler (KL) divergence between the current policy and a frozen initial policy as a reference, which is added as a penalty in policy optimization algorithms like Proximal Policy Optimization (PPO). While this constraint prevents models from deviating too far from the initial checkpoint, it limits exploration of the reward landscape, reducing the model's ability to discover higher-quality solutions. As a result, policy optimization is often trapped in a narrow region of the parameter space, leading to suboptimal alignment and performance. This paper presents SALSA (Soup-based Alignment Learning for Stronger Adaptation), a novel approach designed to overcome these limitations by creating a more flexible and better located reference model through weight-space averaging of two independent supervised fine-tuned (SFT) models. This model soup allows for larger deviation in KL divergence and exploring a promising region of the solution space without sacrificing stability. By leveraging this more robust reference model, SALSA fosters better exploration, achieving higher rewards and improving model robustness, out-of-distribution generalization, and performance. We validate the effectiveness of SALSA through extensive experiments on popular open models (Llama2-7B, Mistral-7B, and Gemma-2B) across various benchmarks (MT-Bench, Arena-Hard, UltraFeedback), where it consistently surpasses PPO by fostering deeper exploration and achieving superior alignment in LLMs.
Step-by-Step Reasoning for Math Problems via Twisted Sequential Monte Carlo
Oct 02, 2024



Augmenting the multi-step reasoning abilities of Large Language Models (LLMs) has been a persistent challenge. Recently, verification has shown promise in improving solution consistency by evaluating generated outputs. However, current verification approaches suffer from sampling inefficiencies, requiring a large number of samples to achieve satisfactory performance. Additionally, training an effective verifier often depends on extensive process supervision, which is costly to acquire. In this paper, we address these limitations by introducing a novel verification method based on Twisted Sequential Monte Carlo (TSMC). TSMC sequentially refines its sampling effort to focus exploration on promising candidates, resulting in more efficient generation of high-quality solutions. We apply TSMC to LLMs by estimating the expected future rewards at partial solutions. This approach results in a more straightforward training target that eliminates the need for step-wise human annotations. We empirically demonstrate the advantages of our method across multiple math benchmarks, and also validate our theoretical analysis of both our approach and existing verification methods.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
MindSet: Vision. A toolbox for testing DNNs on key psychological experiments
Apr 08, 2024



Multiple benchmarks have been developed to assess the alignment between deep neural networks (DNNs) and human vision. In almost all cases these benchmarks are observational in the sense they are composed of behavioural and brain responses to naturalistic images that have not been manipulated to test hypotheses regarding how DNNs or humans perceive and identify objects. Here we introduce the toolbox MindSet: Vision, consisting of a collection of image datasets and related scripts designed to test DNNs on 30 psychological findings. In all experimental conditions, the stimuli are systematically manipulated to test specific hypotheses regarding human visual perception and object recognition. In addition to providing pre-generated datasets of images, we provide code to regenerate these datasets, offering many configurable parameters which greatly extend the dataset versatility for different research contexts, and code to facilitate the testing of DNNs on these image datasets using three different methods (similarity judgments, out-of-distribution classification, and decoder method), accessible at https://github.com/MindSetVision/mindset-vision. We test ResNet-152 on each of these methods as an example of how the toolbox can be used.
Convolutional Neural Networks Trained to Identify Words Provide a Good Account of Visual Form Priming Effects
Mar 02, 2023A wide variety of orthographic coding schemes and models of visual word identification have been developed to account for masked priming data that provide a measure of orthographic similarity between letter strings. These models tend to include hand-coded orthographic representations with single unit coding for specific forms of knowledge (e.g., units coding for a letter in a given position). Here we assess how well a range of these coding schemes and models account for the pattern of form priming effects taken from the Form Priming Project and compare these findings to results observed with 11 standard deep neural network models (DNNs) developed in computer science. We find that deep convolutional networks (CNNs) perform as well or better than the coding schemes and word recognition models, whereas transformer networks did less well. The success of CNNs is remarkable as their architectures were not developed to support word recognition (they were designed to perform well on object recognition), they classify pixel images of words (rather than artificial encodings of letter strings), and their training was highly simplified (not respecting many key aspects of human experience). In addition to these form priming effects, we find that the DNNs can account for visual similarity effects on priming that are beyond all current psychological models of priming. The findings add to the recent work of (Hannagan et al., 2021) and suggest that CNNs should be given more attention in psychology as models of human visual word recognition.
Sample Efficient Deep Reinforcement Learning via Local Planning
Jan 29, 2023



The focus of this work is sample-efficient deep reinforcement learning (RL) with a simulator. One useful property of simulators is that it is typically easy to reset the environment to a previously observed state. We propose an algorithmic framework, named uncertainty-first local planning (UFLP), that takes advantage of this property. Concretely, in each data collection iteration, with some probability, our meta-algorithm resets the environment to an observed state which has high uncertainty, instead of sampling according to the initial-state distribution. The agent-environment interaction then proceeds as in the standard online RL setting. We demonstrate that this simple procedure can dramatically improve the sample cost of several baseline RL algorithms on difficult exploration tasks. Notably, with our framework, we can achieve super-human performance on the notoriously hard Atari game, Montezuma's Revenge, with a simple (distributional) double DQN. Our work can be seen as an efficient approximate implementation of an existing algorithm with theoretical guarantees, which offers an interpretation of the positive empirical results.
Architecture Matters in Continual Learning
Feb 01, 2022



A large body of research in continual learning is devoted to overcoming the catastrophic forgetting of neural networks by designing new algorithms that are robust to the distribution shifts. However, the majority of these works are strictly focused on the "algorithmic" part of continual learning for a "fixed neural network architecture", and the implications of using different architectures are mostly neglected. Even the few existing continual learning methods that modify the model assume a fixed architecture and aim to develop an algorithm that efficiently uses the model throughout the learning experience. However, in this work, we show that the choice of architecture can significantly impact the continual learning performance, and different architectures lead to different trade-offs between the ability to remember previous tasks and learning new ones. Moreover, we study the impact of various architectural decisions, and our findings entail best practices and recommendations that can improve the continual learning performance.
MORSE-STF: A Privacy Preserving Computation System
Sep 24, 2021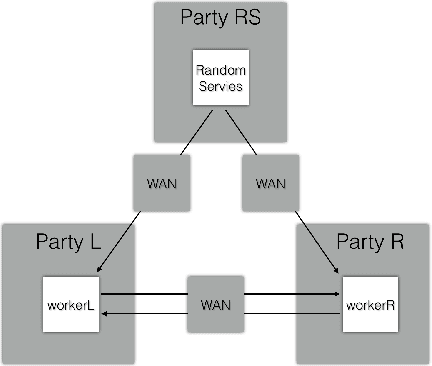
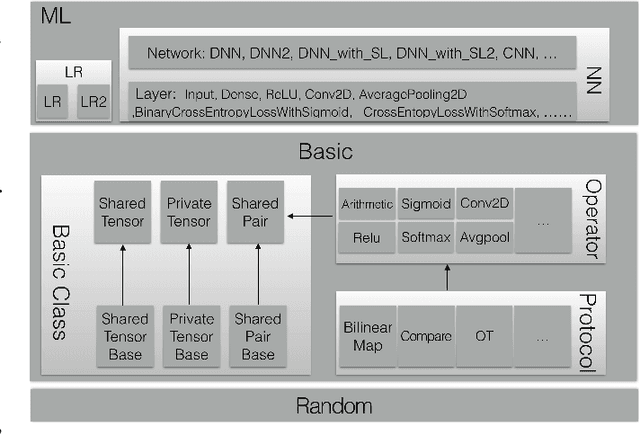

Privacy-preserving machine learning has become a popular area of research due to the increasing concern over data privacy. One way to achieve privacy-preserving machine learning is to use secure multi-party computation, where multiple distrusting parties can perform computations on data without revealing the data itself. We present Secure-TF, a privacy-preserving machine learning framework based on MPC. Our framework is able to support widely-used machine learning models such as logistic regression, fully-connected neural network, and convolutional neural network. We propose novel cryptographic protocols that has lower round complexity and less communication for computing sigmoid, ReLU, conv2D and there derivatives. All are central building blocks for modern machine learning models. With our more efficient protocols, our system is able to outperform previous state-of-the-art privacy-preserving machine learning framework in the WAN setting.
Efficient Local Planning with Linear Function Approximation
Aug 12, 2021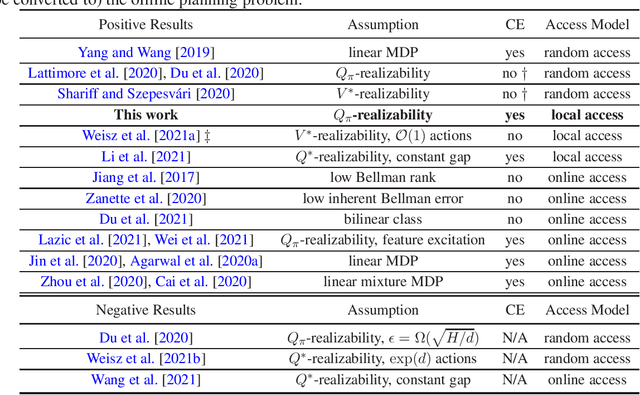
We study query and computationally efficient planning algorithms with linear function approximation and a simulator. We assume that the agent only has local access to the simulator, meaning that the agent can only query the simulator at states that have been visited before. This setting is more practical than many prior works on reinforcement learning with a generative model. We propose an algorithm named confident Monte Carlo least square policy iteration (Confident MC-LSPI) for this setting. Under the assumption that the Q-functions of all deterministic policies are linear in known features of the state-action pairs, we show that our algorithm has polynomial query and computational complexities in the dimension of the features, the effective planning horizon and the targeted sub-optimality, while these complexities are independent of the size of the state space. One technical contribution of our work is the introduction of a novel proof technique that makes use of a virtual policy iteration algorithm. We use this method to leverage existing results on $\ell_\infty$-bounded approximate policy iteration to show that our algorithm can learn the optimal policy for the given initial state even only with local access to the simulator. We believe that this technique can be extended to broader settings beyond this work.
A Realistic Simulation Framework for Learning with Label Noise
Jul 23, 2021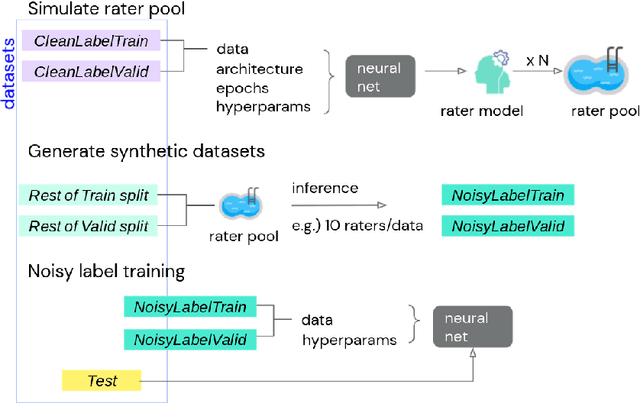
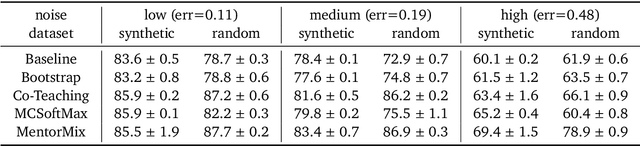
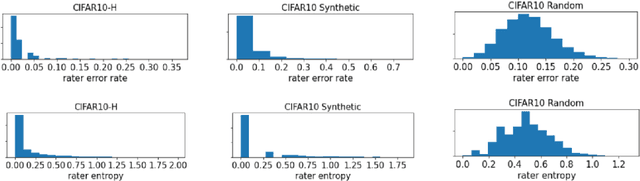
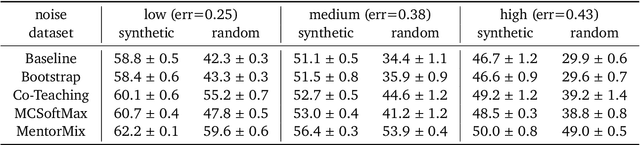
We propose a simulation framework for generating realistic instance-dependent noisy labels via a pseudo-labeling paradigm. We show that this framework generates synthetic noisy labels that exhibit important characteristics of the label noise in practical settings via comparison with the CIFAR10-H dataset. Equipped with controllable label noise, we study the negative impact of noisy labels across a few realistic settings to understand when label noise is more problematic. We also benchmark several existing algorithms for learning with noisy labels and compare their behavior on our synthetic datasets and on the datasets with independent random label noise. Additionally, with the availability of annotator information from our simulation framework, we propose a new technique, Label Quality Model (LQM), that leverages annotator features to predict and correct against noisy labels. We show that by adding LQM as a label correction step before applying existing noisy label techniques, we can further improve the models' performance.