 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeri-R1: Toward Precise and Faithful Claim Verification via Online Reinforcement Learning
Oct 02, 2025



Claim verification with large language models (LLMs) has recently attracted considerable attention, owing to their superior reasoning capabilities and transparent verification pathways compared to traditional answer-only judgments. Online claim verification requires iterative evidence retrieval and reasoning, yet existing approaches mainly rely on prompt engineering or predesigned reasoning workflows without offering a unified training paradigm to improve necessary skills. Therefore, we introduce Veri-R1, an online reinforcement learning (RL) framework that enables an LLM to interact with a search engine and to receive reward signals that explicitly shape its planning, retrieval, and reasoning behaviors. The dynamic interaction between models and retrieval systems more accurately reflects real-world verification scenarios and fosters comprehensive verification skills. Empirical results show that Veri-R1 improves joint accuracy by up to 30% and doubles evidence score, often surpassing larger-scale counterparts. Ablation studies further reveal the impact of reward components and the link between output logits and label accuracy. Our results highlight the effectiveness of online RL for precise and faithful claim verification and provide a foundation for future research. We release our code to support community progress in LLM empowered claim verification.
LoCoBench: A Benchmark for Long-Context Large Language Models in Complex Software Engineering
Sep 11, 2025
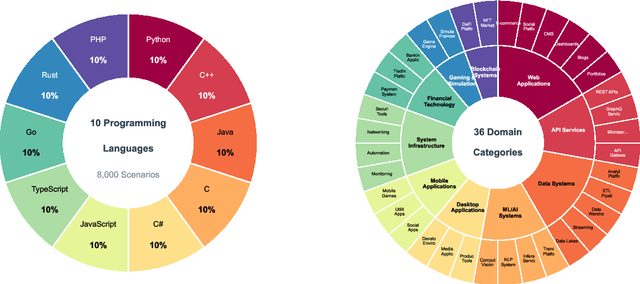

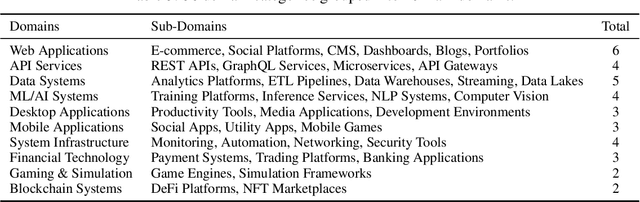
The emergence of long-context language models with context windows extending to millions of tokens has created new opportunities for sophisticated code understanding and software development evaluation. We propose LoCoBench, a comprehensive benchmark specifically designed to evaluate long-context LLMs in realistic, complex software development scenarios. Unlike existing code evaluation benchmarks that focus on single-function completion or short-context tasks, LoCoBench addresses the critical evaluation gap for long-context capabilities that require understanding entire codebases, reasoning across multiple files, and maintaining architectural consistency across large-scale software systems. Our benchmark provides 8,000 evaluation scenarios systematically generated across 10 programming languages, with context lengths spanning 10K to 1M tokens, a 100x variation that enables precise assessment of long-context performance degradation in realistic software development settings. LoCoBench introduces 8 task categories that capture essential long-context capabilities: architectural understanding, cross-file refactoring, multi-session development, bug investigation, feature implementation, code comprehension, integration testing, and security analysis. Through a 5-phase pipeline, we create diverse, high-quality scenarios that challenge LLMs to reason about complex codebases at unprecedented scale. We introduce a comprehensive evaluation framework with 17 metrics across 4 dimensions, including 8 new evaluation metrics, combined in a LoCoBench Score (LCBS). Our evaluation of state-of-the-art long-context models reveals substantial performance gaps, demonstrating that long-context understanding in complex software development represents a significant unsolved challenge that demands more attention. LoCoBench is released at: https://github.com/SalesforceAIResearch/LoCoBench.
ISACL: Internal State Analyzer for Copyrighted Training Data Leakage
Aug 25, 2025



Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but pose risks of inadvertently exposing copyrighted or proprietary data, especially when such data is used for training but not intended for distribution. Traditional methods address these leaks only after content is generated, which can lead to the exposure of sensitive information. This study introduces a proactive approach: examining LLMs' internal states before text generation to detect potential leaks. By using a curated dataset of copyrighted materials, we trained a neural network classifier to identify risks, allowing for early intervention by stopping the generation process or altering outputs to prevent disclosure. Integrated with a Retrieval-Augmented Generation (RAG) system, this framework ensures adherence to copyright and licensing requirements while enhancing data privacy and ethical standards. Our results show that analyzing internal states effectively mitigates the risk of copyrighted data leakage, offering a scalable solution that fits smoothly into AI workflows, ensuring compliance with copyright regulations while maintaining high-quality text generation. The implementation is available on GitHub.\footnote{https://github.com/changhu73/Internal_states_leakage}
UserBench: An Interactive Gym Environment for User-Centric Agents
Jul 29, 2025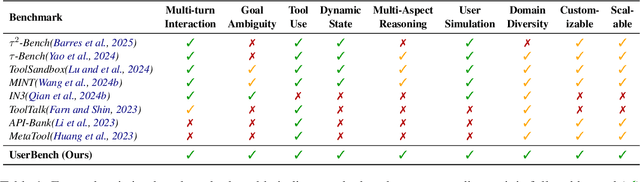


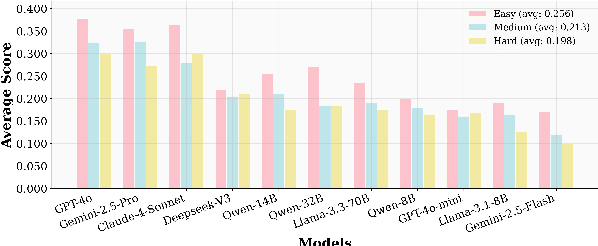
Large Language Models (LLMs)-based agents have made impressive progress in reasoning and tool use, enabling them to solve complex tasks. However, their ability to proactively collaborate with users, especially when goals are vague, evolving, or indirectly expressed, remains underexplored. To address this gap, we introduce UserBench, a user-centric benchmark designed to evaluate agents in multi-turn, preference-driven interactions. UserBench features simulated users who start with underspecified goals and reveal preferences incrementally, requiring agents to proactively clarify intent and make grounded decisions with tools. Our evaluation of leading open- and closed-source LLMs reveals a significant disconnect between task completion and user alignment. For instance, models provide answers that fully align with all user intents only 20% of the time on average, and even the most advanced models uncover fewer than 30% of all user preferences through active interaction. These results highlight the challenges of building agents that are not just capable task executors, but true collaborative partners. UserBench offers an interactive environment to measure and advance this critical capability.
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025



Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
Atomic Reasoning for Scientific Table Claim Verification
Jun 08, 2025Scientific texts often convey authority due to their technical language and complex data. However, this complexity can sometimes lead to the spread of misinformation. Non-experts are particularly susceptible to misleading claims based on scientific tables due to their high information density and perceived credibility. Existing table claim verification models, including state-of-the-art large language models (LLMs), often struggle with precise fine-grained reasoning, resulting in errors and a lack of precision in verifying scientific claims. Inspired by Cognitive Load Theory, we propose that enhancing a model's ability to interpret table-based claims involves reducing cognitive load by developing modular, reusable reasoning components (i.e., atomic skills). We introduce a skill-chaining schema that dynamically composes these skills to facilitate more accurate and generalizable reasoning with a reduced cognitive load. To evaluate this, we create SciAtomicBench, a cross-domain benchmark with fine-grained reasoning annotations. With only 350 fine-tuning examples, our model trained by atomic reasoning outperforms GPT-4o's chain-of-thought method, achieving state-of-the-art results with far less training data.
DecisionFlow: Advancing Large Language Model as Principled Decision Maker
May 27, 2025In high-stakes domains such as healthcare and finance, effective decision-making demands not just accurate outcomes but transparent and explainable reasoning. However, current language models often lack the structured deliberation needed for such tasks, instead generating decisions and justifications in a disconnected, post-hoc manner. To address this, we propose DecisionFlow, a novel decision modeling framework that guides models to reason over structured representations of actions, attributes, and constraints. Rather than predicting answers directly from prompts, DecisionFlow builds a semantically grounded decision space and infers a latent utility function to evaluate trade-offs in a transparent, utility-driven manner. This process produces decisions tightly coupled with interpretable rationales reflecting the model's reasoning. Empirical results on two high-stakes benchmarks show that DecisionFlow not only achieves up to 30% accuracy gains over strong prompting baselines but also enhances alignment in outcomes. Our work is a critical step toward integrating symbolic reasoning with LLMs, enabling more accountable, explainable, and reliable LLM decision support systems. We release the data and code at https://github.com/xiusic/DecisionFlow.
ModelingAgent: Bridging LLMs and Mathematical Modeling for Real-World Challenges
May 21, 2025



Recent progress in large language models (LLMs) has enabled substantial advances in solving mathematical problems. However, existing benchmarks often fail to reflect the complexity of real-world problems, which demand open-ended, interdisciplinary reasoning and integration of computational tools. To address this gap, we introduce ModelingBench, a novel benchmark featuring real-world-inspired, open-ended problems from math modeling competitions across diverse domains, ranging from urban traffic optimization to ecosystem resource planning. These tasks require translating natural language into formal mathematical formulations, applying appropriate tools, and producing structured, defensible reports. ModelingBench also supports multiple valid solutions, capturing the ambiguity and creativity of practical modeling. We also present ModelingAgent, a multi-agent framework that coordinates tool use, supports structured workflows, and enables iterative self-refinement to generate well-grounded, creative solutions. To evaluate outputs, we further propose ModelingJudge, an expert-in-the-loop system leveraging LLMs as domain-specialized judges assessing solutions from multiple expert perspectives. Empirical results show that ModelingAgent substantially outperforms strong baselines and often produces solutions indistinguishable from those of human experts. Together, our work provides a comprehensive framework for evaluating and advancing real-world problem-solving in open-ended, interdisciplinary modeling challenges.
RM-R1: Reward Modeling as Reasoning
May 05, 2025Reward modeling is essential for aligning large language models (LLMs) with human preferences, especially through reinforcement learning from human feedback (RLHF). To provide accurate reward signals, a reward model (RM) should stimulate deep thinking and conduct interpretable reasoning before assigning a score or a judgment. However, existing RMs either produce opaque scalar scores or directly generate the prediction of a preferred answer, making them struggle to integrate natural language critiques, thus lacking interpretability. Inspired by recent advances of long chain-of-thought (CoT) on reasoning-intensive tasks, we hypothesize and validate that integrating reasoning capabilities into reward modeling significantly enhances RM's interpretability and performance. In this work, we introduce a new class of generative reward models -- Reasoning Reward Models (ReasRMs) -- which formulate reward modeling as a reasoning task. We propose a reasoning-oriented training pipeline and train a family of ReasRMs, RM-R1. The training consists of two key stages: (1) distillation of high-quality reasoning chains and (2) reinforcement learning with verifiable rewards. RM-R1 improves LLM rollouts by self-generating reasoning traces or chat-specific rubrics and evaluating candidate responses against them. Empirically, our models achieve state-of-the-art or near state-of-the-art performance of generative RMs across multiple comprehensive reward model benchmarks, outperforming much larger open-weight models (e.g., Llama3.1-405B) and proprietary ones (e.g., GPT-4o) by up to 13.8%. Beyond final performance, we perform thorough empirical analysis to understand the key ingredients of successful ReasRM training. To facilitate future research, we release six ReasRM models along with code and data at https://github.com/RM-R1-UIUC/RM-R1.
OTC: Optimal Tool Calls via Reinforcement Learning
Apr 21, 2025



Tool-integrated reasoning (TIR) augments large language models (LLMs) with the ability to invoke external tools, such as search engines and code interpreters, to solve tasks beyond the capabilities of language-only reasoning. While reinforcement learning (RL) has shown promise in improving TIR by optimizing final answer correctness, existing approaches often overlook the efficiency and cost associated with tool usage. This can lead to suboptimal behavior, including excessive tool calls that increase computational and financial overhead, or insufficient tool use that compromises answer quality. In this work, we propose Optimal Tool Call-controlled Policy Optimization (OTC-PO), a simple yet effective RL-based framework that encourages models to produce accurate answers with minimal tool calls. Our method introduces a tool-integrated reward that jointly considers correctness and tool efficiency, promoting high tool productivity. We instantiate this framework within both Proximal Policy Optimization (PPO) and Group Relative Preference Optimization (GRPO), resulting in OTC-PPO and OTC-GRPO. Experiments with Qwen-2.5 and Qwen-Math across multiple QA benchmarks show that our approach reduces tool calls by up to 73.1\% and improves tool productivity by up to 229.4\%, while maintaining comparable answer accuracy. To the best of our knowledge, this is the first RL-based framework that explicitly optimizes tool-use efficiency in TIR.