 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Visual Prompt: Unifying Distributional Control of Pre-Trained Generative Models
Sep 14, 2022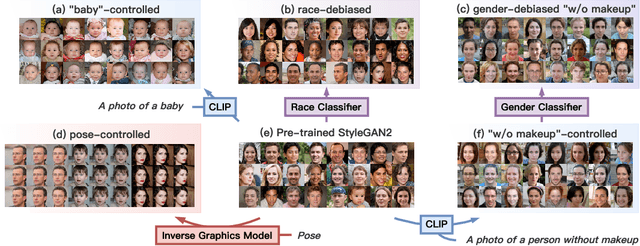



Generative models (e.g., GANs and diffusion models) learn the underlying data distribution in an unsupervised manner. However, many applications of interest require sampling from a specific region of the generative model's output space or evenly over a range of characteristics. To allow efficient sampling in these scenarios, we propose Generative Visual Prompt (PromptGen), a framework for distributional control over pre-trained generative models by incorporating knowledge of arbitrary off-the-shelf models. PromptGen defines control as an energy-based model (EBM) and samples images in a feed-forward manner by approximating the EBM with invertible neural networks, avoiding optimization at inference. We demonstrate how PromptGen can control several generative models (e.g., StyleGAN2, StyleNeRF, diffusion autoencoder, and NVAE) using various off-the-shelf models: (1) with the CLIP model, PromptGen can sample images guided by text, (2) with image classifiers, PromptGen can de-bias generative models across a set of attributes, and (3) with inverse graphics models, PromptGen can sample images of the same identity in different poses. (4) Finally, PromptGen reveals that the CLIP model shows "reporting bias" when used as control, and PromptGen can further de-bias this controlled distribution in an iterative manner. Our code is available at https://github.com/ChenWu98/Generative-Visual-Prompt.
Selective Annotation Makes Language Models Better Few-Shot Learners
Sep 05, 2022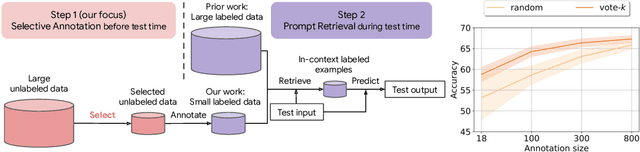
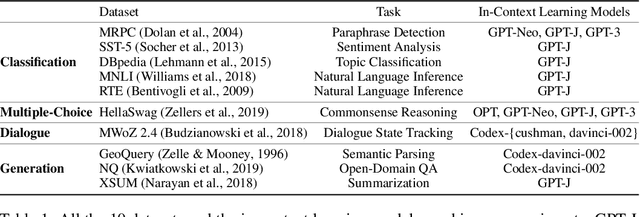
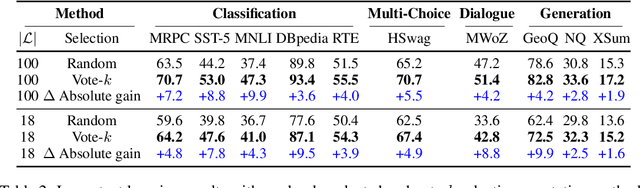
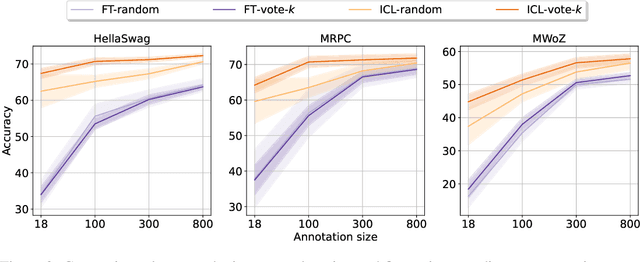
Many recent approaches to natural language tasks are built on the remarkable abilities of large language models. Large language models can perform in-context learning, where they learn a new task from a few task demonstrations, without any parameter updates. This work examines the implications of in-context learning for the creation of datasets for new natural language tasks. Departing from recent in-context learning methods, we formulate an annotation-efficient, two-step framework: selective annotation that chooses a pool of examples to annotate from unlabeled data in advance, followed by prompt retrieval that retrieves task examples from the annotated pool at test time. Based on this framework, we propose an unsupervised, graph-based selective annotation method, voke-k, to select diverse, representative examples to annotate. Extensive experiments on 10 datasets (covering classification, commonsense reasoning, dialogue, and text/code generation) demonstrate that our selective annotation method improves the task performance by a large margin. On average, vote-k achieves a 12.9%/11.4% relative gain under an annotation budget of 18/100, as compared to randomly selecting examples to annotate. Compared to state-of-the-art supervised finetuning approaches, it yields similar performance with 10-100x less annotation cost across 10 tasks. We further analyze the effectiveness of our framework in various scenarios: language models with varying sizes, alternative selective annotation methods, and cases where there is a test data domain shift. We hope that our studies will serve as a basis for data annotations as large language models are increasingly applied to new tasks. Our code is available at https://github.com/HKUNLP/icl-selective-annotation.
UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models
Jan 20, 2022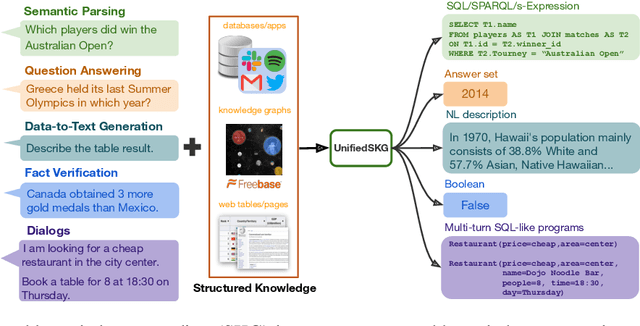
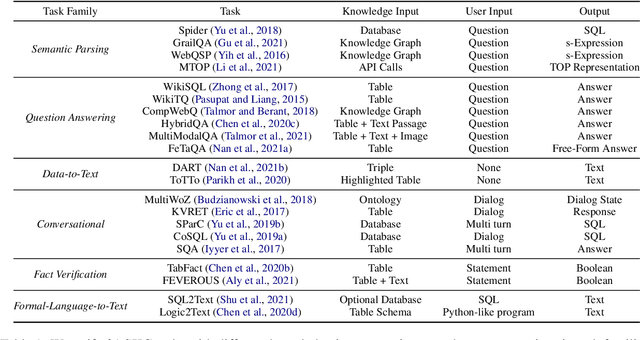
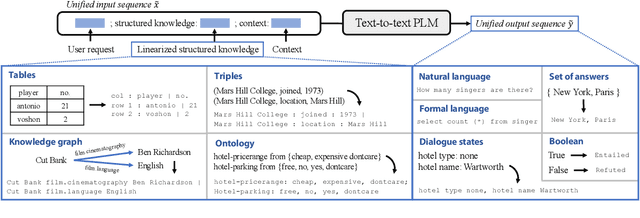
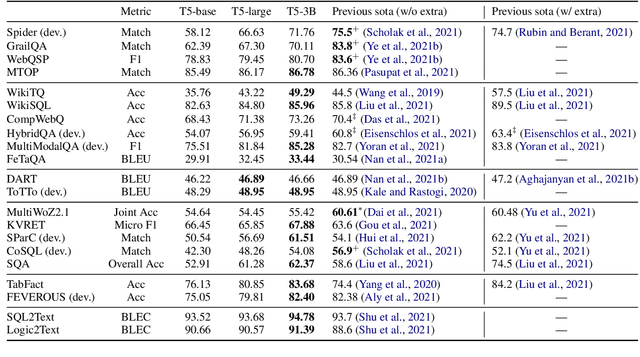
Structured knowledge grounding (SKG) leverages structured knowledge to complete user requests, such as semantic parsing over databases and question answering over knowledge bases. Since the inputs and outputs of SKG tasks are heterogeneous, they have been studied separately by different communities, which limits systematic and compatible research on SKG. In this paper, we overcome this limitation by proposing the SKG framework, which unifies 21 SKG tasks into a text-to-text format, aiming to promote systematic SKG research, instead of being exclusive to a single task, domain, or dataset. We use UnifiedSKG to benchmark T5 with different sizes and show that T5, with simple modifications when necessary, achieves state-of-the-art performance on almost all of the 21 tasks. We further demonstrate that multi-task prefix-tuning improves the performance on most tasks, largely improving the overall performance. UnifiedSKG also facilitates the investigation of zero-shot and few-shot learning, and we show that T0, GPT-3, and Codex struggle in zero-shot and few-shot learning for SKG. We also use UnifiedSKG to conduct a series of controlled experiments on structured knowledge encoding variants across SKG tasks. UnifiedSKG is easily extensible to more tasks, and it is open-sourced at https://github.com/hkunlp/unifiedskg Latest collections at https://unifiedskg.com.
Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents
Oct 16, 2021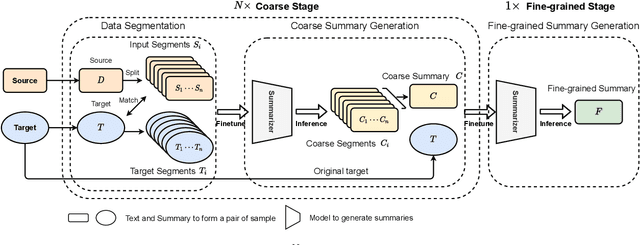
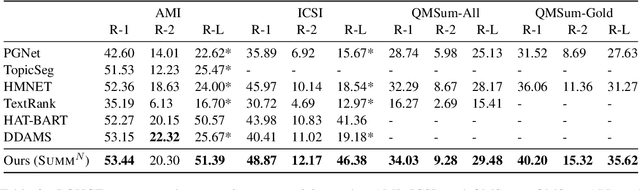
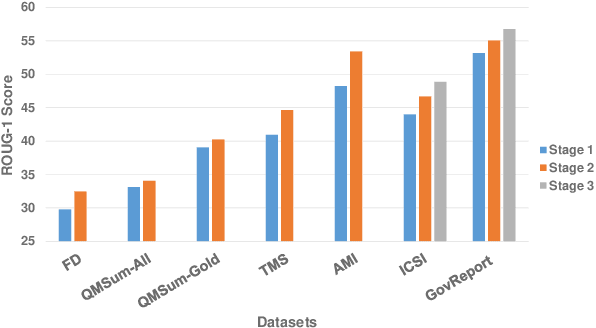
Text summarization is an essential task to help readers capture salient information from documents, news, interviews, and meetings. However, most state-of-the-art pretrained language models are unable to efficiently process long text commonly seen in the summarization problem domain. In this paper, we propose Summ^N, a simple, flexible, and effective multi-stage framework for input texts that are longer than the maximum context lengths of typical pretrained LMs. Summ^N first generates the coarse summary in multiple stages and then produces the final fine-grained summary based on them. The framework can process input text of arbitrary length by adjusting the number of stages while keeping the LM context size fixed. Moreover, it can deal with both documents and dialogues and can be used on top of any underlying backbone abstractive summarization model. Our experiments demonstrate that Summ^N significantly outperforms previous state-of-the-art methods by improving ROUGE scores on three long meeting summarization datasets AMI, ICSI, and QMSum, two long TV series datasets from SummScreen, and a newly proposed long document summarization dataset GovReport. Our data and code are available at https://github.com/chatc/Summ-N.
DYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization
Oct 15, 2021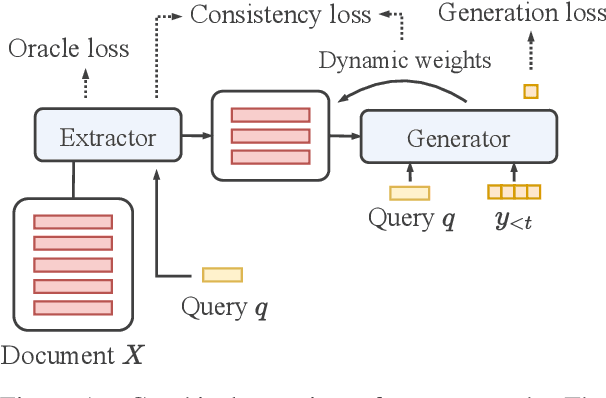
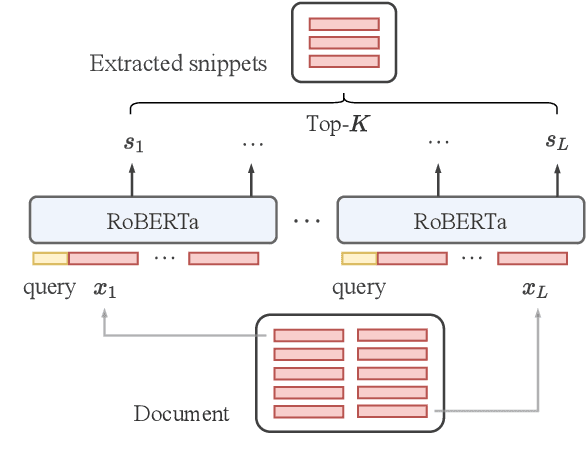
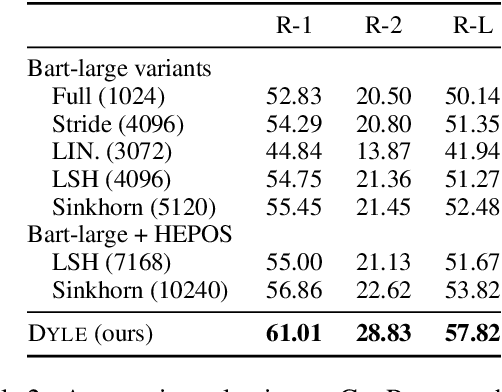
Transformer-based models have achieved state-of-the-art performance on short text summarization. However, they still struggle with long-input summarization. In this paper, we present a new approach for long-input summarization: Dynamic Latent Extraction for Abstractive Summarization. We jointly train an extractor with an abstractor and treat the extracted text snippets as the latent variable. We propose extractive oracles to provide the extractor with a strong learning signal. We introduce consistency loss, which encourages the extractor to approximate the averaged dynamic weights predicted by the generator. We conduct extensive tests on two long-input summarization datasets, GovReport (document) and QMSum (dialogue). Our model significantly outperforms the current state-of-the-art, including a 6.21 ROUGE-2 improvement on GovReport and a 2.13 ROUGE-1 improvement on QMSum. Further analysis shows that the dynamic weights make our generation process highly interpretable. Our code will be publicly available upon publication.
Transferable Persona-Grounded Dialogues via Grounded Minimal Edits
Sep 16, 2021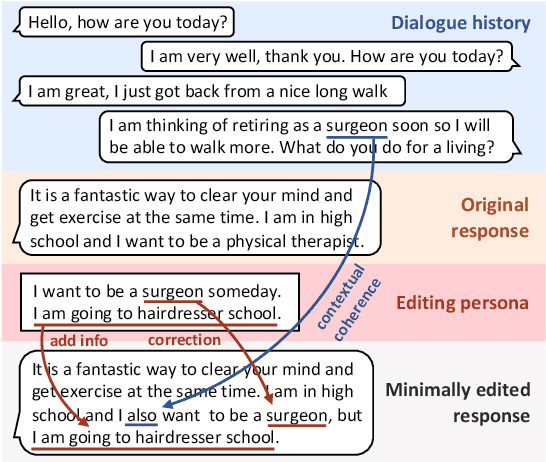

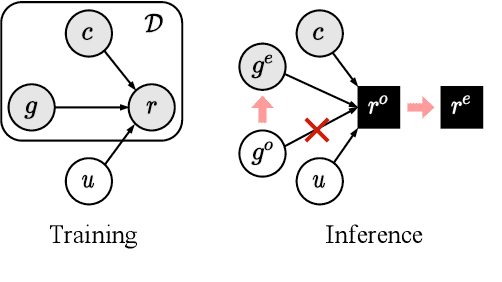
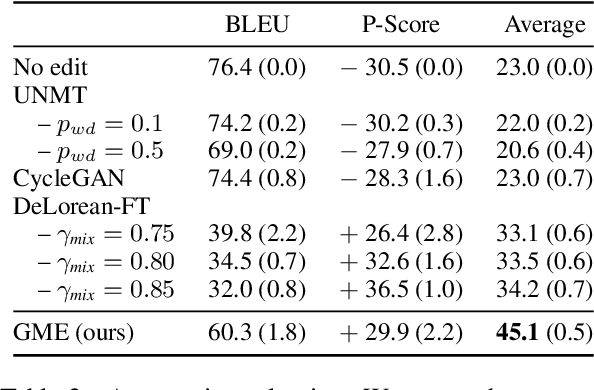
Grounded dialogue models generate responses that are grounded on certain concepts. Limited by the distribution of grounded dialogue data, models trained on such data face the transferability challenges in terms of the data distribution and the type of grounded concepts. To address the challenges, we propose the grounded minimal editing framework, which minimally edits existing responses to be grounded on the given concept. Focusing on personas, we propose Grounded Minimal Editor (GME), which learns to edit by disentangling and recombining persona-related and persona-agnostic parts of the response. To evaluate persona-grounded minimal editing, we present the PersonaMinEdit dataset, and experimental results show that GME outperforms competitive baselines by a large margin. To evaluate the transferability, we experiment on the test set of BlendedSkillTalk and show that GME can edit dialogue models' responses to largely improve their persona consistency while preserving the use of knowledge and empathy.
EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training
Aug 03, 2021
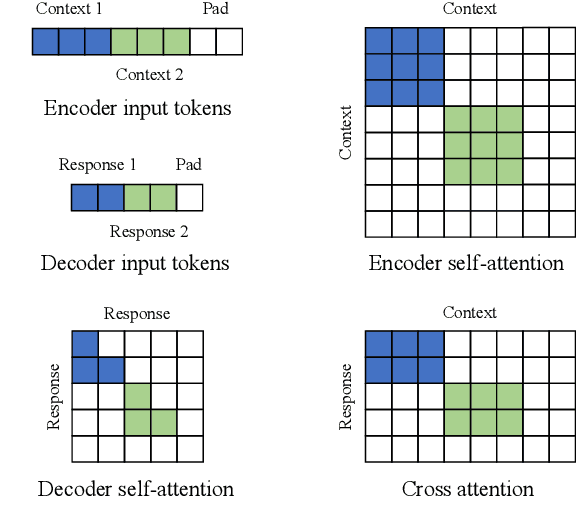
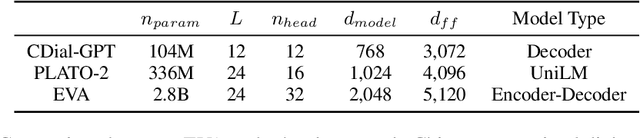
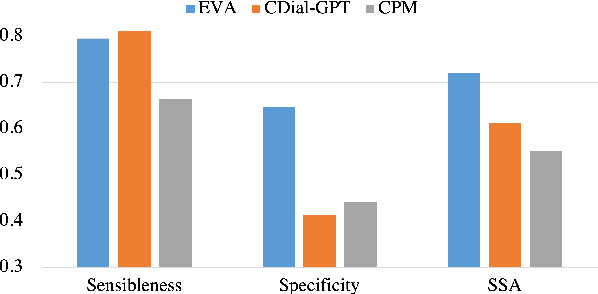
Although pre-trained language models have remarkably enhanced the generation ability of dialogue systems, open-domain Chinese dialogue systems are still limited by the dialogue data and the model size compared with English ones. In this paper, we propose EVA, a Chinese dialogue system that contains the largest Chinese pre-trained dialogue model with 2.8B parameters. To build this model, we collect the largest Chinese dialogue dataset named WDC-Dialogue from various public social media. This dataset contains 1.4B context-response pairs and is used as the pre-training corpus of EVA. Extensive experiments on automatic and human evaluation show that EVA outperforms other Chinese pre-trained dialogue models especially in the multi-turn interaction of human-bot conversations.
Semantic-Enhanced Explainable Finetuning for Open-Domain Dialogues
Jun 06, 2021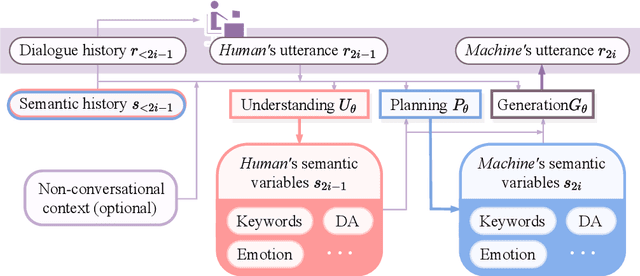
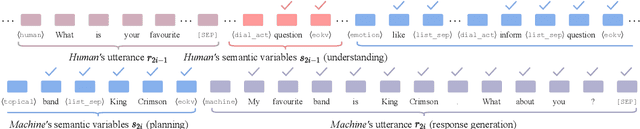
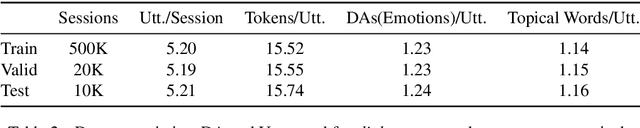
In this paper, we propose to combine pretrained language models with the modular dialogue paradigm for open-domain dialogue modeling. Our method, semantic-enhanced finetuning, instantiates conversation understanding, planning, and response generation as a language model finetuning task. At inference, we disentangle semantic and token variations by specifying sampling methods and constraints for each module separately. For training and evaluation, we present X-Weibo, a Chinese multi-turn open-domain dialogue dataset with automatic annotation for emotions, DAs, and topical words. Experiments show that semantic-enhanced finetuning outperforms strong baselines on non-semantic and semantic metrics, improves the human-evaluated relevance, coherence, and informativeness, and exhibits considerable controllability over semantic variables.
NAST: A Non-Autoregressive Generator with Word Alignment for Unsupervised Text Style Transfer
Jun 04, 2021
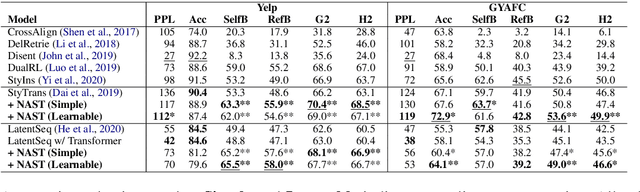
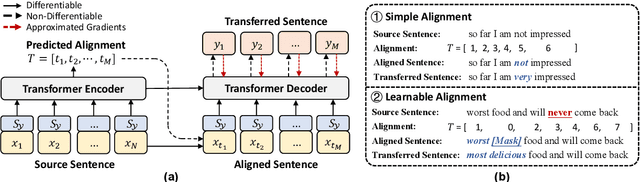
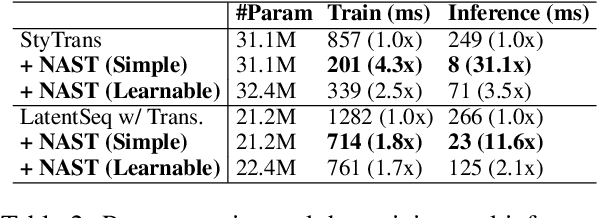
Autoregressive models have been widely used in unsupervised text style transfer. Despite their success, these models still suffer from the content preservation problem that they usually ignore part of the source sentence and generate some irrelevant words with strong styles. In this paper, we propose a Non-Autoregressive generator for unsupervised text Style Transfer (NAST), which alleviates the problem from two aspects. First, we observe that most words in the transferred sentence can be aligned with related words in the source sentence, so we explicitly model word alignments to suppress irrelevant words. Second, existing models trained with the cycle loss align sentences in two stylistic text spaces, which lacks fine-grained control at the word level. The proposed non-autoregressive generator focuses on the connections between aligned words, which learns the word-level transfer between styles. For experiments, we integrate the proposed generator into two base models and evaluate them on two style transfer tasks. The results show that NAST can significantly improve the overall performance and provide explainable word alignments. Moreover, the non-autoregressive generator achieves over 10x speedups at inference. Our codes are available at https://github.com/thu-coai/NAST.