 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Generalizable Safety Steering for Text-to-Image Diffusion Transformers
May 28, 2026Diffusion Transformers have become a powerful backbone for text-to-image generation, but their layered and cross-modal generation process makes safety control fundamentally different from prompt-level filtering or output-level detection. Harmful semantics may be weakly expressed in text representations, progressively bound to visual latents, and finally entangled with rendering dynamics. As a result, safety steering at a fixed layer can be unstable, and a steering mechanism learned from known risks may not transfer reliably to a shifted target risk domain. We propose SafeDIG, a safety steering framework that formulates DiT safety adaptation as position-aware sparse feature transfer. SafeDIG first constructs Sparse Autoencoders over functionally distinct DiT intervention positions and uses robustness-aware pre-training routing to prioritize intervention sites that are expected to remain stable under source-target risk shift. It then separates transferable safety features from domain-specific activation geometry by freezing the SAE encoder as a reusable sparse safety dictionary and adapting only the decoder to the target-domain activation manifold. During inference, SafeDIG combines Blend and Repel operations to steer unsafe activations toward transferred safety manifolds or away from harmful sparse directions. Experiments on FLUX.1 Dev and Stable Diffusion 3.5 Large show that SafeDIG consistently reduces target-domain and overall unsafe generation rates while preserving source-domain safety and image quality.
Make LLM Learn to Synthesize from Streaming Experiences through Feedback
May 28, 2026Large language models (LLMs) have been widely adopted for synthetic data generation, significantly reducing annotation costs. However, most existing studies treat synthesis as a set of isolated tasks and overlook a more fundamental question: whether a model can learn to synthesize by accumulating experience from past tasks and transferring it to future ones. In this work, we introduce StreamSynth, a new setting in which synthesis tasks arrive sequentially and experience from historical tasks provides informative signals for future synthesis. To address this setting, we propose SynLearner, a general framework that enables synthesis models to acquire reusable synthesis experience over a task stream. Instead of generating data independently for each task, SynLearner encourages the model to explore diverse synthesis patterns, learn from feedback, and balance sample quality with set-level diversity as tasks evolve. Extensive experiments across multiple benchmarks show that SynLearner effectively leverages experience from earlier tasks to improve synthesis performance on later ones, exhibiting consistent cross-task transferability. These findings provide evidence for the feasibility of StreamSynth and highlight synthetic data generation as an experience-driven process that can benefit from task streams.
Counterfactual Adversarial Learning with Representation Interpolation
Sep 10, 2021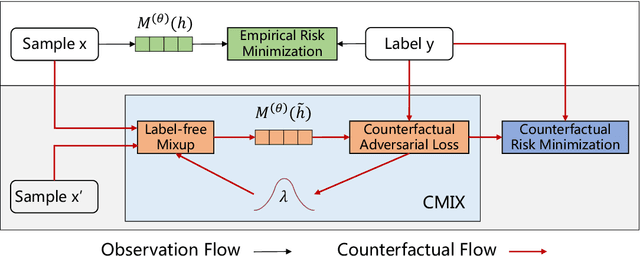
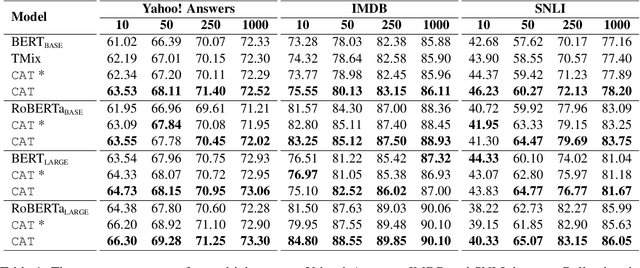
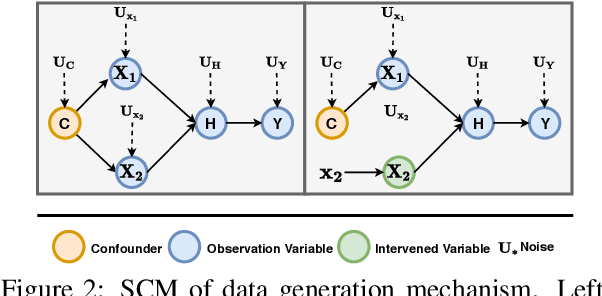
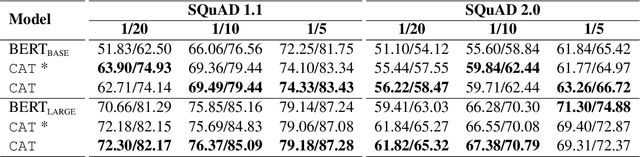
Deep learning models exhibit a preference for statistical fitting over logical reasoning. Spurious correlations might be memorized when there exists statistical bias in training data, which severely limits the model performance especially in small data scenarios. In this work, we introduce Counterfactual Adversarial Training framework (CAT) to tackle the problem from a causality perspective. Particularly, for a specific sample, CAT first generates a counterfactual representation through latent space interpolation in an adversarial manner, and then performs Counterfactual Risk Minimization (CRM) on each original-counterfactual pair to adjust sample-wise loss weight dynamically, which encourages the model to explore the true causal effect. Extensive experiments demonstrate that CAT achieves substantial performance improvement over SOTA across different downstream tasks, including sentence classification, natural language inference and question answering.