 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
TempoMaster: Efficient Long Video Generation via Next-Frame-Rate Prediction
Nov 16, 2025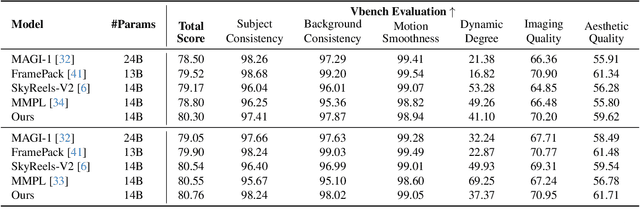
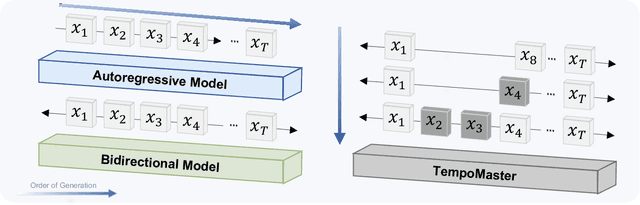
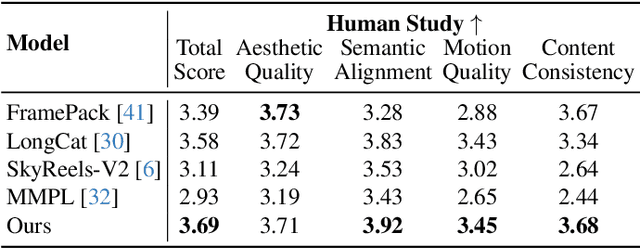
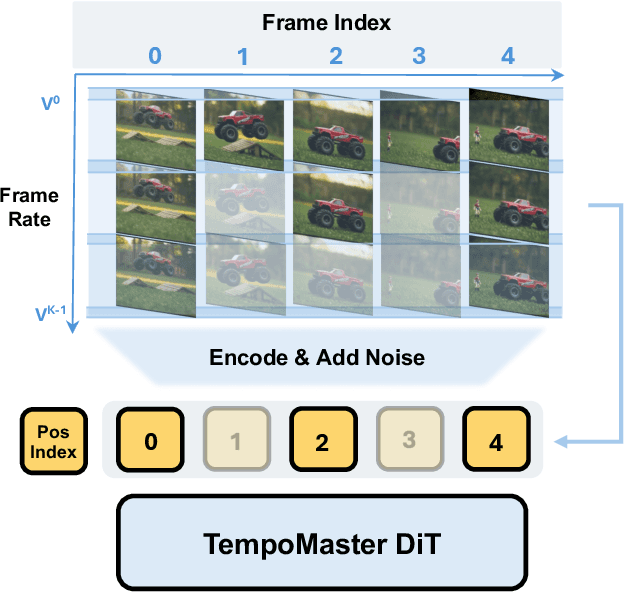
We present TempoMaster, a novel framework that formulates long video generation as next-frame-rate prediction. Specifically, we first generate a low-frame-rate clip that serves as a coarse blueprint of the entire video sequence, and then progressively increase the frame rate to refine visual details and motion continuity. During generation, TempoMaster employs bidirectional attention within each frame-rate level while performing autoregression across frame rates, thus achieving long-range temporal coherence while enabling efficient and parallel synthesis. Extensive experiments demonstrate that TempoMaster establishes a new state-of-the-art in long video generation, excelling in both visual and temporal quality.
Information Capacity: Evaluating the Efficiency of Large Language Models via Text Compression
Nov 13, 2025Recent years have witnessed the rapid advancements of large language models (LLMs) and their expanding applications, leading to soaring demands for computational resources. The widespread adoption of test-time scaling further aggravates the tension between model capability and resource consumption, highlighting the importance of inference efficiency. However, a unified metric that accurately reflects an LLM's efficiency across different model sizes and architectures remains absent. Motivated by the correlation between compression and intelligence, we introduce information capacity, a measure of model efficiency based on text compression performance relative to computational complexity. Larger models can predict the next token more accurately, achieving greater compression gains but at higher computational costs. Empirical evaluations on mainstream open-source models show that models of varying sizes within a series exhibit consistent information capacity. This metric enables a fair efficiency comparison across model series and accurate performance prediction within a model series. A distinctive feature of information capacity is that it incorporates tokenizer efficiency, which affects both input and output token counts but is often neglected in LLM evaluations. We assess the information capacity of 49 models on 5 heterogeneous datasets and observe consistent results on the influences of tokenizer efficiency, pretraining data, and the mixture-of-experts architecture.
ScRPO: From Errors to Insights
Nov 11, 2025We propose Self-correction Relative Policy Optimization (ScRPO), a novel reinforcement learning framework designed to enhance large language models on challenging mathematical problems by leveraging self-reflection and error correction. Our approach consists of two stages: (1) Trial-and-error learning stage: training the model with GRPO and collecting incorrect answers along with their corresponding questions in an error pool; (2) Self-correction learning stage: guiding the model to reflect on why its previous answers were wrong. Extensive experiments across multiple math reasoning benchmarks, including AIME, AMC, Olympiad, MATH-500, GSM8k, using Deepseek-Distill-Qwen-1.5B and Deepseek-Distill-Qwen-7B. The experimental results demonstrate that ScRPO consistently outperforms several post-training methods. These findings highlight ScRPO as a promising paradigm for enabling language models to self-improve on difficult tasks with limited external feedback, paving the way toward more reliable and capable AI systems.
On Selecting Few-Shot Examples for LLM-based Code Vulnerability Detection
Oct 31, 2025Large language models (LLMs) have demonstrated impressive capabilities for many coding tasks, including summarization, translation, completion, and code generation. However, detecting code vulnerabilities remains a challenging task for LLMs. An effective way to improve LLM performance is in-context learning (ICL) - providing few-shot examples similar to the query, along with correct answers, can improve an LLM's ability to generate correct solutions. However, choosing the few-shot examples appropriately is crucial to improving model performance. In this paper, we explore two criteria for choosing few-shot examples for ICL used in the code vulnerability detection task. The first criterion considers if the LLM (consistently) makes a mistake or not on a sample with the intuition that LLM performance on a sample is informative about its usefulness as a few-shot example. The other criterion considers similarity of the examples with the program under query and chooses few-shot examples based on the $k$-nearest neighbors to the given sample. We perform evaluations to determine the benefits of these criteria individually as well as under various combinations, using open-source models on multiple datasets.
Morphology-Aware Graph Reinforcement Learning for Tensegrity Robot Locomotion
Oct 30, 2025Tensegrity robots combine rigid rods and elastic cables, offering high resilience and deployability but posing major challenges for locomotion control due to their underactuated and highly coupled dynamics. This paper introduces a morphology-aware reinforcement learning framework that integrates a graph neural network (GNN) into the Soft Actor-Critic (SAC) algorithm. By representing the robot's physical topology as a graph, the proposed GNN-based policy captures coupling among components, enabling faster and more stable learning than conventional multilayer perceptron (MLP) policies. The method is validated on a physical 3-bar tensegrity robot across three locomotion primitives, including straight-line tracking and bidirectional turning. It shows superior sample efficiency, robustness to noise and stiffness variations, and improved trajectory accuracy. Notably, the learned policies transfer directly from simulation to hardware without fine-tuning, achieving stable real-world locomotion. These results demonstrate the advantages of incorporating structural priors into reinforcement learning for tensegrity robot control.
Cross-View UAV Geo-Localization with Precision-Focused Efficient Design: A Hierarchical Distillation Approach with Multi-view Refinement
Oct 26, 2025Cross-view geo-localization (CVGL) enables UAV localization by matching aerial images to geo-tagged satellite databases, which is critical for autonomous navigation in GNSS-denied environments. However, existing methods rely on resource-intensive fine-grained feature extraction and alignment, where multiple branches and modules significantly increase inference costs, limiting their deployment on edge devices. We propose Precision-Focused Efficient Design (PFED), a resource-efficient framework combining hierarchical knowledge transfer and multi-view representation refinement. This innovative method comprises two key components: 1) During training, Hierarchical Distillation paradigm for fast and accurate CVGL (HD-CVGL), coupled with Uncertainty-Aware Prediction Alignment (UAPA) to distill essential information and mitigate the data imbalance without incurring additional inference overhead. 2) During inference, an efficient Multi-view Refinement Module (MRM) leverages mutual information to filter redundant samples and effectively utilize the multi-view data. Extensive experiments show that PFED achieves state-of-the-art performance in both accuracy and efficiency, reaching 97.15\% Recall@1 on University-1652 while being over $5 \times$ more efficient in FLOPs and $3 \times$ faster than previous top methods. Furthermore, PFED runs at 251.5 FPS on the AGX Orin edge device, demonstrating its practical viability for real-time UAV applications. The project is available at https://github.com/SkyEyeLoc/PFED
FAPO: Flawed-Aware Policy Optimization for Efficient and Reliable Reasoning
Oct 26, 2025Reinforcement learning with verifiable rewards (RLVR) has emerged as a promising paradigm for enhancing the reasoning capabilities of large language models (LLMs). In this context, models explore reasoning trajectories and exploit rollouts with correct answers as positive signals for policy optimization. However, these rollouts might involve flawed patterns such as answer-guessing and jump-in-reasoning. Such flawed-positive rollouts are rewarded identically to fully correct ones, causing policy models to internalize these unreliable reasoning patterns. In this work, we first conduct a systematic study of flawed-positive rollouts in RL and find that they enable rapid capability gains during the early optimization stage, while constraining reasoning capability later by reinforcing unreliable patterns. Building on these insights, we propose Flawed-Aware Policy Optimization (FAPO), which presents a parameter-free reward penalty for flawed-positive rollouts, enabling the policy to leverage them as useful shortcuts in the warm-up stage, securing stable early gains, while gradually shifting optimization toward reliable reasoning in the later refinement stage. To accurately and comprehensively detect flawed-positive rollouts, we introduce a generative reward model (GenRM) with a process-level reward that precisely localizes reasoning errors. Experiments show that FAPO is effective in broad domains, improving outcome correctness, process reliability, and training stability without increasing the token budget.
Laminar: A Scalable Asynchronous RL Post-Training Framework
Oct 14, 2025Reinforcement learning (RL) post-training for Large Language Models (LLMs) is now scaling to large clusters and running for extended durations to enhance model reasoning performance. However, the scalability of existing RL frameworks is limited, as extreme long-tail skewness in RL trajectory generation causes severe GPU underutilization. Current asynchronous RL systems attempt to mitigate this, but they rely on global weight synchronization between the actor and all rollouts, which creates a rigid model update schedule. This global synchronization is ill-suited for the highly skewed and evolving distribution of trajectory generation latency in RL training, crippling training efficiency. Our key insight is that efficient scaling requires breaking this lockstep through trajectory-level asynchrony, which generates and consumes each trajectory independently. We propose Laminar, a scalable and robust RL post-training system built on a fully decoupled architecture. First, we replace global updates with a tier of relay workers acting as a distributed parameter service. This enables asynchronous and fine-grained weight synchronization, allowing rollouts to pull the latest weight anytime without stalling the actor's training loop. Second, a dynamic repack mechanism consolidates long-tail trajectories onto a few dedicated rollouts, maximizing generation throughput. The fully decoupled design also isolates failures, ensuring robustness for long-running jobs. Our evaluation on a 1024-GPU cluster shows that Laminar achieves up to 5.48$\times$ training throughput speedup over state-of-the-art systems, while reducing model convergence time.
Aixel: A Unified, Adaptive and Extensible System for AI-powered Data Analysis
Oct 14, 2025A growing trend in modern data analysis is the integration of data management with learning, guided by accuracy, latency, and cost requirements. In practice, applications draw data of different formats from many sources. In the meanwhile, the objectives and budgets change over time. Existing systems handle these applications across databases, analysis libraries, and tuning services. Such fragmentation leads to complex user interaction, limited adaptability, suboptimal performance, and poor extensibility across components. To address these challenges, we present Aixel, a unified, adaptive, and extensible system for AI-powered data analysis. The system organizes work across four layers: application, task, model, and data. The task layer provides a declarative interface to capture user intent, which is parsed into an executable operator plan. An optimizer compiles and schedules this plan to meet specified goals in accuracy, latency, and cost. The task layer coordinates the execution of data and model operators, with built-in support for reuse and caching to improve efficiency. The model layer offers versioned storage for index, metadata, tensors, and model artifacts. It supports adaptive construction, task-aligned drift detection, and safe updates that reuse shared components. The data layer provides unified data management capabilities, including indexing, constraint-aware discovery, task-aligned selection, and comprehensive feature management. With the above designed layers, Aixel delivers a user friendly, adaptive, efficient, and extensible system.