 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaint-Style Vulnerability Detection and Confirmation for Node.js Packages Using LLM Agent Reasoning
Apr 22, 2026The rapidly evolving Node$.$js ecosystem currently includes millions of packages and is a critical part of modern software supply chains, making vulnerability detection of Node$.$js packages increasingly important. However, traditional program analysis struggles in this setting because of dynamic JavaScript features and the large number of package dependencies. Recent advances in large language models (LLMs) and the emerging paradigm of LLM-based agents offer an alternative to handcrafted program models. This raises the question of whether an LLM-centric, tool-augmented approach can effectively detect and confirm taint-style vulnerabilities (e.g., arbitrary command injection) in Node$.$js packages. We implement LLMVD$.$js, a multi-stage agent pipeline to scan code, propose vulnerabilities, generate proof-of-concept exploits, and validate them through lightweight execution oracles; and systematically evaluate its effectiveness in taint-style vulnerability detection and confirmation in Node$.$js packages without dedicated static/dynamic analysis engines for path derivation. For packages from public benchmarks, LLMVD$.$js confirms 84% of the vulnerabilities, compared to less than 22% for prior program analysis tools. It also outperforms a prior LLM-program-analysis hybrid approach while requiring neither vulnerability annotations nor prior vulnerability reports. When evaluated on a set of 260 recently released packages (without vulnerability groundtruth information), traditional tools produce validated exploits for few ($\leq 2$) packages, while LLMVD$.$js generates validated exploits for 36 packages.
On Selecting Few-Shot Examples for LLM-based Code Vulnerability Detection
Oct 31, 2025Large language models (LLMs) have demonstrated impressive capabilities for many coding tasks, including summarization, translation, completion, and code generation. However, detecting code vulnerabilities remains a challenging task for LLMs. An effective way to improve LLM performance is in-context learning (ICL) - providing few-shot examples similar to the query, along with correct answers, can improve an LLM's ability to generate correct solutions. However, choosing the few-shot examples appropriately is crucial to improving model performance. In this paper, we explore two criteria for choosing few-shot examples for ICL used in the code vulnerability detection task. The first criterion considers if the LLM (consistently) makes a mistake or not on a sample with the intuition that LLM performance on a sample is informative about its usefulness as a few-shot example. The other criterion considers similarity of the examples with the program under query and chooses few-shot examples based on the $k$-nearest neighbors to the given sample. We perform evaluations to determine the benefits of these criteria individually as well as under various combinations, using open-source models on multiple datasets.
Learning to Triage Taint Flows Reported by Dynamic Program Analysis in Node.js Packages
Oct 23, 2025



Program analysis tools often produce large volumes of candidate vulnerability reports that require costly manual review, creating a practical challenge: how can security analysts prioritize the reports most likely to be true vulnerabilities? This paper investigates whether machine learning can be applied to prioritizing vulnerabilities reported by program analysis tools. We focus on Node.js packages and collect a benchmark of 1,883 Node.js packages, each containing one reported ACE or ACI vulnerability. We evaluate a variety of machine learning approaches, including classical models, graph neural networks (GNNs), large language models (LLMs), and hybrid models that combine GNN and LLMs, trained on data based on a dynamic program analysis tool's output. The top LLM achieves $F_{1} {=} 0.915$, while the best GNN and classical ML models reaching $F_{1} {=} 0.904$. At a less than 7% false-negative rate, the leading model eliminates 66.9% of benign packages from manual review, taking around 60 ms per package. If the best model is tuned to operate at a precision level of 0.8 (i.e., allowing 20% false positives amongst all warnings), our approach can detect 99.2% of exploitable taint flows while missing only 0.8%, demonstrating strong potential for real-world vulnerability triage.
Mixture-of-Linear-Experts for Long-term Time Series Forecasting
Dec 11, 2023



Long-term time series forecasting (LTSF) aims to predict future values of a time series given the past values. The current state-of-the-art (SOTA) on this problem is attained in some cases by linear-centric models, which primarily feature a linear mapping layer. However, due to their inherent simplicity, they are not able to adapt their prediction rules to periodic changes in time series patterns. To address this challenge, we propose a Mixture-of-Experts-style augmentation for linear-centric models and propose Mixture-of-Linear-Experts (MoLE). Instead of training a single model, MoLE trains multiple linear-centric models (i.e., experts) and a router model that weighs and mixes their outputs. While the entire framework is trained end-to-end, each expert learns to specialize in a specific temporal pattern, and the router model learns to compose the experts adaptively. Experiments show that MoLE reduces forecasting error of linear-centric models, including DLinear, RLinear, and RMLP, in over 78% of the datasets and settings we evaluated. By using MoLE existing linear-centric models can achieve SOTA LTSF results in 68% of the experiments that PatchTST reports and we compare to, whereas existing single-head linear-centric models achieve SOTA results in only 25% of cases. Additionally, MoLE models achieve SOTA in all settings for the newly released Weather2K datasets.
Computer-Aided Clinical Skin Disease Diagnosis Using CNN and Object Detection Models
Nov 20, 2019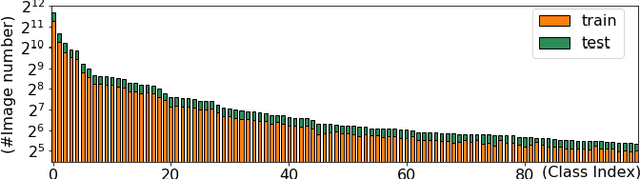
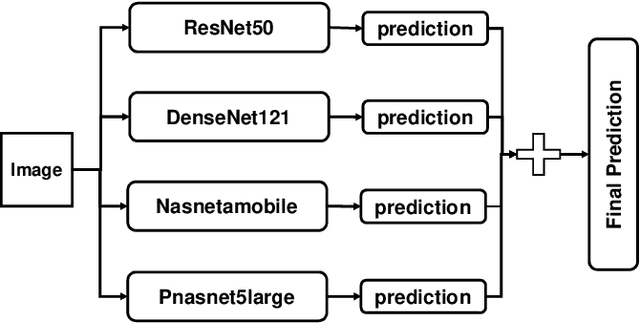
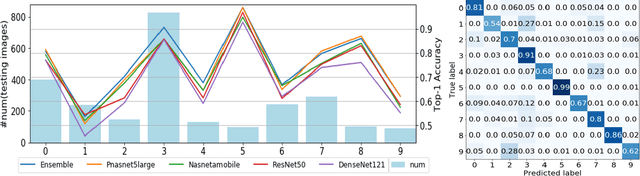
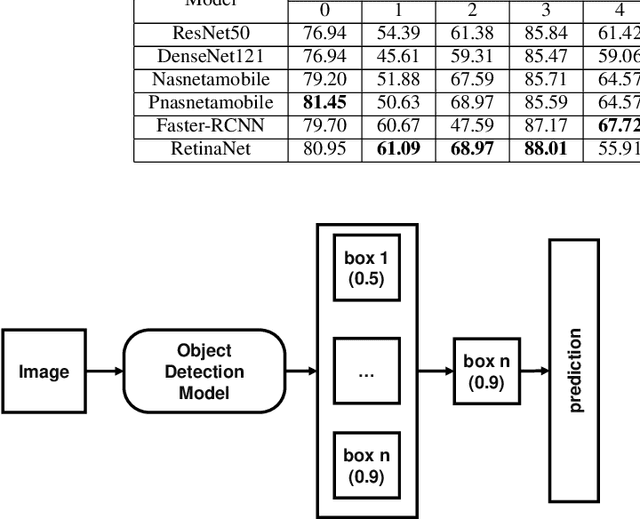
Skin disease is one of the most common types of human diseases, which may happen to everyone regardless of age, gender or race. Due to the high visual diversity, human diagnosis highly relies on personal experience; and there is a serious shortage of experienced dermatologists in many countries. To alleviate this problem, computer-aided diagnosis with state-of-the-art (SOTA) machine learning techniques would be a promising solution. In this paper, we aim at understanding the performance of convolutional neural network (CNN) based approaches. We first build two versions of skin disease datasets from Internet images: (a) Skin-10, which contains 10 common classes of skin disease with a total of 10,218 images; (b) Skin-100, which is a larger dataset that consists of 19,807 images of 100 skin disease classes. Based on these datasets, we benchmark several SOTA CNN models and show that the accuracy of skin-100 is much lower than the accuracy of skin-10. We then implement an ensemble method based on several CNN models and achieve the best accuracy of 79.01\% for Skin-10 and 53.54\% for Skin-100. We also present an object detection based approach by introducing bounding boxes into the Skin-10 dataset. Our results show that object detection can help improve the accuracy of some skin disease classes.