 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing fine-tuning and min lookahead beam search to improve Whisper
Sep 19, 2023



The performance of Whisper in low-resource languages is still far from perfect. In addition to a lack of training data on low-resource languages, we identify some limitations in the beam search algorithm used in Whisper. To address these issues, we fine-tune Whisper on additional data and propose an improved decoding algorithm. On the Vietnamese language, fine-tuning Whisper-Tiny with LoRA leads to an improvement of 38.49 in WER over the zero-shot Whisper-Tiny setting which is a further reduction of 1.45 compared to full-parameter fine-tuning. Additionally, by using Filter-Ends and Min Lookahead decoding algorithms, the WER reduces by 2.26 on average over a range of languages compared to standard beam search. These results generalise to larger Whisper model sizes. We also prove a theorem that Min Lookahead outperforms the standard beam search algorithm used in Whisper.
Cross-Utterance Conditioned VAE for Speech Generation
Sep 08, 2023



Speech synthesis systems powered by neural networks hold promise for multimedia production, but frequently face issues with producing expressive speech and seamless editing. In response, we present the Cross-Utterance Conditioned Variational Autoencoder speech synthesis (CUC-VAE S2) framework to enhance prosody and ensure natural speech generation. This framework leverages the powerful representational capabilities of pre-trained language models and the re-expression abilities of variational autoencoders (VAEs). The core component of the CUC-VAE S2 framework is the cross-utterance CVAE, which extracts acoustic, speaker, and textual features from surrounding sentences to generate context-sensitive prosodic features, more accurately emulating human prosody generation. We further propose two practical algorithms tailored for distinct speech synthesis applications: CUC-VAE TTS for text-to-speech and CUC-VAE SE for speech editing. The CUC-VAE TTS is a direct application of the framework, designed to generate audio with contextual prosody derived from surrounding texts. On the other hand, the CUC-VAE SE algorithm leverages real mel spectrogram sampling conditioned on contextual information, producing audio that closely mirrors real sound and thereby facilitating flexible speech editing based on text such as deletion, insertion, and replacement. Experimental results on the LibriTTS datasets demonstrate that our proposed models significantly enhance speech synthesis and editing, producing more natural and expressive speech.
FaceChain: A Playground for Identity-Preserving Portrait Generation
Aug 28, 2023



Recent advancement in personalized image generation have unveiled the intriguing capability of pre-trained text-to-image models on learning identity information from a collection of portrait images. However, existing solutions can be vulnerable in producing truthful details, and usually suffer from several defects such as (i) The generated face exhibit its own unique characteristics, \ie facial shape and facial feature positioning may not resemble key characteristics of the input, and (ii) The synthesized face may contain warped, blurred or corrupted regions. In this paper, we present FaceChain, a personalized portrait generation framework that combines a series of customized image-generation model and a rich set of face-related perceptual understanding models (\eg, face detection, deep face embedding extraction, and facial attribute recognition), to tackle aforementioned challenges and to generate truthful personalized portraits, with only a handful of portrait images as input. Concretely, we inject several SOTA face models into the generation procedure, achieving a more efficient label-tagging, data-processing, and model post-processing compared to previous solutions, such as DreamBooth ~\cite{ruiz2023dreambooth} , InstantBooth ~\cite{shi2023instantbooth} , or other LoRA-only approaches ~\cite{hu2021lora} . Through the development of FaceChain, we have identified several potential directions to accelerate development of Face/Human-Centric AIGC research and application. We have designed FaceChain as a framework comprised of pluggable components that can be easily adjusted to accommodate different styles and personalized needs. We hope it can grow to serve the burgeoning needs from the communities. FaceChain is open-sourced under Apache-2.0 license at \url{https://github.com/modelscope/facechain}.
Cross-Utterance Conditioned VAE for Non-Autoregressive Text-to-Speech
May 09, 2022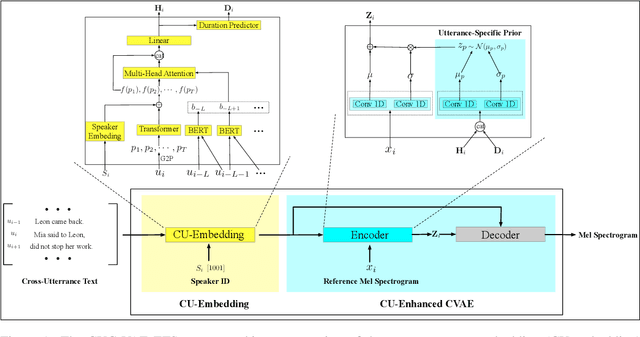
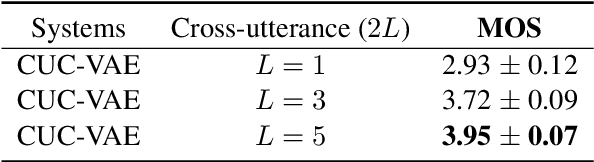

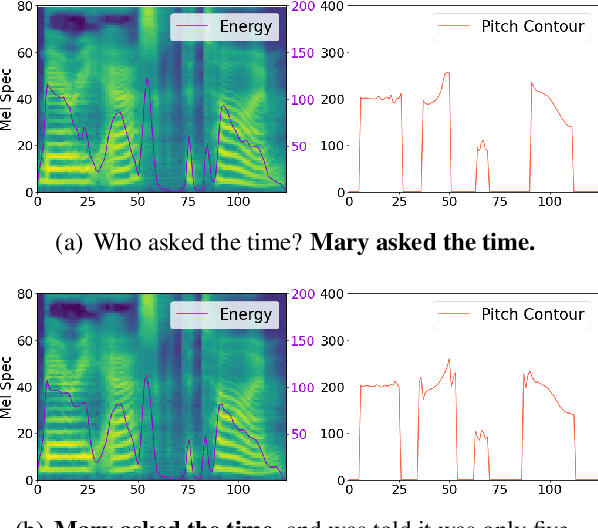
Modelling prosody variation is critical for synthesizing natural and expressive speech in end-to-end text-to-speech (TTS) systems. In this paper, a cross-utterance conditional VAE (CUC-VAE) is proposed to estimate a posterior probability distribution of the latent prosody features for each phoneme by conditioning on acoustic features, speaker information, and text features obtained from both past and future sentences. At inference time, instead of the standard Gaussian distribution used by VAE, CUC-VAE allows sampling from an utterance-specific prior distribution conditioned on cross-utterance information, which allows the prosody features generated by the TTS system to be related to the context and is more similar to how humans naturally produce prosody. The performance of CUC-VAE is evaluated via a qualitative listening test for naturalness, intelligibility and quantitative measurements, including word error rates and the standard deviation of prosody attributes. Experimental results on LJ-Speech and LibriTTS data show that the proposed CUC-VAE TTS system improves naturalness and prosody diversity with clear margins.
Perceptual Contrast Stretching on Target Feature for Speech Enhancement
Apr 01, 2022
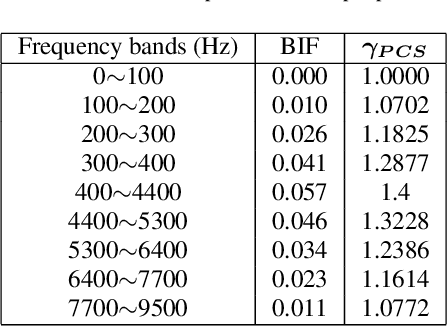
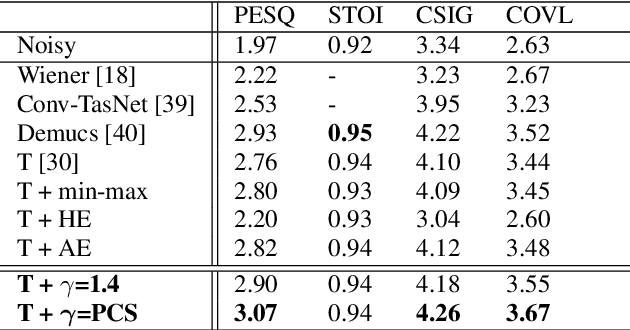
Speech enhancement (SE) performance has improved considerably since the use of deep learning (DL) models as a base function. In this study, we propose a perceptual contrast stretching (PCS) approach to further improve SE performance. PCS is derived based on the critical band importance function and applied to modify the targets of the SE model. Specifically, PCS stretches the contract of target features according to perceptual importance, thereby improving the overall SE performance. Compared to post-processing based implementations, incorporating PCS into the training phase preserves performance and reduces online computation. It is also worth noting that PCS can be suitably combined with different SE model architectures and training criteria. Meanwhile, PCS does not affect the causality or convergence of the SE model training. Experimental results on the VoiceBank-DEMAND dataset showed that the proposed method can achieve state-of-the-art performance on both causal (PESQ=3.07) and non-causal (PESQ=3.35) SE tasks.
Conditional Diffusion Probabilistic Model for Speech Enhancement
Feb 10, 2022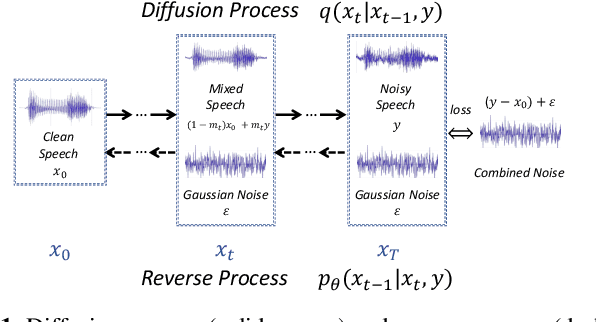
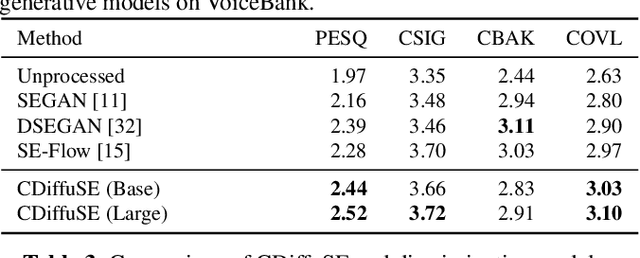
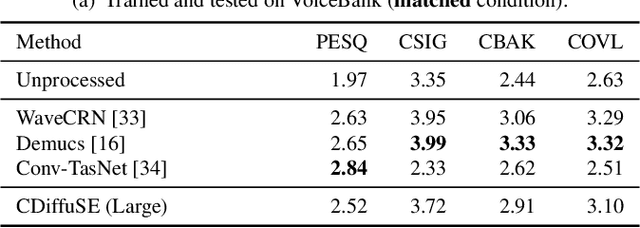
Speech enhancement is a critical component of many user-oriented audio applications, yet current systems still suffer from distorted and unnatural outputs. While generative models have shown strong potential in speech synthesis, they are still lagging behind in speech enhancement. This work leverages recent advances in diffusion probabilistic models, and proposes a novel speech enhancement algorithm that incorporates characteristics of the observed noisy speech signal into the diffusion and reverse processes. More specifically, we propose a generalized formulation of the diffusion probabilistic model named conditional diffusion probabilistic model that, in its reverse process, can adapt to non-Gaussian real noises in the estimated speech signal. In our experiments, we demonstrate strong performance of the proposed approach compared to representative generative models, and investigate the generalization capability of our models to other datasets with noise characteristics unseen during training.
OSSEM: one-shot speaker adaptive speech enhancement using meta learning
Nov 10, 2021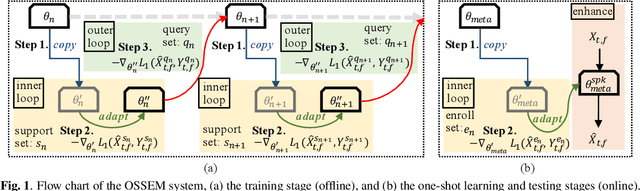
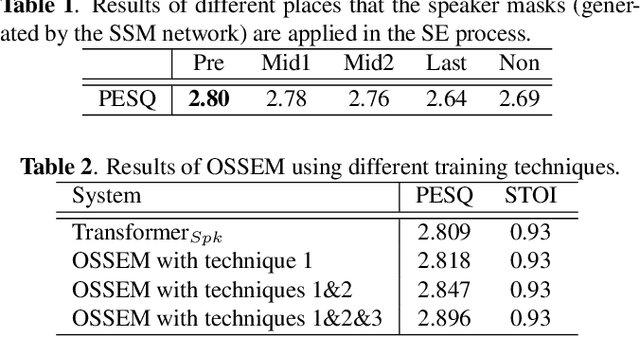
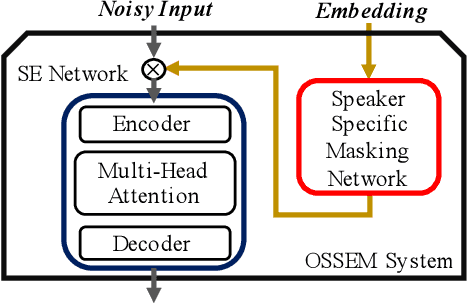
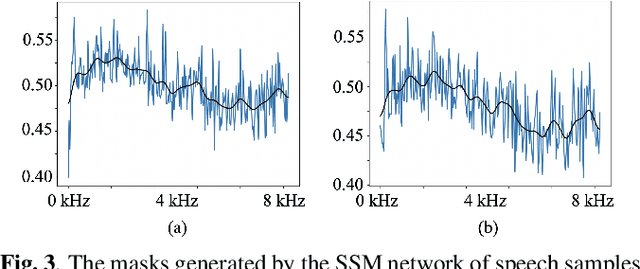
Although deep learning (DL) has achieved notable progress in speech enhancement (SE), further research is still required for a DL-based SE system to adapt effectively and efficiently to particular speakers. In this study, we propose a novel meta-learning-based speaker-adaptive SE approach (called OSSEM) that aims to achieve SE model adaptation in a one-shot manner. OSSEM consists of a modified transformer SE network and a speaker-specific masking (SSM) network. In practice, the SSM network takes an enrolled speaker embedding extracted using ECAPA-TDNN to adjust the input noisy feature through masking. To evaluate OSSEM, we designed a modified Voice Bank-DEMAND dataset, in which one utterance from the testing set was used for model adaptation, and the remaining utterances were used for testing the performance. Moreover, we set restrictions allowing the enhancement process to be conducted in real time, and thus designed OSSEM to be a causal SE system. Experimental results first show that OSSEM can effectively adapt a pretrained SE model to a particular speaker with only one utterance, thus yielding improved SE results. Meanwhile, OSSEM exhibits a competitive performance compared to state-of-the-art causal SE systems.
HASA-net: A non-intrusive hearing-aid speech assessment network
Nov 10, 2021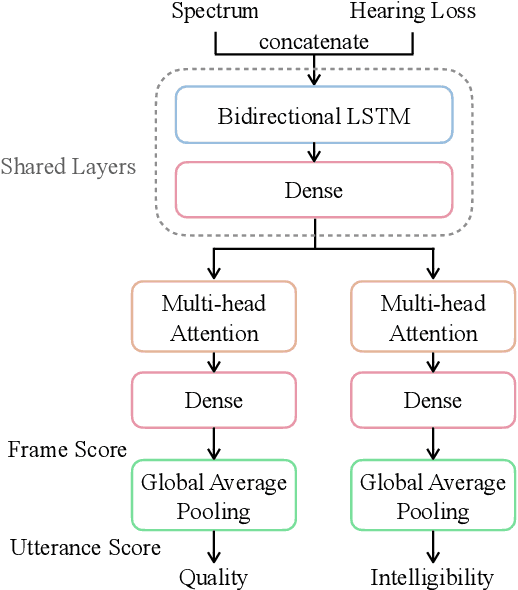
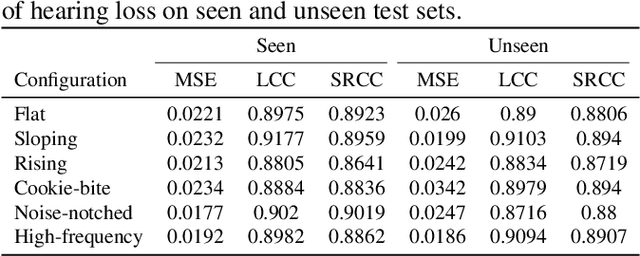
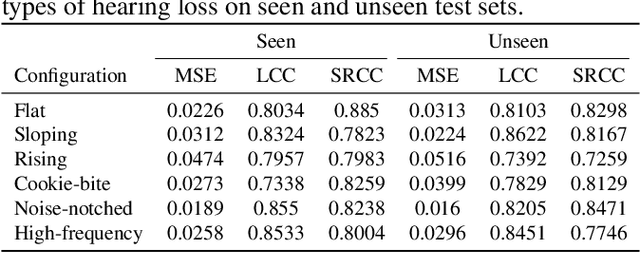
Without the need of a clean reference, non-intrusive speech assessment methods have caught great attention for objective evaluations. Recently, deep neural network (DNN) models have been applied to build non-intrusive speech assessment approaches and confirmed to provide promising performance. However, most DNN-based approaches are designed for normal-hearing listeners without considering hearing-loss factors. In this study, we propose a DNN-based hearing aid speech assessment network (HASA-Net), formed by a bidirectional long short-term memory (BLSTM) model, to predict speech quality and intelligibility scores simultaneously according to input speech signals and specified hearing-loss patterns. To the best of our knowledge, HASA-Net is the first work to incorporate quality and intelligibility assessments utilizing a unified DNN-based non-intrusive model for hearing aids. Experimental results show that the predicted speech quality and intelligibility scores of HASA-Net are highly correlated to two well-known intrusive hearing-aid evaluation metrics, hearing aid speech quality index (HASQI) and hearing aid speech perception index (HASPI), respectively.
SEOFP-NET: Compression and Acceleration of Deep Neural Networks for Speech Enhancement Using Sign-Exponent-Only Floating-Points
Nov 08, 2021
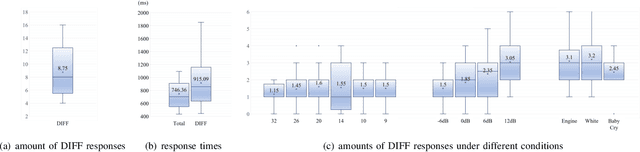
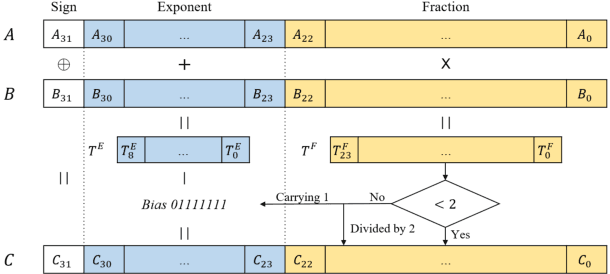
Numerous compression and acceleration strategies have achieved outstanding results on classification tasks in various fields, such as computer vision and speech signal processing. Nevertheless, the same strategies have yielded ungratified performance on regression tasks because the nature between these and classification tasks differs. In this paper, a novel sign-exponent-only floating-point network (SEOFP-NET) technique is proposed to compress the model size and accelerate the inference time for speech enhancement, a regression task of speech signal processing. The proposed method compressed the sizes of deep neural network (DNN)-based speech enhancement models by quantizing the fraction bits of single-precision floating-point parameters during training. Before inference implementation, all parameters in the trained SEOFP-NET model are slightly adjusted to accelerate the inference time by replacing the floating-point multiplier with an integer-adder. For generalization, the SEOFP-NET technique is introduced to different speech enhancement tasks in speech signal processing with different model architectures under various corpora. The experimental results indicate that the size of SEOFP-NET models can be significantly compressed by up to 81.249% without noticeably downgrading their speech enhancement performance, and the inference time can be accelerated to 1.212x compared with the baseline models. The results also verify that the proposed SEOFP-NET can cooperate with other efficiency strategies to achieve a synergy effect for model compression. In addition, the just noticeable difference (JND) was applied to the user study experiment to statistically analyze the effect of speech enhancement on listening. The results indicate that the listeners cannot facilely differentiate between the enhanced speech signals processed by the baseline model and the proposed SEOFP-NET.
MetricGAN-U: Unsupervised speech enhancement/ dereverberation based only on noisy/ reverberated speech
Oct 12, 2021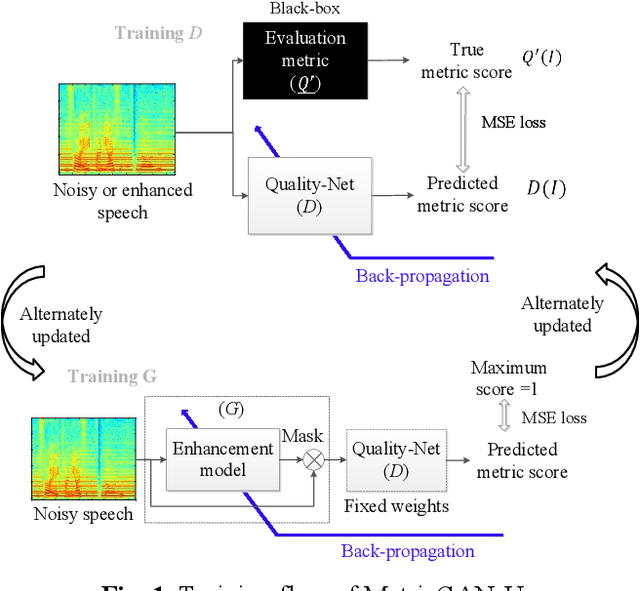
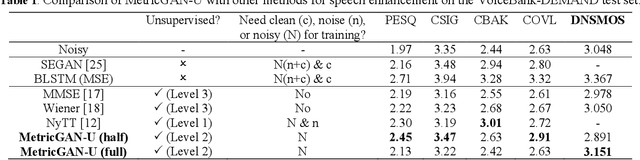
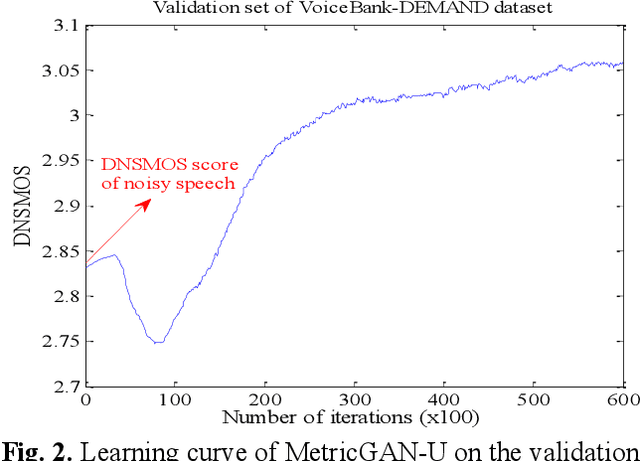
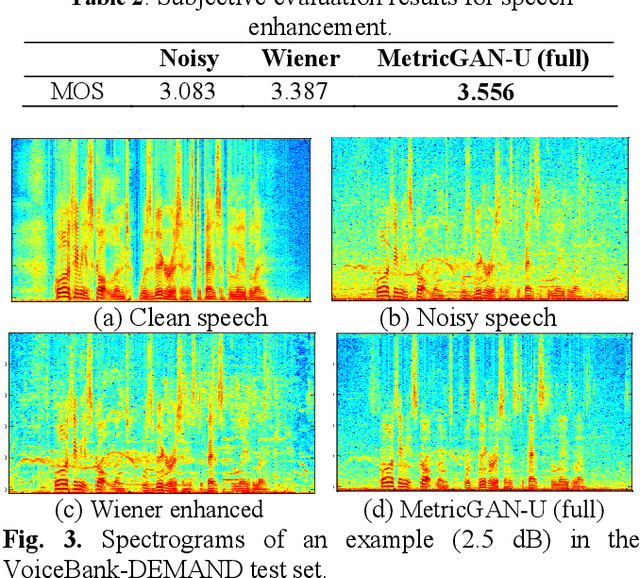
Most of the deep learning-based speech enhancement models are learned in a supervised manner, which implies that pairs of noisy and clean speech are required during training. Consequently, several noisy speeches recorded in daily life cannot be used to train the model. Although certain unsupervised learning frameworks have also been proposed to solve the pair constraint, they still require clean speech or noise for training. Therefore, in this paper, we propose MetricGAN-U, which stands for MetricGAN-unsupervised, to further release the constraint from conventional unsupervised learning. In MetricGAN-U, only noisy speech is required to train the model by optimizing non-intrusive speech quality metrics. The experimental results verified that MetricGAN-U outperforms baselines in both objective and subjective metrics.