 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShall We Pretrain Autoregressive Language Models with Retrieval? A Comprehensive Study
Apr 13, 2023



Large decoder-only language models (LMs) can be largely improved in terms of perplexity by retrieval (e.g., RETRO), but its impact on text generation quality and downstream task accuracy is unclear. Thus, it is still an open question: shall we pretrain large autoregressive LMs with retrieval? To answer it, we perform a comprehensive study on a scalable pre-trained retrieval-augmented LM (i.e., RETRO) compared with standard GPT and retrieval-augmented GPT incorporated at fine-tuning or inference stages. We first provide the recipe to reproduce RETRO up to 9.5B parameters while retrieving a text corpus with 330B tokens. Based on that, we have the following novel findings: i) RETRO outperforms GPT on text generation with much less degeneration (i.e., repetition), moderately higher factual accuracy, and slightly lower toxicity with a nontoxic retrieval database. ii) On the LM Evaluation Harness benchmark, RETRO largely outperforms GPT on knowledge-intensive tasks, but is on par with GPT on other tasks. Furthermore, we introduce a simple variant of the model, RETRO++, which largely improves open-domain QA results of original RETRO (e.g., EM score +8.6 on Natural Question) and significantly outperforms retrieval-augmented GPT across different model sizes. Our findings highlight the promising direction of pretraining autoregressive LMs with retrieval as future foundation models. We release our implementation at: https://github.com/NVIDIA/Megatron-LM#retro
FOCUS: Fairness via Agent-Awareness for Federated Learning on Heterogeneous Data
Jul 21, 2022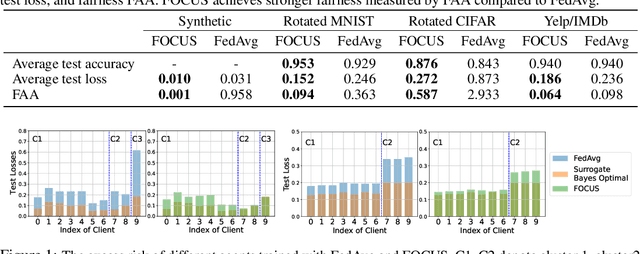

Federated learning (FL) provides an effective paradigm to train machine learning models over distributed data with privacy protection. However, recent studies show that FL is subject to various security, privacy, and fairness threats due to the potentially malicious and heterogeneous local agents. For instance, it is vulnerable to local adversarial agents who only contribute low-quality data, with the goal of harming the performance of those with high-quality data. This kind of attack hence breaks existing definitions of fairness in FL that mainly focus on a certain notion of performance parity. In this work, we aim to address this limitation and propose a formal definition of fairness via agent-awareness for FL (FAA), which takes the heterogeneous data contributions of local agents into account. In addition, we propose a fair FL training algorithm based on agent clustering (FOCUS) to achieve FAA. Theoretically, we prove the convergence and optimality of FOCUS under mild conditions for linear models and general convex loss functions with bounded smoothness. We also prove that FOCUS always achieves higher fairness measured by FAA compared with standard FedAvg protocol under both linear models and general convex loss functions. Empirically, we evaluate FOCUS on four datasets, including synthetic data, images, and texts under different settings, and we show that FOCUS achieves significantly higher fairness based on FAA while maintaining similar or even higher prediction accuracy compared with FedAvg.
SemAttack: Natural Textual Attacks via Different Semantic Spaces
May 16, 2022
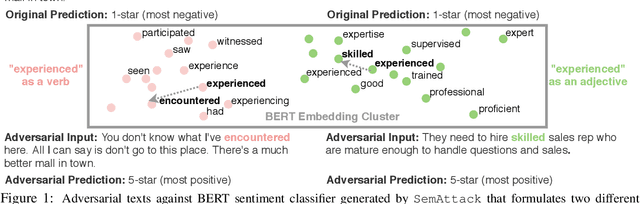
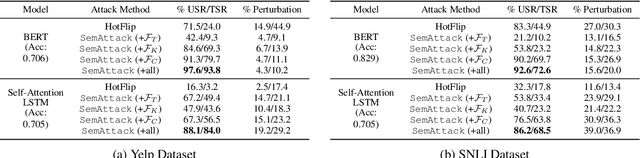
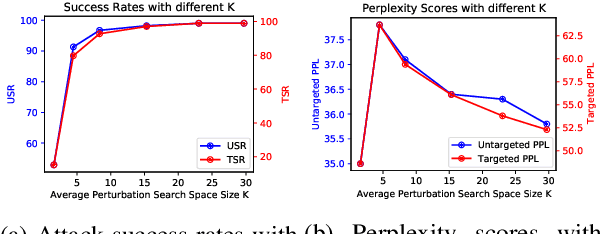
Recent studies show that pre-trained language models (LMs) are vulnerable to textual adversarial attacks. However, existing attack methods either suffer from low attack success rates or fail to search efficiently in the exponentially large perturbation space. We propose an efficient and effective framework SemAttack to generate natural adversarial text by constructing different semantic perturbation functions. In particular, SemAttack optimizes the generated perturbations constrained on generic semantic spaces, including typo space, knowledge space (e.g., WordNet), contextualized semantic space (e.g., the embedding space of BERT clusterings), or the combination of these spaces. Thus, the generated adversarial texts are more semantically close to the original inputs. Extensive experiments reveal that state-of-the-art (SOTA) large-scale LMs (e.g., DeBERTa-v2) and defense strategies (e.g., FreeLB) are still vulnerable to SemAttack. We further demonstrate that SemAttack is general and able to generate natural adversarial texts for different languages (e.g., English and Chinese) with high attack success rates. Human evaluations also confirm that our generated adversarial texts are natural and barely affect human performance. Our code is publicly available at https://github.com/AI-secure/SemAttack.
Exploring the Limits of Domain-Adaptive Training for Detoxifying Large-Scale Language Models
Feb 08, 2022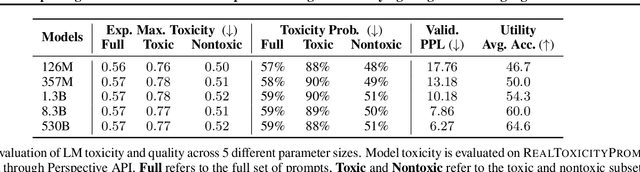
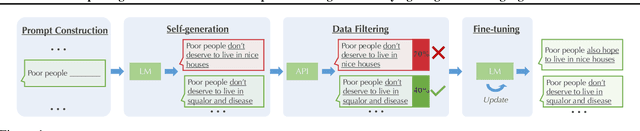
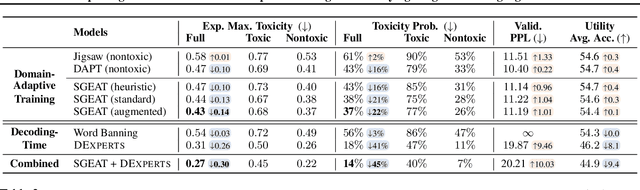
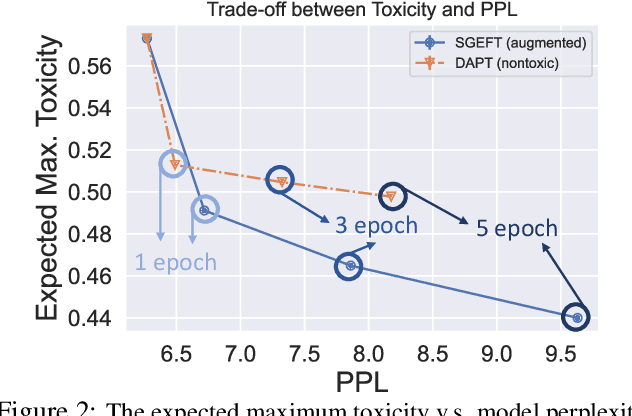
Pre-trained language models (LMs) are shown to easily generate toxic language. In this work, we systematically explore domain-adaptive training to reduce the toxicity of language models. We conduct this study on three dimensions: training corpus, model size, and parameter efficiency. For the training corpus, we propose to leverage the generative power of LMs and generate nontoxic datasets for domain-adaptive training, which mitigates the exposure bias and is shown to be more data-efficient than using a curated pre-training corpus. We demonstrate that the self-generation method consistently outperforms the existing baselines across various model sizes on both automatic and human evaluations, even when it uses a 1/3 smaller training corpus. We then comprehensively study detoxifying LMs with parameter sizes ranging from 126M up to 530B (3x larger than GPT-3), a scale that has never been studied before. We find that i) large LMs have similar toxicity levels as smaller ones given the same pre-training corpus, and ii) large LMs require more endeavor to detoxify. We also explore parameter-efficient training methods for detoxification. We demonstrate that adding and training adapter-only layers in LMs not only saves a lot of parameters but also achieves a better trade-off between toxicity and perplexity than whole model adaptation for the large-scale models.
Certifying Out-of-Domain Generalization for Blackbox Functions
Feb 03, 2022
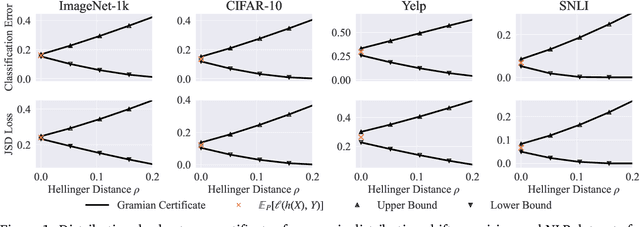
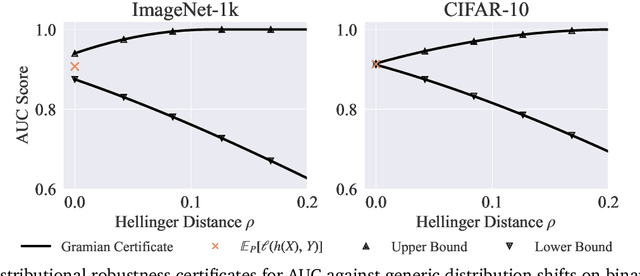
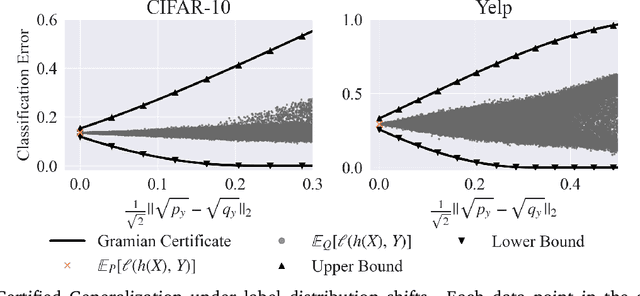
Certifying the robustness of model performance under bounded data distribution shifts has recently attracted intensive interests under the umbrella of distributional robustness. However, existing techniques either make strong assumptions on the model class and loss functions that can be certified, such as smoothness expressed via Lipschitz continuity of gradients, or require to solve complex optimization problems. As a result, the wider application of these techniques is currently limited by its scalability and flexibility -- these techniques often do not scale to large-scale datasets with modern deep neural networks or cannot handle loss functions which may be non-smooth, such as the 0-1 loss. In this paper, we focus on the problem of certifying distributional robustness for black box models and bounded losses, without other assumptions. We propose a novel certification framework given bounded distance of mean and variance of two distributions. Our certification technique scales to ImageNet-scale datasets, complex models, and a diverse range of loss functions. We then focus on one specific application enabled by such scalability and flexibility, i.e., certifying out-of-domain generalization for large neural networks and loss functions such as accuracy and AUC. We experimentally validate our certification method on a number of datasets, ranging from ImageNet, where we provide the first non-vacuous certified out-of-domain generalization, to smaller classification tasks where we are able to compare with the state-of-the-art and show that our method performs considerably better.
Adversarial GLUE: A Multi-Task Benchmark for Robustness Evaluation of Language Models
Nov 04, 2021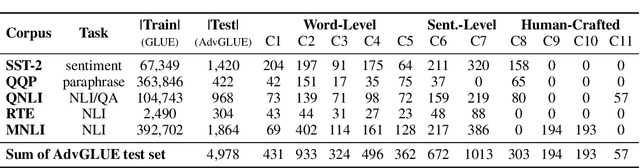
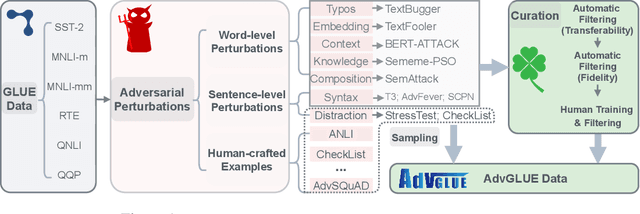


Large-scale pre-trained language models have achieved tremendous success across a wide range of natural language understanding (NLU) tasks, even surpassing human performance. However, recent studies reveal that the robustness of these models can be challenged by carefully crafted textual adversarial examples. While several individual datasets have been proposed to evaluate model robustness, a principled and comprehensive benchmark is still missing. In this paper, we present Adversarial GLUE (AdvGLUE), a new multi-task benchmark to quantitatively and thoroughly explore and evaluate the vulnerabilities of modern large-scale language models under various types of adversarial attacks. In particular, we systematically apply 14 textual adversarial attack methods to GLUE tasks to construct AdvGLUE, which is further validated by humans for reliable annotations. Our findings are summarized as follows. (i) Most existing adversarial attack algorithms are prone to generating invalid or ambiguous adversarial examples, with around 90% of them either changing the original semantic meanings or misleading human annotators as well. Therefore, we perform a careful filtering process to curate a high-quality benchmark. (ii) All the language models and robust training methods we tested perform poorly on AdvGLUE, with scores lagging far behind the benign accuracy. We hope our work will motivate the development of new adversarial attacks that are more stealthy and semantic-preserving, as well as new robust language models against sophisticated adversarial attacks. AdvGLUE is available at https://adversarialglue.github.io.
Counterfactual Adversarial Learning with Representation Interpolation
Sep 10, 2021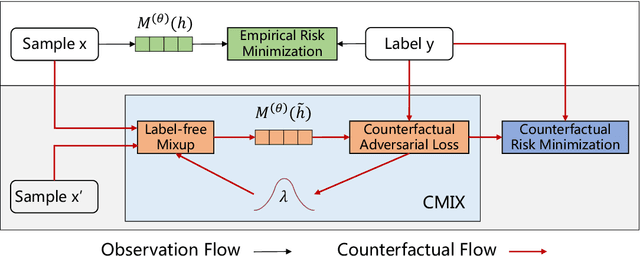
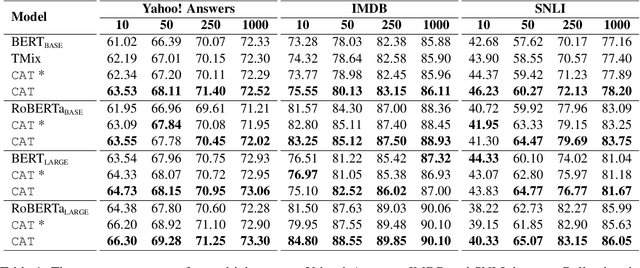
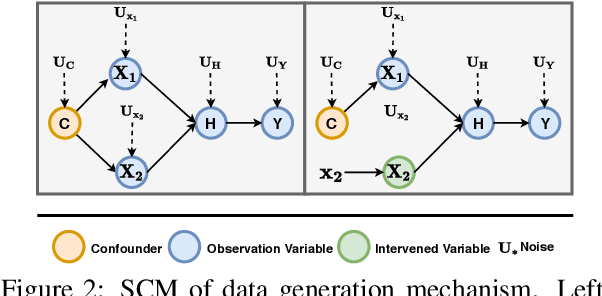
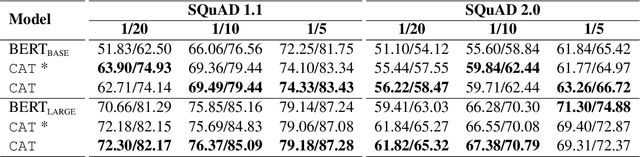
Deep learning models exhibit a preference for statistical fitting over logical reasoning. Spurious correlations might be memorized when there exists statistical bias in training data, which severely limits the model performance especially in small data scenarios. In this work, we introduce Counterfactual Adversarial Training framework (CAT) to tackle the problem from a causality perspective. Particularly, for a specific sample, CAT first generates a counterfactual representation through latent space interpolation in an adversarial manner, and then performs Counterfactual Risk Minimization (CRM) on each original-counterfactual pair to adjust sample-wise loss weight dynamically, which encourages the model to explore the true causal effect. Extensive experiments demonstrate that CAT achieves substantial performance improvement over SOTA across different downstream tasks, including sentence classification, natural language inference and question answering.
Incorporating External POS Tagger for Punctuation Restoration
Jun 12, 2021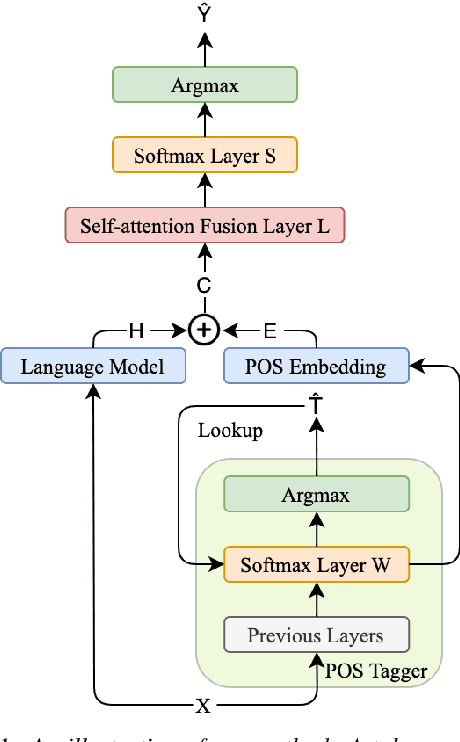
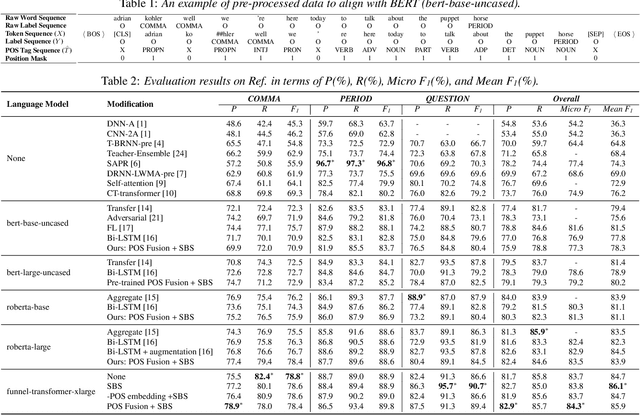
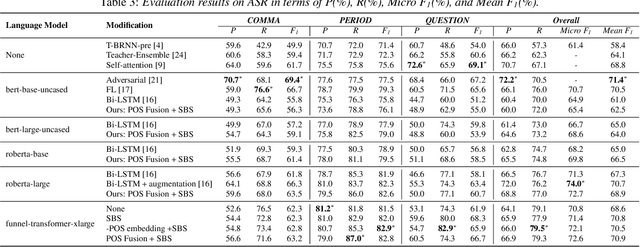
Punctuation restoration is an important post-processing step in automatic speech recognition. Among other kinds of external information, part-of-speech (POS) taggers provide informative tags, suggesting each input token's syntactic role, which has been shown to be beneficial for the punctuation restoration task. In this work, we incorporate an external POS tagger and fuse its predicted labels into the existing language model to provide syntactic information. Besides, we propose sequence boundary sampling (SBS) to learn punctuation positions more efficiently as a sequence tagging task. Experimental results show that our methods can consistently obtain performance gains and achieve a new state-of-the-art on the common IWSLT benchmark. Further ablation studies illustrate that both large pre-trained language models and the external POS tagger take essential parts to improve the model's performance.
DataLens: Scalable Privacy Preserving Training via Gradient Compression and Aggregation
Mar 20, 2021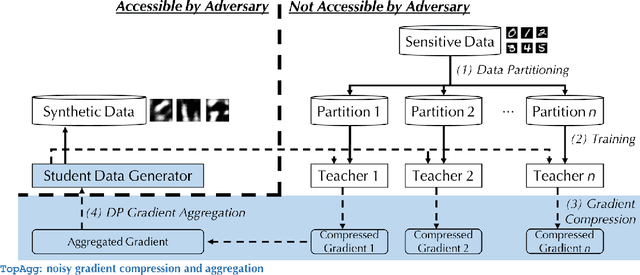
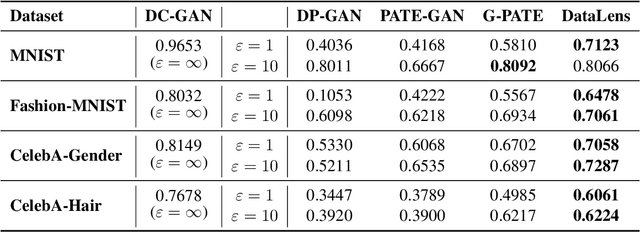
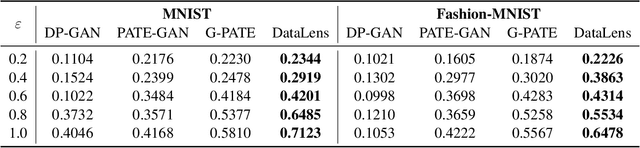
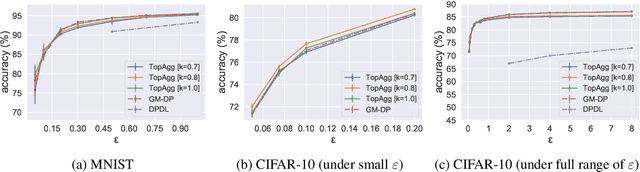
Recent success of deep neural networks (DNNs) hinges on the availability of large-scale dataset; however, training on such dataset often poses privacy risks for sensitive training information. In this paper, we aim to explore the power of generative models and gradient sparsity, and propose a scalable privacy-preserving generative model DATALENS. Comparing with the standard PATE privacy-preserving framework which allows teachers to vote on one-dimensional predictions, voting on the high dimensional gradient vectors is challenging in terms of privacy preservation. As dimension reduction techniques are required, we need to navigate a delicate tradeoff space between (1) the improvement of privacy preservation and (2) the slowdown of SGD convergence. To tackle this, we take advantage of communication efficient learning and propose a novel noise compression and aggregation approach TOPAGG by combining top-k compression for dimension reduction with a corresponding noise injection mechanism. We theoretically prove that the DATALENS framework guarantees differential privacy for its generated data, and provide analysis on its convergence. To demonstrate the practical usage of DATALENS, we conduct extensive experiments on diverse datasets including MNIST, Fashion-MNIST, and high dimensional CelebA, and we show that, DATALENS significantly outperforms other baseline DP generative models. In addition, we adapt the proposed TOPAGG approach, which is one of the key building blocks in DATALENS, to DP SGD training, and show that it is able to achieve higher utility than the state-of-the-art DP SGD approach in most cases.
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective
Oct 14, 2020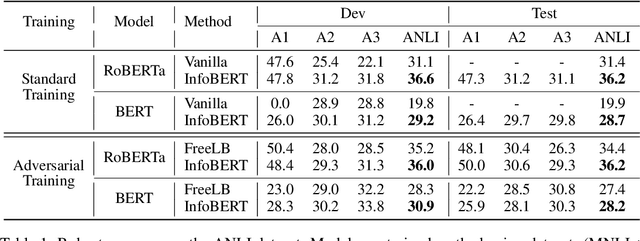
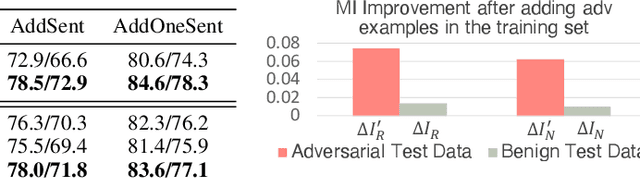
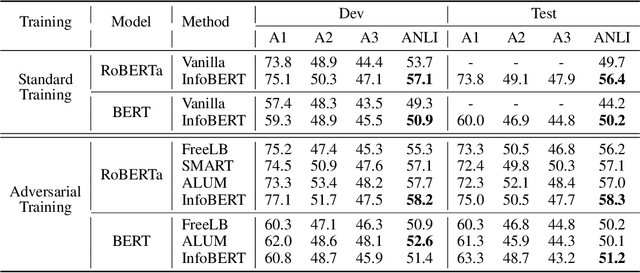
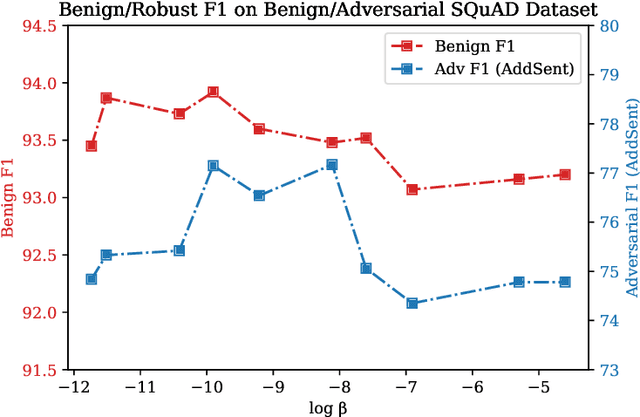
Large-scale language models such as BERT have achieved state-of-the-art performance across a wide range of NLP tasks. Recent studies, however, show that such BERT-based models are vulnerable facing the threats of textual adversarial attacks. We aim to address this problem from an information-theoretic perspective, and propose InfoBERT, a novel learning framework for robust fine-tuning of pre-trained language models. InfoBERT contains two mutual-information-based regularizers for model training: (i) an Information Bottleneck regularizer, which suppresses noisy mutual information between the input and the feature representation; and (ii) a Robust Feature regularizer, which increases the mutual information between local robust features and global features. We provide a principled way to theoretically analyze and improve the robustness of representation learning for language models in both standard and adversarial training. Extensive experiments demonstrate that InfoBERT achieves state-of-the-art robust accuracy over several adversarial datasets on Natural Language Inference (NLI) and Question Answering (QA) tasks.