 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Foundation Model for Brain Lesion Segmentation with Mixture of Modality Experts
May 16, 2024



Brain lesion segmentation plays an essential role in neurological research and diagnosis. As brain lesions can be caused by various pathological alterations, different types of brain lesions tend to manifest with different characteristics on different imaging modalities. Due to this complexity, brain lesion segmentation methods are often developed in a task-specific manner. A specific segmentation model is developed for a particular lesion type and imaging modality. However, the use of task-specific models requires predetermination of the lesion type and imaging modality, which complicates their deployment in real-world scenarios. In this work, we propose a universal foundation model for 3D brain lesion segmentation, which can automatically segment different types of brain lesions for input data of various imaging modalities. We formulate a novel Mixture of Modality Experts (MoME) framework with multiple expert networks attending to different imaging modalities. A hierarchical gating network combines the expert predictions and fosters expertise collaboration. Furthermore, we introduce a curriculum learning strategy during training to avoid the degeneration of each expert network and preserve their specialization. We evaluated the proposed method on nine brain lesion datasets, encompassing five imaging modalities and eight lesion types. The results show that our model outperforms state-of-the-art universal models and provides promising generalization to unseen datasets.
The state-of-the-art in Cardiac MRI Reconstruction: Results of the CMRxRecon Challenge in MICCAI 2023
Apr 01, 2024



Cardiac MRI, crucial for evaluating heart structure and function, faces limitations like slow imaging and motion artifacts. Undersampling reconstruction, especially data-driven algorithms, has emerged as a promising solution to accelerate scans and enhance imaging performance using highly under-sampled data. Nevertheless, the scarcity of publicly available cardiac k-space datasets and evaluation platform hinder the development of data-driven reconstruction algorithms. To address this issue, we organized the Cardiac MRI Reconstruction Challenge (CMRxRecon) in 2023, in collaboration with the 26th International Conference on MICCAI. CMRxRecon presented an extensive k-space dataset comprising cine and mapping raw data, accompanied by detailed annotations of cardiac anatomical structures. With overwhelming participation, the challenge attracted more than 285 teams and over 600 participants. Among them, 22 teams successfully submitted Docker containers for the testing phase, with 7 teams submitted for both cine and mapping tasks. All teams use deep learning based approaches, indicating that deep learning has predominately become a promising solution for the problem. The first-place winner of both tasks utilizes the E2E-VarNet architecture as backbones. In contrast, U-Net is still the most popular backbone for both multi-coil and single-coil reconstructions. This paper provides a comprehensive overview of the challenge design, presents a summary of the submitted results, reviews the employed methods, and offers an in-depth discussion that aims to inspire future advancements in cardiac MRI reconstruction models. The summary emphasizes the effective strategies observed in Cardiac MRI reconstruction, including backbone architecture, loss function, pre-processing techniques, physical modeling, and model complexity, thereby providing valuable insights for further developments in this field.
Zero-Shot ECG Classification with Multimodal Learning and Test-time Clinical Knowledge Enhancement
Mar 11, 2024



Electrocardiograms (ECGs) are non-invasive diagnostic tools crucial for detecting cardiac arrhythmic diseases in clinical practice. While ECG Self-supervised Learning (eSSL) methods show promise in representation learning from unannotated ECG data, they often overlook the clinical knowledge that can be found in reports. This oversight and the requirement for annotated samples for downstream tasks limit eSSL's versatility. In this work, we address these issues with the Multimodal ECG Representation Learning (MERL}) framework. Through multimodal learning on ECG records and associated reports, MERL is capable of performing zero-shot ECG classification with text prompts, eliminating the need for training data in downstream tasks. At test time, we propose the Clinical Knowledge Enhanced Prompt Engineering (CKEPE) approach, which uses Large Language Models (LLMs) to exploit external expert-verified clinical knowledge databases, generating more descriptive prompts and reducing hallucinations in LLM-generated content to boost zero-shot classification. Based on MERL, we perform the first benchmark across six public ECG datasets, showing the superior performance of MERL compared against eSSL methods. Notably, MERL achieves an average AUC score of 75.2% in zero-shot classification (without training data), 3.2% higher than linear probed eSSL methods with 10\% annotated training data, averaged across all six datasets.
Multi-Center Fetal Brain Tissue Annotation (FeTA) Challenge 2022 Results
Feb 08, 2024



Segmentation is a critical step in analyzing the developing human fetal brain. There have been vast improvements in automatic segmentation methods in the past several years, and the Fetal Brain Tissue Annotation (FeTA) Challenge 2021 helped to establish an excellent standard of fetal brain segmentation. However, FeTA 2021 was a single center study, and the generalizability of algorithms across different imaging centers remains unsolved, limiting real-world clinical applicability. The multi-center FeTA Challenge 2022 focuses on advancing the generalizability of fetal brain segmentation algorithms for magnetic resonance imaging (MRI). In FeTA 2022, the training dataset contained images and corresponding manually annotated multi-class labels from two imaging centers, and the testing data contained images from these two imaging centers as well as two additional unseen centers. The data from different centers varied in many aspects, including scanners used, imaging parameters, and fetal brain super-resolution algorithms applied. 16 teams participated in the challenge, and 17 algorithms were evaluated. Here, a detailed overview and analysis of the challenge results are provided, focusing on the generalizability of the submissions. Both in- and out of domain, the white matter and ventricles were segmented with the highest accuracy, while the most challenging structure remains the cerebral cortex due to anatomical complexity. The FeTA Challenge 2022 was able to successfully evaluate and advance generalizability of multi-class fetal brain tissue segmentation algorithms for MRI and it continues to benchmark new algorithms. The resulting new methods contribute to improving the analysis of brain development in utero.
T3D: Towards 3D Medical Image Understanding through Vision-Language Pre-training
Dec 05, 2023



Expert annotation of 3D medical image for downstream analysis is resource-intensive, posing challenges in clinical applications. Visual self-supervised learning (vSSL), though effective for learning visual invariance, neglects the incorporation of domain knowledge from medicine. To incorporate medical knowledge into visual representation learning, vision-language pre-training (VLP) has shown promising results in 2D image. However, existing VLP approaches become generally impractical when applied to high-resolution 3D medical images due to GPU hardware constraints and the potential loss of critical details caused by downsampling, which is the intuitive solution to hardware constraints. To address the above limitations, we introduce T3D, the first VLP framework designed for high-resolution 3D medical images. T3D incorporates two text-informed pretext tasks: (\lowerromannumeral{1}) text-informed contrastive learning; (\lowerromannumeral{2}) text-informed image restoration. These tasks focus on learning 3D visual representations from high-resolution 3D medical images and integrating clinical knowledge from radiology reports, without distorting information through forced alignment of downsampled volumes with detailed anatomical text. Trained on a newly curated large-scale dataset of 3D medical images and radiology reports, T3D significantly outperforms current vSSL methods in tasks like organ and tumor segmentation, as well as disease classification. This underlines T3D's potential in representation learning for 3D medical image analysis. All data and code will be available upon acceptance.
G2D: From Global to Dense Radiography Representation Learning via Vision-Language Pre-training
Dec 03, 2023Recently, medical vision-language pre-training (VLP) has reached substantial progress to learn global visual representation from medical images and their paired radiology reports. However, medical imaging tasks in real world usually require finer granularity in visual features. These tasks include visual localization tasks (e.g., semantic segmentation, object detection) and visual grounding task. Yet, current medical VLP methods face challenges in learning these fine-grained features, as they primarily focus on brute-force alignment between image patches and individual text tokens for local visual feature learning, which is suboptimal for downstream dense prediction tasks. In this work, we propose a new VLP framework, named \textbf{G}lobal to \textbf{D}ense level representation learning (G2D) that achieves significantly improved granularity and more accurate grounding for the learned features, compared to existing medical VLP approaches. In particular, G2D learns dense and semantically-grounded image representations via a pseudo segmentation task parallel with the global vision-language alignment. Notably, generating pseudo segmentation targets does not incur extra trainable parameters: they are obtained on the fly during VLP with a parameter-free processor. G2D achieves superior performance across 6 medical imaging tasks and 25 diseases, particularly in semantic segmentation, which necessitates fine-grained, semantically-grounded image features. In this task, G2D surpasses peer models even when fine-tuned with just 1\% of the training data, compared to the 100\% used by these models. The code will be released upon acceptance.
Context Label Learning: Improving Background Class Representations in Semantic Segmentation
Dec 16, 2022



Background samples provide key contextual information for segmenting regions of interest (ROIs). However, they always cover a diverse set of structures, causing difficulties for the segmentation model to learn good decision boundaries with high sensitivity and precision. The issue concerns the highly heterogeneous nature of the background class, resulting in multi-modal distributions. Empirically, we find that neural networks trained with heterogeneous background struggle to map the corresponding contextual samples to compact clusters in feature space. As a result, the distribution over background logit activations may shift across the decision boundary, leading to systematic over-segmentation across different datasets and tasks. In this study, we propose context label learning (CoLab) to improve the context representations by decomposing the background class into several subclasses. Specifically, we train an auxiliary network as a task generator, along with the primary segmentation model, to automatically generate context labels that positively affect the ROI segmentation accuracy. Extensive experiments are conducted on several challenging segmentation tasks and datasets. The results demonstrate that CoLab can guide the segmentation model to map the logits of background samples away from the decision boundary, resulting in significantly improved segmentation accuracy. Code is available.
The Extreme Cardiac MRI Analysis Challenge under Respiratory Motion (CMRxMotion)
Oct 12, 2022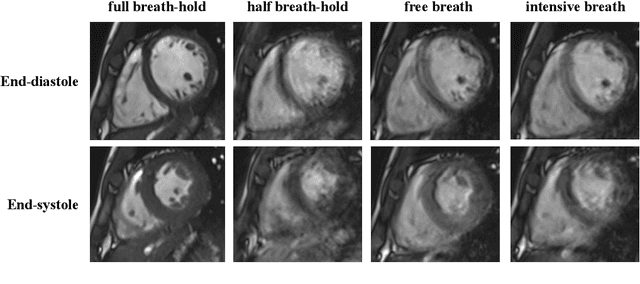
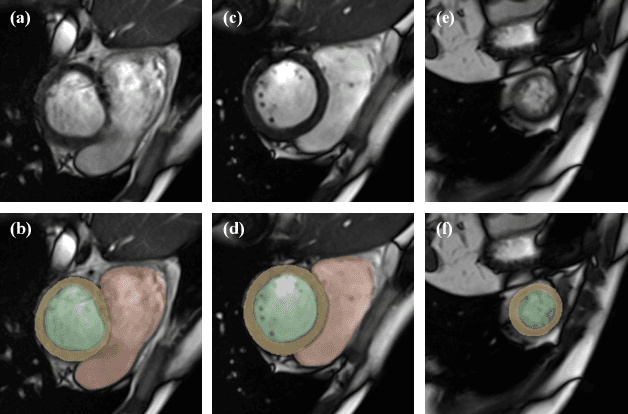

The quality of cardiac magnetic resonance (CMR) imaging is susceptible to respiratory motion artifacts. The model robustness of automated segmentation techniques in face of real-world respiratory motion artifacts is unclear. This manuscript describes the design of extreme cardiac MRI analysis challenge under respiratory motion (CMRxMotion Challenge). The challenge aims to establish a public benchmark dataset to assess the effects of respiratory motion on image quality and examine the robustness of segmentation models. The challenge recruited 40 healthy volunteers to perform different breath-hold behaviors during one imaging visit, obtaining paired cine imaging with artifacts. Radiologists assessed the image quality and annotated the level of respiratory motion artifacts. For those images with diagnostic quality, radiologists further segmented the left ventricle, left ventricle myocardium and right ventricle. The images of training set (20 volunteers) along with the annotations are released to the challenge participants, to develop an automated image quality assessment model (Task 1) and an automated segmentation model (Task 2). The images of validation set (5 volunteers) are released to the challenge participants but the annotations are withheld for online evaluation of submitted predictions. Both the images and annotations of the test set (15 volunteers) were withheld and only used for offline evaluation of submitted containerized dockers. The image quality assessment task is quantitatively evaluated by the Cohen's kappa statistics and the segmentation task is evaluated by the Dice scores and Hausdorff distances.
Improved post-hoc probability calibration for out-of-domain MRI segmentation
Aug 04, 2022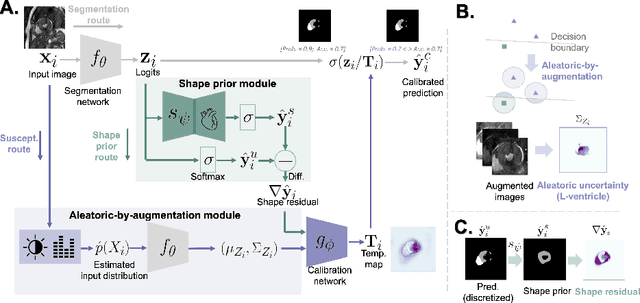
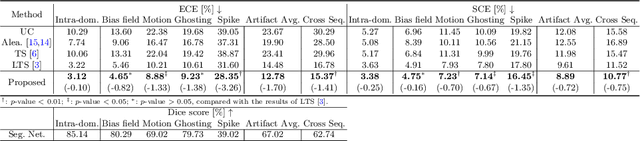

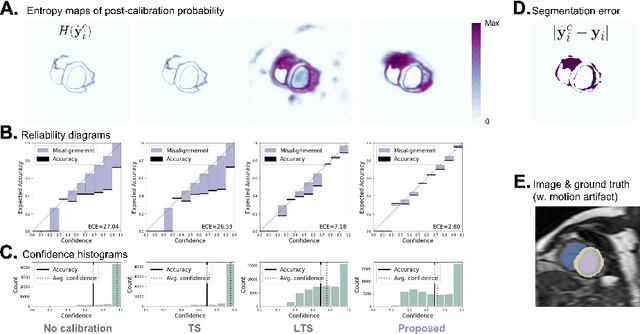
Probability calibration for deep models is highly desirable in safety-critical applications such as medical imaging. It makes output probabilities of deep networks interpretable, by aligning prediction probabilities with the actual accuracy in test data. In image segmentation, well-calibrated probabilities allow radiologists to identify regions where model-predicted segmentations are unreliable. These unreliable predictions often occur to out-of-domain (OOD) images that are caused by imaging artifacts or unseen imaging protocols. Unfortunately, most previous calibration methods for image segmentation perform sub-optimally on OOD images. To reduce the calibration error when confronted with OOD images, we propose a novel post-hoc calibration model. Our model leverages the pixel susceptibility against perturbations at the local level, and the shape prior information at the global level. The model is tested on cardiac MRI segmentation datasets that contain unseen imaging artifacts and images from an unseen imaging protocol. We demonstrate reduced calibration errors compared with the state-of-the-art calibration algorithm.
MaxStyle: Adversarial Style Composition for Robust Medical Image Segmentation
Jun 02, 2022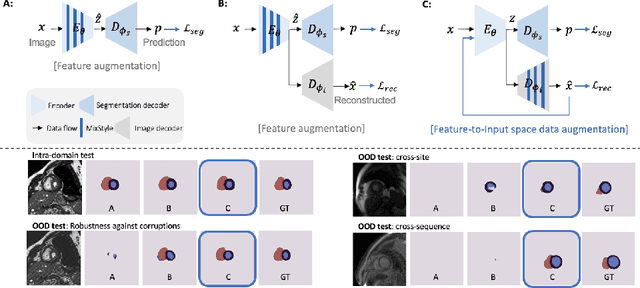

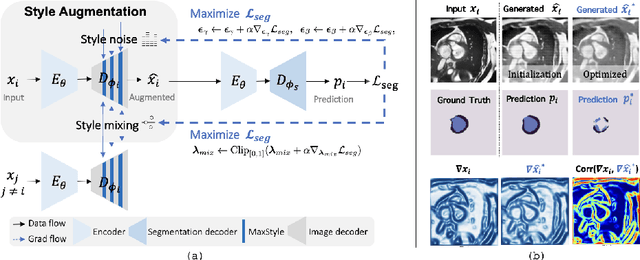
Convolutional neural networks (CNNs) have achieved remarkable segmentation accuracy on benchmark datasets where training and test sets are from the same domain, yet their performance can degrade significantly on unseen domains, which hinders the deployment of CNNs in many clinical scenarios. Most existing works improve model out-of-domain (OOD) robustness by collecting multi-domain datasets for training, which is expensive and may not always be feasible due to privacy and logistical issues. In this work, we focus on improving model robustness using a single-domain dataset only. We propose a novel data augmentation framework called MaxStyle, which maximizes the effectiveness of style augmentation for model OOD performance. It attaches an auxiliary style-augmented image decoder to a segmentation network for robust feature learning and data augmentation. Importantly, MaxStyle augments data with improved image style diversity and hardness, by expanding the style space with noise and searching for the worst-case style composition of latent features via adversarial training. With extensive experiments on multiple public cardiac and prostate MR datasets, we demonstrate that MaxStyle leads to significantly improved out-of-distribution robustness against unseen corruptions as well as common distribution shifts across multiple, different, unseen sites and unknown image sequences under both low- and high-training data settings. The code can be found at https://github.com/cherise215/MaxStyle.