 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Chance-Constrained Optimization for Hierarchical UAV-based MEC
Mar 13, 2023



Multi-access edge computing (MEC) is regarded as a promising technology in the sixth-generation communication. However, the antenna gain is always affected by the environment when unmanned aerial vehicles (UAVs) are served as MEC platforms, resulting in unexpected channel errors. In order to deal with the problem and reduce the power consumption in the UAV-based MEC, we jointly optimize the access scheme and power allocation in the hierarchical UAV-based MEC. Specifically, UAVs are deployed in the lower layer to collect data from ground users. Moreover, a UAV with powerful computation ability is deployed in the upper layer to assist with computing. The goal is to guarantee the quality of service and minimize the total power consumption. We consider the errors caused by various perturbations in realistic circumstances and formulate a distributionally robust chance-constrained optimization problem with an uncertainty set. The problem with chance constraints is intractable. To tackle this issue, we utilize the conditional value-at-risk method to reformulate the problem into a semidefinite programming form. Then, a joint algorithm for access scheme and power allocation is designed. Finally, we conduct simulations to demonstrate the efficiency of the proposed algorithm.
SFC Deployment in Space-Air-Ground Integrated Networks Based on Matching Game
Mar 02, 2023The space-air-ground integrated network (SAGIN) is dynamic and flexible, which can support transmitting data in environments lacking ground communication facilities. However, the nodes of SAGIN are heterogeneous and it is intractable to share the resources to provide multiple services. Therefore, in this paper, we consider using network function virtualization technology to handle the problem of agile resource allocation. In particular, the service function chains (SFCs) are constructed to deploy multiple virtual network functions of different tasks. To depict the dynamic model of SAGIN, we propose the reconfigurable time extension graph. Then, an optimization problem is formulated to maximize the number of completed tasks, i.e., the successful deployed SFC. It is a mixed integer linear programming problem, which is hard to solve in limited time complexity. Hence, we transform it as a many-to-one two-sided matching game problem. Then, we design a Gale-Shapley based algorithm. Finally, via abundant simulations, it is verified that the designed algorithm can effectively deploy SFCs with efficient resource utilization.
TextIR: A Simple Framework for Text-based Editable Image Restoration
Feb 28, 2023



Most existing image restoration methods use neural networks to learn strong image-level priors from huge data to estimate the lost information. However, these works still struggle in cases when images have severe information deficits. Introducing external priors or using reference images to provide information also have limitations in the application domain. In contrast, text input is more readily available and provides information with higher flexibility. In this work, we design an effective framework that allows the user to control the restoration process of degraded images with text descriptions. We use the text-image feature compatibility of the CLIP to alleviate the difficulty of fusing text and image features. Our framework can be used for various image restoration tasks, including image inpainting, image super-resolution, and image colorization. Extensive experiments demonstrate the effectiveness of our method.
Computation Offloading for Uncertain Marine Tasks by Cooperation of UAVs and Vessels
Feb 13, 2023With the continuous increment of maritime applications, the development of marine networks for data offloading becomes necessary. However, the limited maritime network resources are very difficult to satisfy real-time demands. Besides, how to effectively handle multiple compute-intensive tasks becomes another intractable issue. Hence, in this paper, we focus on the decision of maritime task offloading by the cooperation of unmanned aerial vehicles (UAVs) and vessels. Specifically, we first propose a cooperative offloading framework, including the demands from marine Internet of Things (MIoTs) devices and resource providers from UAVs and vessels. Due to the limited energy and computation ability of UAVs, it is necessary to help better apply the vessels to computation offloading. Then, we formulate the studied problem into a Markov decision process, aiming to minimize the total execution time and energy cost. Then, we leverage Lyapunov optimization to convert the long-term constraints of the total execution time and energy cost into their short-term constraints, further yielding a set of per-time-slot optimization problems. Furthermore, we propose a Q-learning based approach to solve the short-term problem efficiently. Finally, simulation results are conducted to verify the correctness and effectiveness of the proposed algorithm.
OSRT: Omnidirectional Image Super-Resolution with Distortion-aware Transformer
Feb 09, 2023



Omnidirectional images (ODIs) have obtained lots of research interest for immersive experiences. Although ODIs require extremely high resolution to capture details of the entire scene, the resolutions of most ODIs are insufficient. Previous methods attempt to solve this issue by image super-resolution (SR) on equirectangular projection (ERP) images. However, they omit geometric properties of ERP in the degradation process, and their models can hardly generalize to real ERP images. In this paper, we propose Fisheye downsampling, which mimics the real-world imaging process and synthesizes more realistic low-resolution samples. Then we design a distortion-aware Transformer (OSRT) to modulate ERP distortions continuously and self-adaptively. Without a cumbersome process, OSRT outperforms previous methods by about 0.2dB on PSNR. Moreover, we propose a convenient data augmentation strategy, which synthesizes pseudo ERP images from plain images. This simple strategy can alleviate the over-fitting problem of large networks and significantly boost the performance of ODISR. Extensive experiments have demonstrated the state-of-the-art performance of our OSRT. Codes and models will be available at https://github.com/Fanghua-Yu/OSRT.
ITstyler: Image-optimized Text-based Style Transfer
Jan 26, 2023



Text-based style transfer is a newly-emerging research topic that uses text information instead of style image to guide the transfer process, significantly extending the application scenario of style transfer. However, previous methods require extra time for optimization or text-image paired data, leading to limited effectiveness. In this work, we achieve a data-efficient text-based style transfer method that does not require optimization at the inference stage. Specifically, we convert text input to the style space of the pre-trained VGG network to realize a more effective style swap. We also leverage CLIP's multi-modal embedding space to learn the text-to-style mapping with the image dataset only. Our method can transfer arbitrary new styles of text input in real-time and synthesize high-quality artistic images.
Towards Arbitrary Text-driven Image Manipulation via Space Alignment
Jan 25, 2023The recent GAN inversion methods have been able to successfully invert the real image input to the corresponding editable latent code in StyleGAN. By combining with the language-vision model (CLIP), some text-driven image manipulation methods are proposed. However, these methods require extra costs to perform optimization for a certain image or a new attribute editing mode. To achieve a more efficient editing method, we propose a new Text-driven image Manipulation framework via Space Alignment (TMSA). The Space Alignment module aims to align the same semantic regions in CLIP and StyleGAN spaces. Then, the text input can be directly accessed into the StyleGAN space and be used to find the semantic shift according to the text description. The framework can support arbitrary image editing mode without additional cost. Our work provides the user with an interface to control the attributes of a given image according to text input and get the result in real time. Ex tensive experiments demonstrate our superior performance over prior works.
Mitigating Artifacts in Real-World Video Super-Resolution Models
Dec 14, 2022



The recurrent structure is a prevalent framework for the task of video super-resolution, which models the temporal dependency between frames via hidden states. When applied to real-world scenarios with unknown and complex degradations, hidden states tend to contain unpleasant artifacts and propagate them to restored frames. In this circumstance, our analyses show that such artifacts can be largely alleviated when the hidden state is replaced with a cleaner counterpart. Based on the observations, we propose a Hidden State Attention (HSA) module to mitigate artifacts in real-world video super-resolution. Specifically, we first adopt various cheap filters to produce a hidden state pool. For example, Gaussian blur filters are for smoothing artifacts while sharpening filters are for enhancing details. To aggregate a new hidden state that contains fewer artifacts from the hidden state pool, we devise a Selective Cross Attention (SCA) module, in which the attention between input features and each hidden state is calculated. Equipped with HSA, our proposed method, namely FastRealVSR, is able to achieve 2x speedup while obtaining better performance than Real-BasicVSR. Codes will be available at https://github.com/TencentARC/FastRealVSR
AnimeRun: 2D Animation Visual Correspondence from Open Source 3D Movies
Nov 10, 2022



Existing correspondence datasets for two-dimensional (2D) cartoon suffer from simple frame composition and monotonic movements, making them insufficient to simulate real animations. In this work, we present a new 2D animation visual correspondence dataset, AnimeRun, by converting open source three-dimensional (3D) movies to full scenes in 2D style, including simultaneous moving background and interactions of multiple subjects. Our analyses show that the proposed dataset not only resembles real anime more in image composition, but also possesses richer and more complex motion patterns compared to existing datasets. With this dataset, we establish a comprehensive benchmark by evaluating several existing optical flow and segment matching methods, and analyze shortcomings of these methods on animation data. Data, code and other supplementary materials are available at https://lisiyao21.github.io/projects/AnimeRun.
Efficient Image Super-Resolution using Vast-Receptive-Field Attention
Oct 12, 2022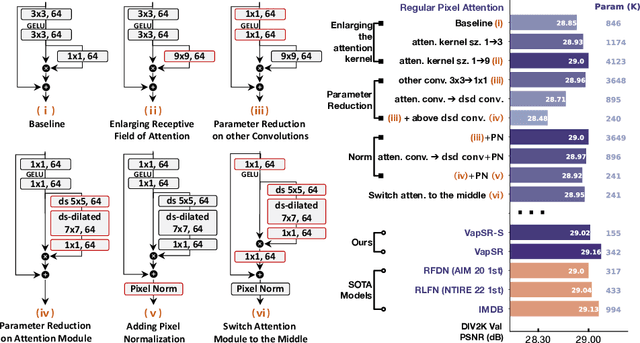
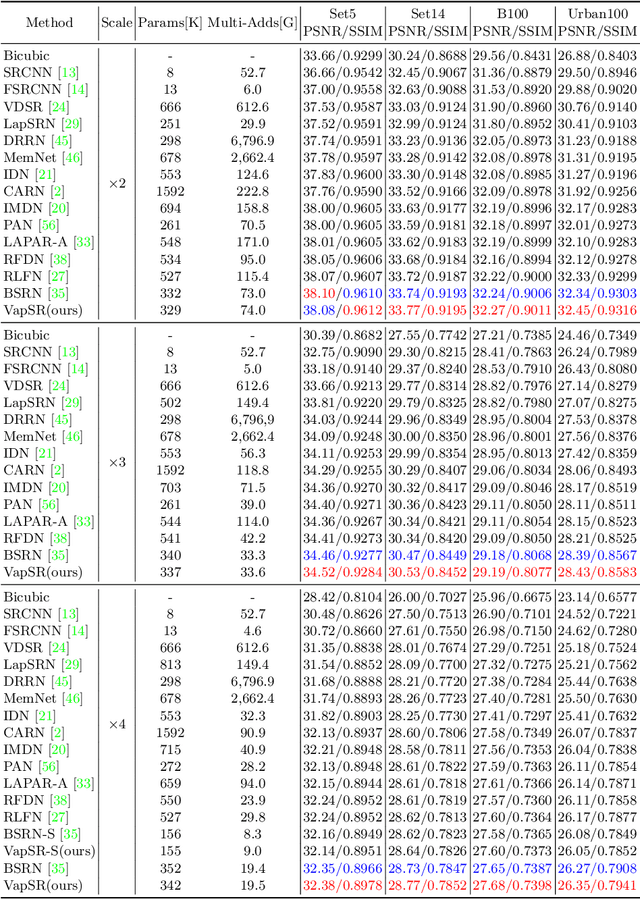
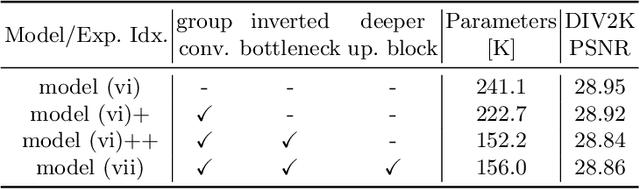
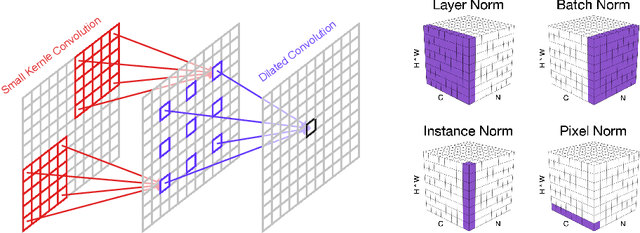
The attention mechanism plays a pivotal role in designing advanced super-resolution (SR) networks. In this work, we design an efficient SR network by improving the attention mechanism. We start from a simple pixel attention module and gradually modify it to achieve better super-resolution performance with reduced parameters. The specific approaches include: (1) increasing the receptive field of the attention branch, (2) replacing large dense convolution kernels with depth-wise separable convolutions, and (3) introducing pixel normalization. These approaches paint a clear evolutionary roadmap for the design of attention mechanisms. Based on these observations, we propose VapSR, the VAst-receptive-field Pixel attention network. Experiments demonstrate the superior performance of VapSR. VapSR outperforms the present lightweight networks with even fewer parameters. And the light version of VapSR can use only 21.68% and 28.18% parameters of IMDB and RFDN to achieve similar performances to those networks. The code and models are available at url{https://github.com/zhoumumu/VapSR.