 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Efficiency Gap in Byte Modeling
May 13, 2026Modern language models have historically relied on two dominant design choices: subword tokenization and autoregressive (AR) ordering. These design decisions bake in priors that dictate a model's learning. Recently, two alternative paradigms have challenged this: byte-level modeling, which bypasses static statistically-derived token vocabularies, and masked diffusion modeling (MDM), which conducts parallel, non-sequential generation. Their intersection represents a fully end-to-end modality-agnostic generative prototype; however, removing these structural priors incurs a significant computational cost. In this work, we investigate this cost through a compute-matched scaling study. Our results reveal that the performance penalty of byte modeling is not uniform; across scale, the scaling overhead of byte modeling is worse for MDM than for AR. We hypothesize that this disparity stems from context fragility: while AR's stable causal history allows models to naturally rediscover subword patterns, the MDM objective destroys the local contiguity required to efficiently resolve semantics from raw bytes. Our findings from controlled permutation experiments suggest that future modality-agnostic designs must incorporate alternative structural biases to maintain viable scaling trajectories in the byte regime.
ProgramBench: Can Language Models Rebuild Programs From Scratch?
May 05, 2026Turning ideas into full software projects from scratch has become a popular use case for language models. Agents are being deployed to seed, maintain, and grow codebases over extended periods with minimal human oversight. Such settings require models to make high-level software architecture decisions. However, existing benchmarks measure focused, limited tasks such as fixing a single bug or developing a single, specified feature. We therefore introduce ProgramBench to measure the ability of software engineering agents to develop software holisitically. In ProgramBench, given only a program and its documentation, agents must architect and implement a codebase that matches the reference executable's behavior. End-to-end behavioral tests are generated via agent-driven fuzzing, enabling evaluation without prescribing implementation structure. Our 200 tasks range from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter. We evaluate 9 LMs and find that none fully resolve any task, with the best model passing 95\% of tests on only 3\% of tasks. Models favor monolithic, single-file implementations that diverge sharply from human-written code.
Learn-by-interact: A Data-Centric Framework for Self-Adaptive Agents in Realistic Environments
Jan 18, 2025



Autonomous agents powered by large language models (LLMs) have the potential to enhance human capabilities, assisting with digital tasks from sending emails to performing data analysis. The abilities of existing LLMs at such tasks are often hindered by the lack of high-quality agent data from the corresponding environments they interact with. We propose Learn-by-interact, a data-centric framework to adapt LLM agents to any given environments without human annotations. Learn-by-interact synthesizes trajectories of agent-environment interactions based on documentations, and constructs instructions by summarizing or abstracting the interaction histories, a process called backward construction. We assess the quality of our synthetic data by using them in both training-based scenarios and training-free in-context learning (ICL), where we craft innovative retrieval approaches optimized for agents. Extensive experiments on SWE-bench, WebArena, OSWorld and Spider2-V spanning across realistic coding, web, and desktop environments show the effectiveness of Learn-by-interact in various downstream agentic tasks -- baseline results are improved by up to 12.2\% for ICL with Claude-3.5 and 19.5\% for training with Codestral-22B. We further demonstrate the critical role of backward construction, which provides up to 14.0\% improvement for training. Our ablation studies demonstrate the efficiency provided by our synthesized data in ICL and the superiority of our retrieval pipeline over alternative approaches like conventional retrieval-augmented generation (RAG). We expect that Learn-by-interact will serve as a foundation for agent data synthesis as LLMs are increasingly deployed at real-world environments.
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows
Nov 12, 2024



Real-world enterprise text-to-SQL workflows often involve complex cloud or local data across various database systems, multiple SQL queries in various dialects, and diverse operations from data transformation to analytics. We introduce Spider 2.0, an evaluation framework comprising 632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases. The databases in Spider 2.0 are sourced from real data applications, often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake. We show that solving problems in Spider 2.0 frequently requires understanding and searching through database metadata, dialect documentation, and even project-level codebases. This challenge calls for models to interact with complex SQL workflow environments, process extremely long contexts, perform intricate reasoning, and generate multiple SQL queries with diverse operations, often exceeding 100 lines, which goes far beyond traditional text-to-SQL challenges. Our evaluations indicate that based on o1-preview, our code agent framework successfully solves only 17.0% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD. Our results on Spider 2.0 show that while language models have demonstrated remarkable performance in code generation -- especially in prior text-to-SQL benchmarks -- they require significant improvement in order to achieve adequate performance for real-world enterprise usage. Progress on Spider 2.0 represents crucial steps towards developing intelligent, autonomous, code agents for real-world enterprise settings. Our code, baseline models, and data are available at https://spider2-sql.github.io.
Natural Language Outlines for Code: Literate Programming in the LLM Era
Aug 09, 2024



We propose using natural language outlines as a novel modality and interaction surface for providing AI assistance to developers throughout the software development process. An NL outline for a code function comprises multiple statements written in concise prose, which partition the code and summarize its main ideas in the style of literate programming. Crucially, we find that modern LLMs can generate accurate and high-quality NL outlines in practice. Moreover, NL outlines enable a bidirectional sync between code and NL, allowing changes in one to be automatically reflected in the other. We discuss many use cases for NL outlines: they can accelerate understanding and navigation of code and diffs, simplify code maintenance, augment code search, steer code generation, and more. We then propose and compare multiple LLM prompting techniques for generating outlines and ask professional developers to judge outline quality. Finally, we present two case studies applying NL outlines toward code review and the difficult task of malware detection.
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?
Jul 15, 2024



Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions (16.2%) and involve remote cloud-hosted workspaces (10.6%). We hope that Spider2-V paves the way for autonomous multimodal agents to transform the automation of data science and engineering workflow. Our code and data are available at https://spider2-v.github.io.
NExT: Teaching Large Language Models to Reason about Code Execution
Apr 23, 2024



A fundamental skill among human developers is the ability to understand and reason about program execution. As an example, a programmer can mentally simulate code execution in natural language to debug and repair code (aka. rubber duck debugging). However, large language models (LLMs) of code are typically trained on the surface textual form of programs, thus may lack a semantic understanding of how programs execute at run-time. To address this issue, we propose NExT, a method to teach LLMs to inspect the execution traces of programs (variable states of executed lines) and reason about their run-time behavior through chain-of-thought (CoT) rationales. Specifically, NExT uses self-training to bootstrap a synthetic training set of execution-aware rationales that lead to correct task solutions (e.g., fixed programs) without laborious manual annotation. Experiments on program repair tasks based on MBPP and HumanEval demonstrate that NExT improves the fix rate of a PaLM 2 model, by 26.1% and 14.3% absolute, respectively, with significantly improved rationale quality as verified by automated metrics and human raters. Our model can also generalize to scenarios where program traces are absent at test-time.
A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
Mar 21, 2024Neural Code Intelligence -- leveraging deep learning to understand, generate, and optimize code -- holds immense potential for transformative impacts on the whole society. Bridging the gap between Natural Language and Programming Language, this domain has drawn significant attention from researchers in both research communities over the past few years. This survey presents a systematic and chronological review of the advancements in code intelligence, encompassing over 50 representative models and their variants, more than 20 categories of tasks, and an extensive coverage of over 680 related works. We follow the historical progression to trace the paradigm shifts across different research phases (e.g., from modeling code with recurrent neural networks to the era of Large Language Models). Concurrently, we highlight the major technical transitions in models, tasks, and evaluations spanning through different stages. For applications, we also observe a co-evolving shift. It spans from initial endeavors to tackling specific scenarios, through exploring a diverse array of tasks during its rapid expansion, to currently focusing on tackling increasingly complex and varied real-world challenges. Building on our examination of the developmental trajectories, we further investigate the emerging synergies between code intelligence and broader machine intelligence, uncovering new cross-domain opportunities and illustrating the substantial influence of code intelligence across various domains. Finally, we delve into both the opportunities and challenges associated with this field, alongside elucidating our insights on the most promising research directions. An ongoing, dynamically updated project and resources associated with this survey have been released at https://github.com/QiushiSun/NCISurvey.
Unsupervised Evaluation of Code LLMs with Round-Trip Correctness
Feb 13, 2024



To evaluate code large language models (LLMs), research has relied on a few small manually curated benchmarks, such as HumanEval and MBPP, which represent a narrow part of the real-world software domains. In this work, we introduce round-trip correctness (RTC) as an alternative evaluation method. RTC allows Code LLM evaluation on a broader spectrum of real-world software domains without the need for costly human curation. RTC rests on the idea that we can ask a model to make a prediction (e.g., describe some code using natural language), feed that prediction back (e.g., synthesize code from the predicted description), and check if this round-trip leads to code that is semantically equivalent to the original input. We show how to employ RTC to evaluate code synthesis and editing. We find that RTC strongly correlates with model performance on existing narrow-domain code synthesis benchmarks while allowing us to expand to a much broader set of domains and tasks which was not previously possible without costly human annotations.
Grounding Data Science Code Generation with Input-Output Specifications
Feb 12, 2024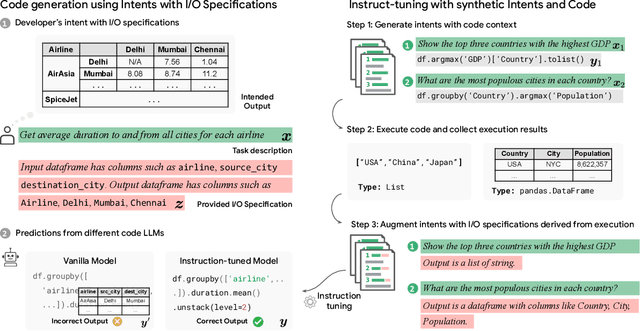

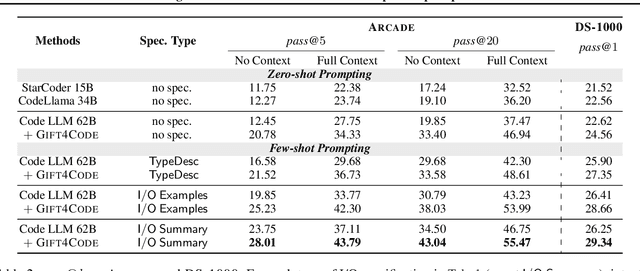

Large language models (LLMs) have recently demonstrated a remarkable ability to generate code from natural language (NL) prompts. However, in the real world, NL is often too ambiguous to capture the true intent behind programming problems, requiring additional input-output (I/O) specifications. Unfortunately, LLMs can have difficulty aligning their outputs with both the NL prompt and the I/O specification. In this paper, we give a way to mitigate this issue in the context of data science programming, where tasks require explicit I/O specifications for clarity. Specifically, we propose GIFT4Code, a novel approach for the instruction fine-tuning of LLMs with respect to I/O specifications. Our method leverages synthetic data produced by the LLM itself and utilizes execution-derived feedback as a key learning signal. This feedback, in the form of program I/O specifications, is provided to the LLM to facilitate instruction fine-tuning. We evaluated our approach on two challenging data science benchmarks, Arcade and DS-1000. The results demonstrate a significant improvement in the LLM's ability to generate code that is not only executable but also accurately aligned with user specifications, substantially improving the quality of code generation for complex data science tasks.