 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Flow Matching for Visually-Guided Acoustic Highlighting
Feb 03, 2026Visually-guided acoustic highlighting seeks to rebalance audio in alignment with the accompanying video, creating a coherent audio-visual experience. While visual saliency and enhancement have been widely studied, acoustic highlighting remains underexplored, often leading to misalignment between visual and auditory focus. Existing approaches use discriminative models, which struggle with the inherent ambiguity in audio remixing, where no natural one-to-one mapping exists between poorly-balanced and well-balanced audio mixes. To address this limitation, we reframe this task as a generative problem and introduce a Conditional Flow Matching (CFM) framework. A key challenge in iterative flow-based generation is that early prediction errors -- in selecting the correct source to enhance -- compound over steps and push trajectories off-manifold. To address this, we introduce a rollout loss that penalizes drift at the final step, encouraging self-correcting trajectories and stabilizing long-range flow integration. We further propose a conditioning module that fuses audio and visual cues before vector field regression, enabling explicit cross-modal source selection. Extensive quantitative and qualitative evaluations show that our method consistently surpasses the previous state-of-the-art discriminative approach, establishing that visually-guided audio remixing is best addressed through generative modeling.
T-Mimi: A Transformer-based Mimi Decoder for Real-Time On-Phone TTS
Jan 27, 2026Neural audio codecs provide promising acoustic features for speech synthesis, with representative streaming codecs like Mimi providing high-quality acoustic features for real-time Text-to-Speech (TTS) applications. However, Mimi's decoder, which employs a hybrid transformer and convolution architecture, introduces significant latency bottlenecks on edge devices due to the the compute intensive nature of deconvolution layers which are not friendly for mobile-CPUs, such as the most representative framework XNNPACK. This paper introduces T-Mimi, a novel modification of the Mimi codec decoder that replaces its convolutional components with a purely transformer-based decoder, inspired by the TS3-Codec architecture. This change dramatically reduces on-device TTS latency from 42.1ms to just 4.4ms. Furthermore, we conduct quantization aware training and derive a crucial finding: the final two transformer layers and the concluding linear layers of the decoder, which are close to the waveform, are highly sensitive to quantization and must be preserved at full precision to maintain audio quality.
SAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
Jan 27, 2026The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
SAM Audio: Segment Anything in Audio
Dec 19, 2025



General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
FlowDec: A flow-based full-band general audio codec with high perceptual quality
Mar 03, 2025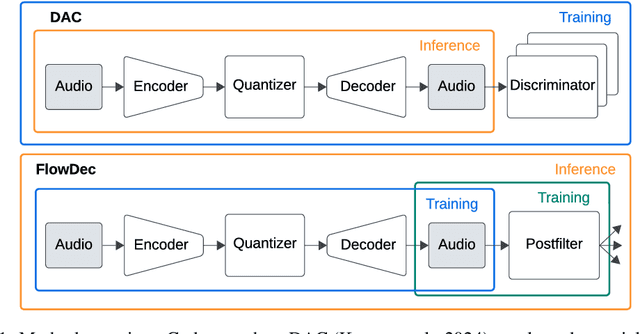
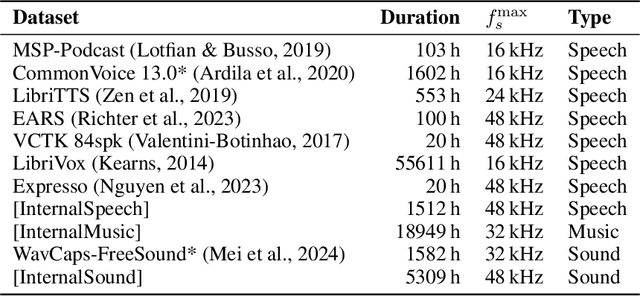

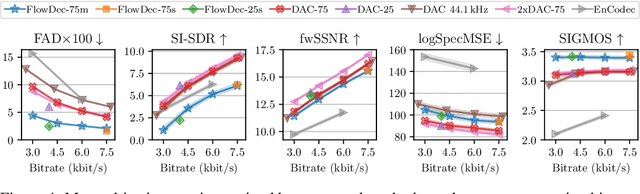
We propose FlowDec, a neural full-band audio codec for general audio sampled at 48 kHz that combines non-adversarial codec training with a stochastic postfilter based on a novel conditional flow matching method. Compared to the prior work ScoreDec which is based on score matching, we generalize from speech to general audio and move from 24 kbit/s to as low as 4 kbit/s, while improving output quality and reducing the required postfilter DNN evaluations from 60 to 6 without any fine-tuning or distillation techniques. We provide theoretical insights and geometric intuitions for our approach in comparison to ScoreDec as well as another recent work that uses flow matching, and conduct ablation studies on our proposed components. We show that FlowDec is a competitive alternative to the recent GAN-dominated stream of neural codecs, achieving FAD scores better than those of the established GAN-based codec DAC and listening test scores that are on par, and producing qualitatively more natural reconstructions for speech and harmonic structures in music.
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Feb 07, 2025



The quantification of audio aesthetics remains a complex challenge in audio processing, primarily due to its subjective nature, which is influenced by human perception and cultural context. Traditional methods often depend on human listeners for evaluation, leading to inconsistencies and high resource demands. This paper addresses the growing need for automated systems capable of predicting audio aesthetics without human intervention. Such systems are crucial for applications like data filtering, pseudo-labeling large datasets, and evaluating generative audio models, especially as these models become more sophisticated. In this work, we introduce a novel approach to audio aesthetic evaluation by proposing new annotation guidelines that decompose human listening perspectives into four distinct axes. We develop and train no-reference, per-item prediction models that offer a more nuanced assessment of audio quality. Our models are evaluated against human mean opinion scores (MOS) and existing methods, demonstrating comparable or superior performance. This research not only advances the field of audio aesthetics but also provides open-source models and datasets to facilitate future work and benchmarking. We release our code and pre-trained model at: https://github.com/facebookresearch/audiobox-aesthetics
ComplexDec: A Domain-robust High-fidelity Neural Audio Codec with Complex Spectrum Modeling
Feb 04, 2025



Neural audio codecs have been widely adopted in audio-generative tasks because their compact and discrete representations are suitable for both large-language-model-style and regression-based generative models. However, most neural codecs struggle to model out-of-domain audio, resulting in error propagations to downstream generative tasks. In this paper, we first argue that information loss from codec compression degrades out-of-domain robustness. Then, we propose full-band 48~kHz ComplexDec with complex spectral input and output to ease the information loss while adopting the same 24~kbps bitrate as the baseline AuidoDec and ScoreDec. Objective and subjective evaluations demonstrate the out-of-domain robustness of ComplexDec trained using only the 30-hour VCTK corpus.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
Codec-SUPERB @ SLT 2024: A lightweight benchmark for neural audio codec models
Sep 21, 2024



Neural audio codec models are becoming increasingly important as they serve as tokenizers for audio, enabling efficient transmission or facilitating speech language modeling. The ideal neural audio codec should maintain content, paralinguistics, speaker characteristics, and audio information even at low bitrates. Recently, numerous advanced neural codec models have been proposed. However, codec models are often tested under varying experimental conditions. As a result, we introduce the Codec-SUPERB challenge at SLT 2024, designed to facilitate fair and lightweight comparisons among existing codec models and inspire advancements in the field. This challenge brings together representative speech applications and objective metrics, and carefully selects license-free datasets, sampling them into small sets to reduce evaluation computation costs. This paper presents the challenge's rules, datasets, five participant systems, results, and findings.
EMO-Codec: An In-Depth Look at Emotion Preservation capacity of Legacy and Neural Codec Models With Subjective and Objective Evaluations
Jul 30, 2024



The neural codec model reduces speech data transmission delay and serves as the foundational tokenizer for speech language models (speech LMs). Preserving emotional information in codecs is crucial for effective communication and context understanding. However, there is a lack of studies on emotion loss in existing codecs. This paper evaluates neural and legacy codecs using subjective and objective methods on emotion datasets like IEMOCAP. Our study identifies which codecs best preserve emotional information under various bitrate scenarios. We found that training codec models with both English and Chinese data had limited success in retaining emotional information in Chinese. Additionally, resynthesizing speech through these codecs degrades the performance of speech emotion recognition (SER), particularly for emotions like sadness, depression, fear, and disgust. Human listening tests confirmed these findings. This work guides future speech technology developments to ensure new codecs maintain the integrity of emotional information in speech.