 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Visual Scene Graphs to Image Captions
May 05, 2023



We propose to Transform Scene Graphs (TSG) into more descriptive captions. In TSG, we apply multi-head attention (MHA) to design the Graph Neural Network (GNN) for embedding scene graphs. After embedding, different graph embeddings contain diverse specific knowledge for generating the words with different part-of-speech, e.g., object/attribute embedding is good for generating nouns/adjectives. Motivated by this, we design a Mixture-of-Expert (MOE)-based decoder, where each expert is built on MHA, for discriminating the graph embeddings to generate different kinds of words. Since both the encoder and decoder are built based on the MHA, as a result, we construct a homogeneous encoder-decoder unlike the previous heterogeneous ones which usually apply Fully-Connected-based GNN and LSTM-based decoder. The homogeneous architecture enables us to unify the training configuration of the whole model instead of specifying different training strategies for diverse sub-networks as in the heterogeneous pipeline, which releases the training difficulty. Extensive experiments on the MS-COCO captioning benchmark validate the effectiveness of our TSG. The code is in: https://anonymous.4open.science/r/ACL23_TSG.
ChatPLUG: Open-Domain Generative Dialogue System with Internet-Augmented Instruction Tuning for Digital Human
Apr 28, 2023



In this paper, we present ChatPLUG, a Chinese open-domain dialogue system for digital human applications that instruction finetunes on a wide range of dialogue tasks in a unified internet-augmented format. Different from other open-domain dialogue models that focus on large-scale pre-training and scaling up model size or dialogue corpus, we aim to build a powerful and practical dialogue system for digital human with diverse skills and good multi-task generalization by internet-augmented instruction tuning. To this end, we first conduct large-scale pre-training on both common document corpus and dialogue data with curriculum learning, so as to inject various world knowledge and dialogue abilities into ChatPLUG. Then, we collect a wide range of dialogue tasks spanning diverse features of knowledge, personality, multi-turn memory, and empathy, on which we further instruction tune \modelname via unified natural language instruction templates. External knowledge from an internet search is also used during instruction finetuning for alleviating the problem of knowledge hallucinations. We show that \modelname outperforms state-of-the-art Chinese dialogue systems on both automatic and human evaluation, and demonstrates strong multi-task generalization on a variety of text understanding and generation tasks. In addition, we deploy \modelname to real-world applications such as Smart Speaker and Instant Message applications with fast inference. Our models and code will be made publicly available on ModelScope~\footnote{\small{https://modelscope.cn/models/damo/ChatPLUG-3.7B}} and Github~\footnote{\small{https://github.com/X-PLUG/ChatPLUG}}.
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Apr 27, 2023



Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
On the Robustness of Aspect-based Sentiment Analysis: Rethinking Model, Data, and Training
Apr 19, 2023Aspect-based sentiment analysis (ABSA) aims at automatically inferring the specific sentiment polarities toward certain aspects of products or services behind the social media texts or reviews, which has been a fundamental application to the real-world society. Since the early 2010s, ABSA has achieved extraordinarily high accuracy with various deep neural models. However, existing ABSA models with strong in-house performances may fail to generalize to some challenging cases where the contexts are variable, i.e., low robustness to real-world environments. In this study, we propose to enhance the ABSA robustness by systematically rethinking the bottlenecks from all possible angles, including model, data, and training. First, we strengthen the current best-robust syntax-aware models by further incorporating the rich external syntactic dependencies and the labels with aspect simultaneously with a universal-syntax graph convolutional network. In the corpus perspective, we propose to automatically induce high-quality synthetic training data with various types, allowing models to learn sufficient inductive bias for better robustness. Last, we based on the rich pseudo data perform adversarial training to enhance the resistance to the context perturbation and meanwhile employ contrastive learning to reinforce the representations of instances with contrastive sentiments. Extensive robustness evaluations are conducted. The results demonstrate that our enhanced syntax-aware model achieves better robustness performances than all the state-of-the-art baselines. By additionally incorporating our synthetic corpus, the robust testing results are pushed with around 10% accuracy, which are then further improved by installing the advanced training strategies. In-depth analyses are presented for revealing the factors influencing the ABSA robustness.
DiffuRec: A Diffusion Model for Sequential Recommendation
Apr 09, 2023



Mainstream solutions to Sequential Recommendation (SR) represent items with fixed vectors. These vectors have limited capability in capturing items' latent aspects and users' diverse preferences. As a new generative paradigm, Diffusion models have achieved excellent performance in areas like computer vision and natural language processing. To our understanding, its unique merit in representation generation well fits the problem setting of sequential recommendation. In this paper, we make the very first attempt to adapt Diffusion model to SR and propose DiffuRec, for item representation construction and uncertainty injection. Rather than modeling item representations as fixed vectors, we represent them as distributions in DiffuRec, which reflect user's multiple interests and item's various aspects adaptively. In diffusion phase, DiffuRec corrupts the target item embedding into a Gaussian distribution via noise adding, which is further applied for sequential item distribution representation generation and uncertainty injection. Afterwards, the item representation is fed into an Approximator for target item representation reconstruction. In reversion phase, based on user's historical interaction behaviors, we reverse a Gaussian noise into the target item representation, then apply rounding operation for target item prediction. Experiments over four datasets show that DiffuRec outperforms strong baselines by a large margin.
Understanding Expertise through Demonstrations: A Maximum Likelihood Framework for Offline Inverse Reinforcement Learning
Feb 15, 2023



Offline inverse reinforcement learning (Offline IRL) aims to recover the structure of rewards and environment dynamics that underlie observed actions in a fixed, finite set of demonstrations from an expert agent. Accurate models of expertise in executing a task has applications in safety-sensitive applications such as clinical decision making and autonomous driving. However, the structure of an expert's preferences implicit in observed actions is closely linked to the expert's model of the environment dynamics (i.e. the ``world''). Thus, inaccurate models of the world obtained from finite data with limited coverage could compound inaccuracy in estimated rewards. To address this issue, we propose a bi-level optimization formulation of the estimation task wherein the upper level is likelihood maximization based upon a conservative model of the expert's policy (lower level). The policy model is conservative in that it maximizes reward subject to a penalty that is increasing in the uncertainty of the estimated model of the world. We propose a new algorithmic framework to solve the bi-level optimization problem formulation and provide statistical and computational guarantees of performance for the associated reward estimator. Finally, we demonstrate that the proposed algorithm outperforms the state-of-the-art offline IRL and imitation learning benchmarks by a large margin, over the continuous control tasks in MuJoCo and different datasets in the D4RL benchmark.
mPLUG-2: A Modularized Multi-modal Foundation Model Across Text, Image and Video
Feb 01, 2023



Recent years have witnessed a big convergence of language, vision, and multi-modal pretraining. In this work, we present mPLUG-2, a new unified paradigm with modularized design for multi-modal pretraining, which can benefit from modality collaboration while addressing the problem of modality entanglement. In contrast to predominant paradigms of solely relying on sequence-to-sequence generation or encoder-based instance discrimination, mPLUG-2 introduces a multi-module composition network by sharing common universal modules for modality collaboration and disentangling different modality modules to deal with modality entanglement. It is flexible to select different modules for different understanding and generation tasks across all modalities including text, image, and video. Empirical study shows that mPLUG-2 achieves state-of-the-art or competitive results on a broad range of over 30 downstream tasks, spanning multi-modal tasks of image-text and video-text understanding and generation, and uni-modal tasks of text-only, image-only, and video-only understanding. Notably, mPLUG-2 shows new state-of-the-art results of 48.0 top-1 accuracy and 80.3 CIDEr on the challenging MSRVTT video QA and video caption tasks with a far smaller model size and data scale. It also demonstrates strong zero-shot transferability on vision-language and video-language tasks. Code and models will be released in https://github.com/alibaba/AliceMind.
Learning Trajectory-Word Alignments for Video-Language Tasks
Jan 06, 2023



Aligning objects with words plays a critical role in Image-Language BERT (IL-BERT) and Video-Language BERT (VDL-BERT). Different from the image case where an object covers some spatial patches, an object in a video usually appears as an object trajectory, i.e., it spans over a few spatial but longer temporal patches and thus contains abundant spatiotemporal contexts. However, modern VDL-BERTs neglect this trajectory characteristic that they usually follow IL-BERTs to deploy the patch-to-word (P2W) attention while such attention may over-exploit trivial spatial contexts and neglect significant temporal contexts. To amend this, we propose a novel TW-BERT to learn Trajectory-Word alignment for solving video-language tasks. Such alignment is learned by a newly designed trajectory-to-word (T2W) attention. Besides T2W attention, we also follow previous VDL-BERTs to set a word-to-patch (W2P) attention in the cross-modal encoder. Since T2W and W2P attentions have diverse structures, our cross-modal encoder is asymmetric. To further help this asymmetric cross-modal encoder build robust vision-language associations, we propose a fine-grained ``align-before-fuse'' strategy to pull close the embedding spaces calculated by the video and text encoders. By the proposed strategy and T2W attention, our TW-BERT achieves SOTA performances on text-to-video retrieval tasks, and comparable performances on video question answering tasks with some VDL-BERTs trained on much more data. The code will be available in the supplementary material.
Adaptively Clustering Neighbor Elements for Image Captioning
Jan 05, 2023We design a novel global-local Transformer named \textbf{Ada-ClustFormer} (\textbf{ACF}) to generate captions. We use this name since each layer of ACF can adaptively cluster input elements to carry self-attention (Self-ATT) for learning local context. Compared with other global-local Transformers which carry Self-ATT in fixed-size windows, ACF can capture varying graininess, \eg, an object may cover different numbers of grids or a phrase may contain diverse numbers of words. To build ACF, we insert a probabilistic matrix C into the Self-ATT layer. For an input sequence {{s}_1,...,{s}_N , C_{i,j} softly determines whether the sub-sequence {s_i,...,s_j} should be clustered for carrying Self-ATT. For implementation, {C}_{i,j} is calculated from the contexts of {{s}_i,...,{s}_j}, thus ACF can exploit the input itself to decide which local contexts should be learned. By using ACF to build the vision encoder and language decoder, the captioning model can automatically discover the hidden structures in both vision and language, which encourages the model to learn a unified structural space for transferring more structural commonalities. The experiment results demonstrate the effectiveness of ACF that we achieve CIDEr of 137.8, which outperforms most SOTA captioning models and achieve comparable scores compared with some BERT-based models. The code will be available in the supplementary material.
Maximum-Likelihood Inverse Reinforcement Learning with Finite-Time Guarantees
Oct 04, 2022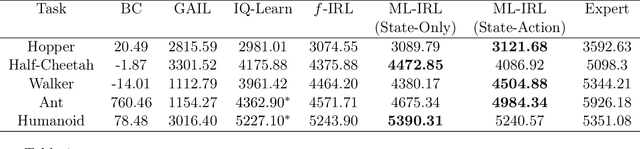

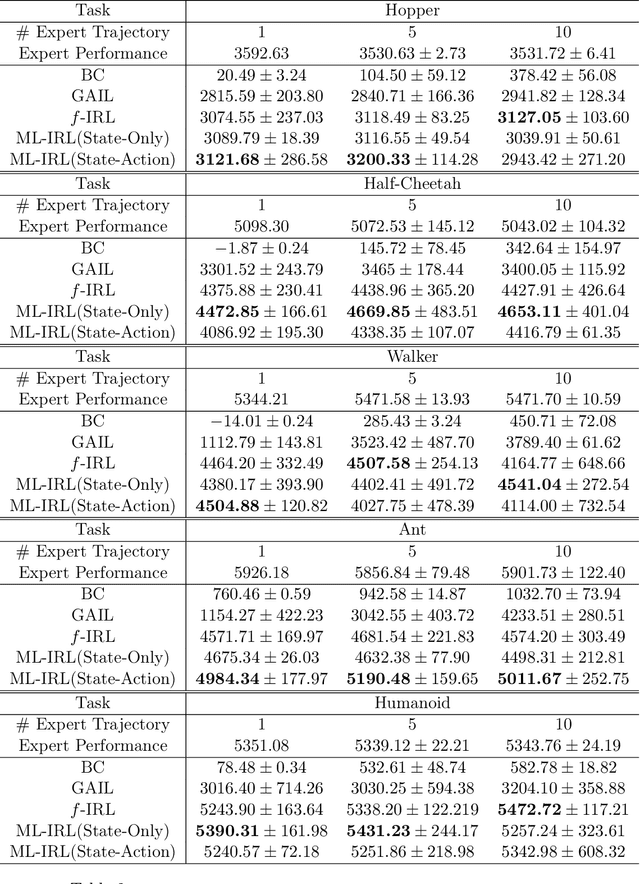
Inverse reinforcement learning (IRL) aims to recover the reward function and the associated optimal policy that best fits observed sequences of states and actions implemented by an expert. Many algorithms for IRL have an inherently nested structure: the inner loop finds the optimal policy given parametrized rewards while the outer loop updates the estimates towards optimizing a measure of fit. For high dimensional environments such nested-loop structure entails a significant computational burden. To reduce the computational burden of a nested loop, novel methods such as SQIL [1] and IQ-Learn [2] emphasize policy estimation at the expense of reward estimation accuracy. However, without accurate estimated rewards, it is not possible to do counterfactual analysis such as predicting the optimal policy under different environment dynamics and/or learning new tasks. In this paper we develop a novel single-loop algorithm for IRL that does not compromise reward estimation accuracy. In the proposed algorithm, each policy improvement step is followed by a stochastic gradient step for likelihood maximization. We show that the proposed algorithm provably converges to a stationary solution with a finite-time guarantee. If the reward is parameterized linearly, we show the identified solution corresponds to the solution of the maximum entropy IRL problem. Finally, by using robotics control problems in MuJoCo and their transfer settings, we show that the proposed algorithm achieves superior performance compared with other IRL and imitation learning benchmarks.