 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGBoost: Efficient Retrieval-Augmented Generation with Accuracy-Preserving Context Reuse
Nov 05, 2025Retrieval-augmented generation (RAG) enhances large language models (LLMs) with retrieved context but often suffers from downgraded prefill performance as modern applications demand longer and more complex inputs. Existing caching techniques either preserve accuracy with low cache reuse or improve reuse at the cost of degraded reasoning quality. We present RAGBoost, an efficient RAG system that achieves high cache reuse without sacrificing accuracy through accuracy-preserving context reuse. RAGBoost detects overlapping retrieved items across concurrent sessions and multi-turn interactions, using efficient context indexing, ordering, and de-duplication to maximize reuse, while lightweight contextual hints maintain reasoning fidelity. It integrates seamlessly with existing LLM inference engines and improves their prefill performance by 1.5-3X over state-of-the-art methods, while preserving or even enhancing reasoning accuracy across diverse RAG and agentic AI workloads. Our code is released at: https://github.com/Edinburgh-AgenticAI/RAGBoost.
A Tale of Two Experts: Cooperative Learning for Source-Free Unsupervised Domain Adaptation
Sep 26, 2025Source-Free Unsupervised Domain Adaptation (SFUDA) addresses the realistic challenge of adapting a source-trained model to a target domain without access to the source data, driven by concerns over privacy and cost. Existing SFUDA methods either exploit only the source model's predictions or fine-tune large multimodal models, yet both neglect complementary insights and the latent structure of target data. In this paper, we propose the Experts Cooperative Learning (EXCL). EXCL contains the Dual Experts framework and Retrieval-Augmentation-Interaction optimization pipeline. The Dual Experts framework places a frozen source-domain model (augmented with Conv-Adapter) and a pretrained vision-language model (with a trainable text prompt) on equal footing to mine consensus knowledge from unlabeled target samples. To effectively train these plug-in modules under purely unsupervised conditions, we introduce Retrieval-Augmented-Interaction(RAIN), a three-stage pipeline that (1) collaboratively retrieves pseudo-source and complex target samples, (2) separately fine-tunes each expert on its respective sample set, and (3) enforces learning object consistency via a shared learning result. Extensive experiments on four benchmark datasets demonstrate that our approach matches state-of-the-art performance.
Taming Transformer for Emotion-Controllable Talking Face Generation
Aug 20, 2025Talking face generation is a novel and challenging generation task, aiming at synthesizing a vivid speaking-face video given a specific audio. To fulfill emotion-controllable talking face generation, current methods need to overcome two challenges: One is how to effectively model the multimodal relationship related to the specific emotion, and the other is how to leverage this relationship to synthesize identity preserving emotional videos. In this paper, we propose a novel method to tackle the emotion-controllable talking face generation task discretely. Specifically, we employ two pre-training strategies to disentangle audio into independent components and quantize videos into combinations of visual tokens. Subsequently, we propose the emotion-anchor (EA) representation that integrates the emotional information into visual tokens. Finally, we introduce an autoregressive transformer to model the global distribution of the visual tokens under the given conditions and further predict the index sequence for synthesizing the manipulated videos. We conduct experiments on the MEAD dataset that controls the emotion of videos conditioned on multiple emotional audios. Extensive experiments demonstrate the superiorities of our method both qualitatively and quantitatively.
SpatialViz-Bench: Automatically Generated Spatial Visualization Reasoning Tasks for MLLMs
Jul 10, 2025



Humans can directly imagine and manipulate visual images in their minds, a capability known as spatial visualization. While multi-modal Large Language Models (MLLMs) support imagination-based reasoning, spatial visualization remains insufficiently evaluated, typically embedded within broader mathematical and logical assessments. Existing evaluations often rely on IQ tests or math competitions that may overlap with training data, compromising assessment reliability. To this end, we introduce SpatialViz-Bench, a comprehensive multi-modal benchmark for spatial visualization with 12 tasks across 4 sub-abilities, comprising 1,180 automatically generated problems. Our evaluation of 33 state-of-the-art MLLMs not only reveals wide performance variations and demonstrates the benchmark's strong discriminative power, but also uncovers counter-intuitive findings: models exhibit unexpected behaviors by showing difficulty perception that misaligns with human intuition, displaying dramatic 2D-to-3D performance cliffs, and defaulting to formula derivation despite spatial tasks requiring visualization alone. SpatialVizBench empirically demonstrates that state-of-the-art MLLMs continue to exhibit deficiencies in spatial visualization tasks, thereby addressing a significant lacuna in the field. The benchmark is publicly available.
MF-LLM: Simulating Collective Decision Dynamics via a Mean-Field Large Language Model Framework
Apr 30, 2025
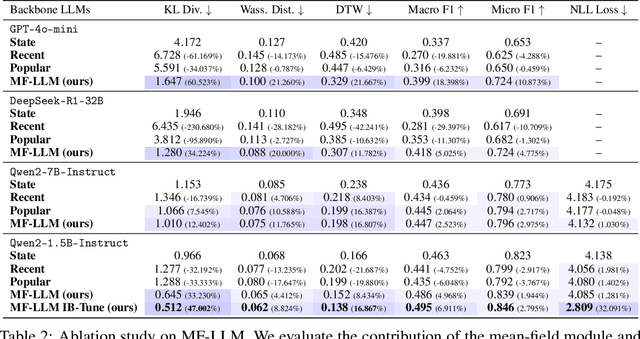


Simulating collective decision-making involves more than aggregating individual behaviors; it arises from dynamic interactions among individuals. While large language models (LLMs) show promise for social simulation, existing approaches often exhibit deviations from real-world data. To address this gap, we propose the Mean-Field LLM (MF-LLM) framework, which explicitly models the feedback loop between micro-level decisions and macro-level population. MF-LLM alternates between two models: a policy model that generates individual actions based on personal states and group-level information, and a mean field model that updates the population distribution from the latest individual decisions. Together, they produce rollouts that simulate the evolving trajectories of collective decision-making. To better match real-world data, we introduce IB-Tune, a fine-tuning method for LLMs grounded in the information bottleneck principle, which maximizes the relevance of population distributions to future actions while minimizing redundancy with historical data. We evaluate MF-LLM on a real-world social dataset, where it reduces KL divergence to human population distributions by 47 percent over non-mean-field baselines, and enables accurate trend forecasting and intervention planning. It generalizes across seven domains and four LLM backbones, providing a scalable foundation for high-fidelity social simulation.
PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
Mar 15, 2025



While scaling laws have been continuously validated in large language models (LLMs) with increasing model parameters, the inherent tension between the inference demands of LLMs and the limited resources of edge devices poses a critical challenge to the development of edge intelligence. Recently, numerous small language models have emerged, aiming to distill the capabilities of LLMs into smaller footprints. However, these models often retain the fundamental architectural principles of their larger counterparts, still imposing considerable strain on the storage and bandwidth capacities of edge devices. In this paper, we introduce the PLM, a Peripheral Language Model, developed through a co-design process that jointly optimizes model architecture and edge system constraints. The PLM utilizes a Multi-head Latent Attention mechanism and employs the squared ReLU activation function to encourage sparsity, thereby reducing peak memory footprint during inference. During training, we collect and reorganize open-source datasets, implement a multi-phase training strategy, and empirically investigate the Warmup-Stable-Decay-Constant (WSDC) learning rate scheduler. Additionally, we incorporate Reinforcement Learning from Human Feedback (RLHF) by adopting the ARIES preference learning approach. Following a two-phase SFT process, this method yields performance gains of 2% in general tasks, 9% in the GSM8K task, and 11% in coding tasks. In addition to its novel architecture, evaluation results demonstrate that PLM outperforms existing small language models trained on publicly available data while maintaining the lowest number of activated parameters. Furthermore, deployment across various edge devices, including consumer-grade GPUs, mobile phones, and Raspberry Pis, validates PLM's suitability for peripheral applications. The PLM series models are publicly available at https://github.com/plm-team/PLM.
Activation-aware Probe-Query: Effective Key-Value Retrieval for Long-Context LLMs Inference
Feb 19, 2025Recent advances in large language models (LLMs) have showcased exceptional performance in long-context tasks, while facing significant inference efficiency challenges with limited GPU memory. Existing solutions first proposed the sliding-window approach to accumulate a set of historical \textbf{key-value} (KV) pairs for reuse, then further improvements selectively retain its subsets at each step. However, due to the sparse attention distribution across a long context, it is hard to identify and recall relevant KV pairs, as the attention is distracted by massive candidate pairs. Additionally, we found it promising to select representative tokens as probe-Query in each sliding window to effectively represent the entire context, which is an approach overlooked by existing methods. Thus, we propose \textbf{ActQKV}, a training-free, \textbf{Act}ivation-aware approach that dynamically determines probe-\textbf{Q}uery and leverages it to retrieve the relevant \textbf{KV} pairs for inference. Specifically, ActQKV monitors a token-level indicator, Activation Bias, within each context window, enabling the proper construction of probe-Query for retrieval at pre-filling stage. To accurately recall the relevant KV pairs and minimize the irrelevant ones, we design a dynamic KV cut-off mechanism guided by information density across layers at the decoding stage. Experiments on the Long-Bench and $\infty$ Benchmarks demonstrate its state-of-the-art performance with competitive inference quality and resource efficiency.
Knowledge-Guided Prompt Learning for Deepfake Facial Image Detection
Jan 01, 2025



Recent generative models demonstrate impressive performance on synthesizing photographic images, which makes humans hardly to distinguish them from pristine ones, especially on realistic-looking synthetic facial images. Previous works mostly focus on mining discriminative artifacts from vast amount of visual data. However, they usually lack the exploration of prior knowledge and rarely pay attention to the domain shift between training categories (e.g., natural and indoor objects) and testing ones (e.g., fine-grained human facial images), resulting in unsatisfactory detection performance. To address these issues, we propose a novel knowledge-guided prompt learning method for deepfake facial image detection. Specifically, we retrieve forgery-related prompts from large language models as expert knowledge to guide the optimization of learnable prompts. Besides, we elaborate test-time prompt tuning to alleviate the domain shift, achieving significant performance improvement and boosting the application in real-world scenarios. Extensive experiments on DeepFakeFaceForensics dataset show that our proposed approach notably outperforms state-of-the-art methods.
KaLM: Knowledge-aligned Autoregressive Language Modeling via Dual-view Knowledge Graph Contrastive Learning
Dec 06, 2024Autoregressive large language models (LLMs) pre-trained by next token prediction are inherently proficient in generative tasks. However, their performance on knowledge-driven tasks such as factual knowledge querying remains unsatisfactory. Knowledge graphs (KGs), as high-quality structured knowledge bases, can provide reliable knowledge for LLMs, potentially compensating for their knowledge deficiencies. Aligning LLMs with explicit, structured knowledge from KGs has been a challenge; previous attempts either failed to effectively align knowledge representations or compromised the generative capabilities of LLMs, leading to less-than-optimal outcomes. This paper proposes \textbf{KaLM}, a \textit{Knowledge-aligned Language Modeling} approach, which fine-tunes autoregressive LLMs to align with KG knowledge via the joint objective of explicit knowledge alignment and implicit knowledge alignment. The explicit knowledge alignment objective aims to directly optimize the knowledge representation of LLMs through dual-view knowledge graph contrastive learning. The implicit knowledge alignment objective focuses on incorporating textual patterns of knowledge into LLMs through triple completion language modeling. Notably, our method achieves a significant performance boost in evaluations of knowledge-driven tasks, specifically embedding-based knowledge graph completion and generation-based knowledge graph question answering.
Self-Supervised Graph Embedding Clustering
Sep 24, 2024



The K-means one-step dimensionality reduction clustering method has made some progress in addressing the curse of dimensionality in clustering tasks. However, it combines the K-means clustering and dimensionality reduction processes for optimization, leading to limitations in the clustering effect due to the introduced hyperparameters and the initialization of clustering centers. Moreover, maintaining class balance during clustering remains challenging. To overcome these issues, we propose a unified framework that integrates manifold learning with K-means, resulting in the self-supervised graph embedding framework. Specifically, we establish a connection between K-means and the manifold structure, allowing us to perform K-means without explicitly defining centroids. Additionally, we use this centroid-free K-means to generate labels in low-dimensional space and subsequently utilize the label information to determine the similarity between samples. This approach ensures consistency between the manifold structure and the labels. Our model effectively achieves one-step clustering without the need for redundant balancing hyperparameters. Notably, we have discovered that maximizing the $\ell_{2,1}$-norm naturally maintains class balance during clustering, a result that we have theoretically proven. Finally, experiments on multiple datasets demonstrate that the clustering results of Our-LPP and Our-MFA exhibit excellent and reliable performance.