 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Graph Neural Networking Challenge: A Worldwide Competition for Education in AI/ML for Networks
Jul 26, 2021
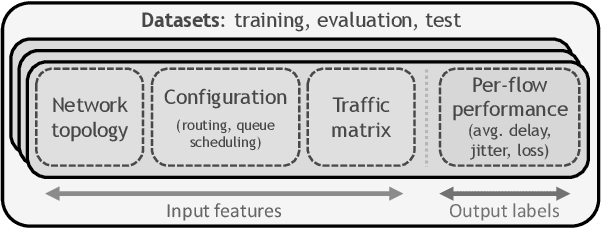

During the last decade, Machine Learning (ML) has increasingly become a hot topic in the field of Computer Networks and is expected to be gradually adopted for a plethora of control, monitoring and management tasks in real-world deployments. This poses the need to count on new generations of students, researchers and practitioners with a solid background in ML applied to networks. During 2020, the International Telecommunication Union (ITU) has organized the "ITU AI/ML in 5G challenge'', an open global competition that has introduced to a broad audience some of the current main challenges in ML for networks. This large-scale initiative has gathered 23 different challenges proposed by network operators, equipment manufacturers and academia, and has attracted a total of 1300+ participants from 60+ countries. This paper narrates our experience organizing one of the proposed challenges: the "Graph Neural Networking Challenge 2020''. We describe the problem presented to participants, the tools and resources provided, some organization aspects and participation statistics, an outline of the top-3 awarded solutions, and a summary with some lessons learned during all this journey. As a result, this challenge leaves a curated set of educational resources openly available to anyone interested in the topic.
Token-Level Supervised Contrastive Learning for Punctuation Restoration
Jul 19, 2021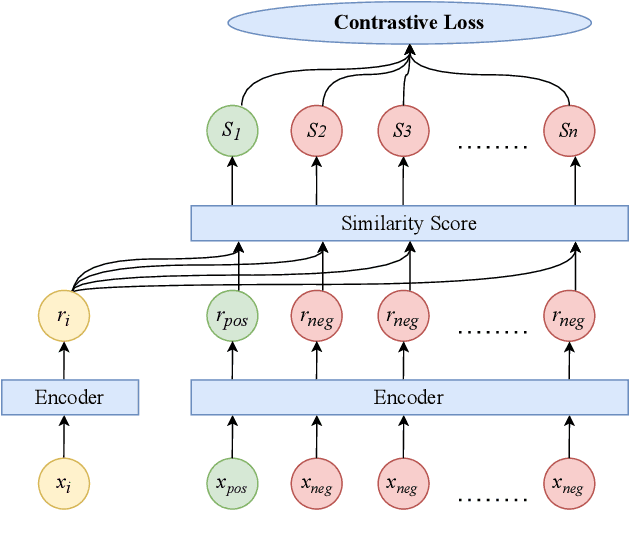
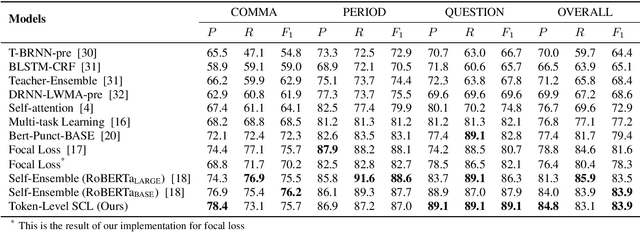

Punctuation is critical in understanding natural language text. Currently, most automatic speech recognition (ASR) systems do not generate punctuation, which affects the performance of downstream tasks, such as intent detection and slot filling. This gives rise to the need for punctuation restoration. Recent work in punctuation restoration heavily utilizes pre-trained language models without considering data imbalance when predicting punctuation classes. In this work, we address this problem by proposing a token-level supervised contrastive learning method that aims at maximizing the distance of representation of different punctuation marks in the embedding space. The result shows that training with token-level supervised contrastive learning obtains up to 3.2% absolute F1 improvement on the test set.
TeCANet: Temporal-Contextual Attention Network for Environment-Aware Speech Dereverberation
Mar 31, 2021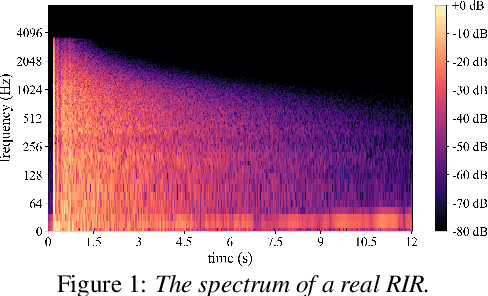
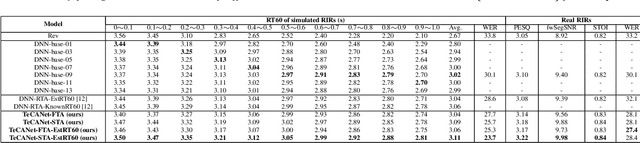
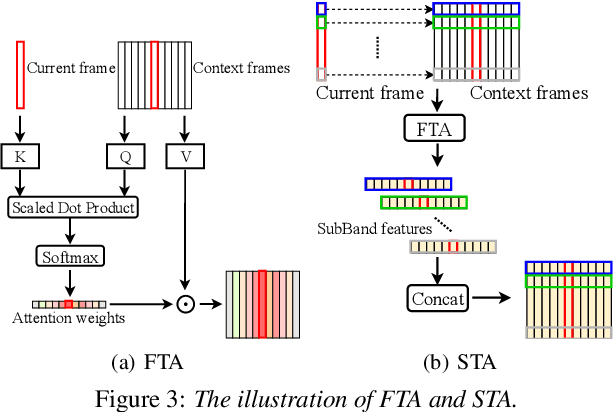
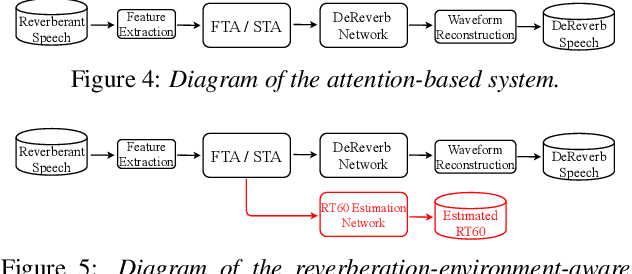
In this paper, we exploit the effective way to leverage contextual information to improve the speech dereverberation performance in real-world reverberant environments. We propose a temporal-contextual attention approach on the deep neural network (DNN) for environment-aware speech dereverberation, which can adaptively attend to the contextual information. More specifically, a FullBand based Temporal Attention approach (FTA) is proposed, which models the correlations between the fullband information of the context frames. In addition, considering the difference between the attenuation of high frequency bands and low frequency bands (high frequency bands attenuate faster than low frequency bands) in the room impulse response (RIR), we also propose a SubBand based Temporal Attention approach (STA). In order to guide the network to be more aware of the reverberant environments, we jointly optimize the dereverberation network and the reverberation time (RT60) estimator in a multi-task manner. Our experimental results indicate that the proposed method outperforms our previously proposed reverberation-time-aware DNN and the learned attention weights are fully physical consistent. We also report a preliminary yet promising dereverberation and recognition experiment on real test data.
Privacy-Preserving Teacher-Student Deep Reinforcement Learning
Feb 18, 2021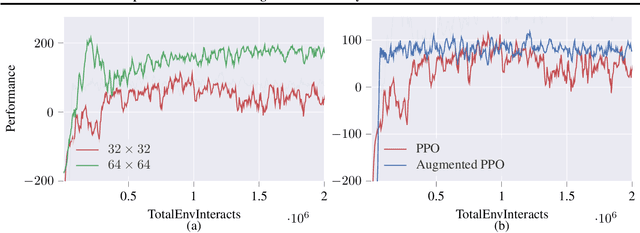
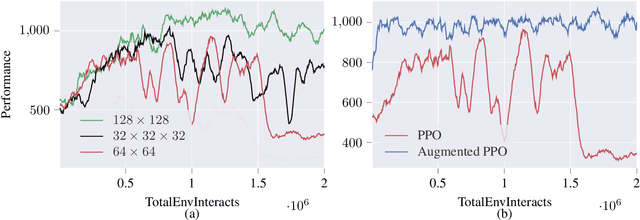
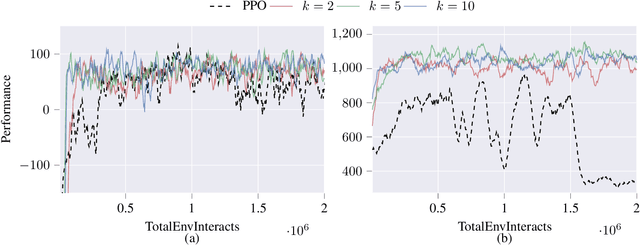
Deep reinforcement learning agents may learn complex tasks more efficiently when they coordinate with one another. We consider a teacher-student coordination scheme wherein an agent may ask another agent for demonstrations. Despite the benefits of sharing demonstrations, however, potential adversaries may obtain sensitive information belonging to the teacher by observing the demonstrations. In particular, deep reinforcement learning algorithms are known to be vulnerable to membership attacks, which make accurate inferences about the membership of the entries of training datasets. Therefore, there is a need to safeguard the teacher against such privacy threats. We fix the teacher's policy as the context of the demonstrations, which allows for different internal models across the student and the teacher, and contrasts the existing methods. We make the following two contributions. (i) We develop a differentially private mechanism that protects the privacy of the teacher's training dataset. (ii) We propose a proximal policy-optimization objective that enables the student to benefit from the demonstrations despite the perturbations of the privacy mechanism. We empirically show that the algorithm improves the student's learning upon convergence rate and utility. Specifically, compared with an agent who learns the same task on its own, we observe that the student's policy converges faster, and the converging policy accumulates higher rewards more robustly.
MG-SAGC: A multiscale graph and its self-adaptive graph convolution network for 3D point clouds
Dec 23, 2020
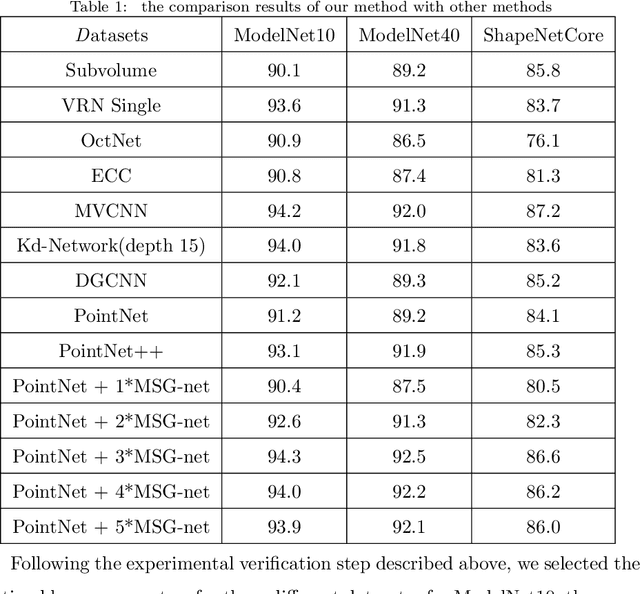
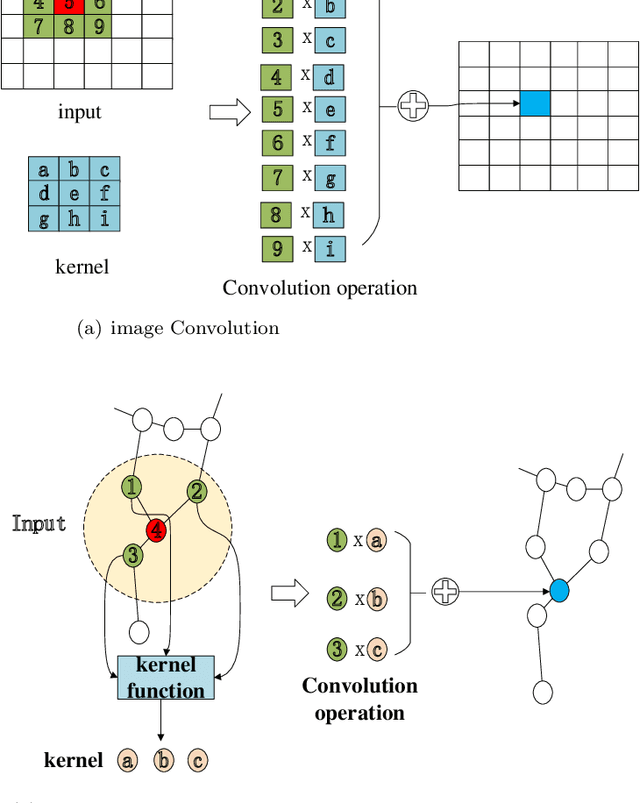
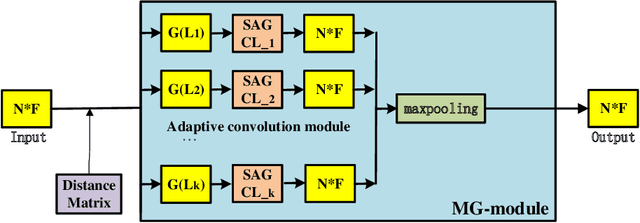
To enhance the ability of neural networks to extract local point cloud features and improve their quality, in this paper, we propose a multiscale graph generation method and a self-adaptive graph convolution method. First, we propose a multiscale graph generation method for point clouds. This approach transforms point clouds into a structured multiscale graph form that supports multiscale analysis of point clouds in the scale space and can obtain the dimensional features of point cloud data at different scales, thus making it easier to obtain the best point cloud features. Because traditional convolutional neural networks are not applicable to graph data with irregular vertex neighborhoods, this paper presents an sef-adaptive graph convolution kernel that uses the Chebyshev polynomial to fit an irregular convolution filter based on the theory of optimal approximation. In this paper, we adopt max pooling to synthesize the features of different scale maps and generate the point cloud features. In experiments conducted on three widely used public datasets, the proposed method significantly outperforms other state-of-the-art models, demonstrating its effectiveness and generalizability.
Analogical Reasoning for Visually Grounded Language Acquisition
Jul 22, 2020
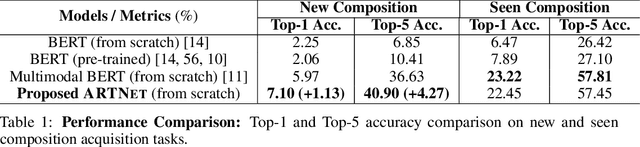
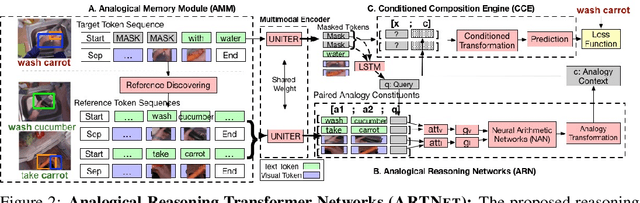

Children acquire language subconsciously by observing the surrounding world and listening to descriptions. They can discover the meaning of words even without explicit language knowledge, and generalize to novel compositions effortlessly. In this paper, we bring this ability to AI, by studying the task of Visually grounded Language Acquisition (VLA). We propose a multimodal transformer model augmented with a novel mechanism for analogical reasoning, which approximates novel compositions by learning semantic mapping and reasoning operations from previously seen compositions. Our proposed method, Analogical Reasoning Transformer Networks (ARTNet), is trained on raw multimedia data (video frames and transcripts), and after observing a set of compositions such as "washing apple" or "cutting carrot", it can generalize and recognize new compositions in new video frames, such as "washing carrot" or "cutting apple". To this end, ARTNet refers to relevant instances in the training data and uses their visual features and captions to establish analogies with the query image. Then it chooses the suitable verb and noun to create a new composition that describes the new image best. Extensive experiments on an instructional video dataset demonstrate that the proposed method achieves significantly better generalization capability and recognition accuracy compared to state-of-the-art transformer models.
Reward Machines for Cooperative Multi-Agent Reinforcement Learning
Jul 03, 2020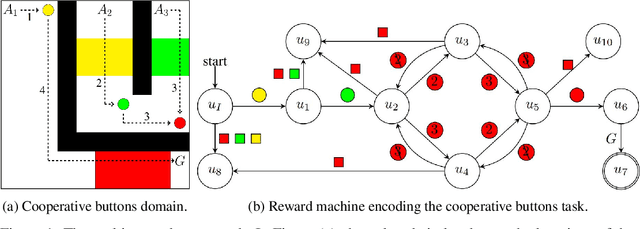
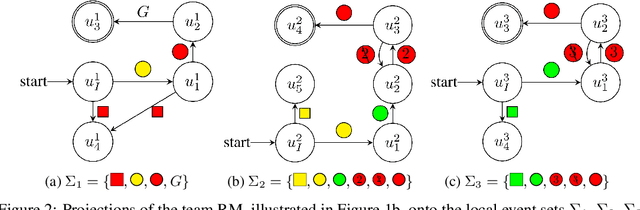
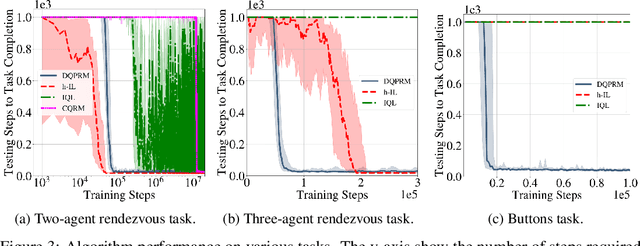
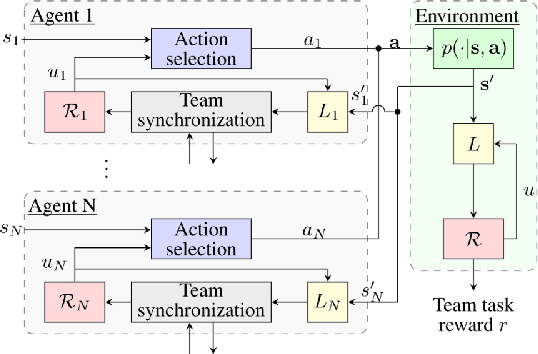
In cooperative multi-agent reinforcement learning, a collection of agents learns to interact in a shared environment to achieve a common goal. We propose the use of reward machines (RM) -- Mealy machines used as structured representations of reward functions -- to encode the team's task. The proposed novel interpretation of RMs in the multi-agent setting explicitly encodes required teammate interdependencies and independencies, allowing the team-level task to be decomposed into sub-tasks for individual agents. We define such a notion of RM decomposition and present algorithmically verifiable conditions guaranteeing that distributed completion of the sub-tasks leads to team behavior accomplishing the original task. This framework for task decomposition provides a natural approach to decentralized learning: agents may learn to accomplish their sub-tasks while observing only their local state and abstracted representations of their teammates. We accordingly propose a decentralized q-learning algorithm. Furthermore, in the case of undiscounted rewards, we use local value functions to derive lower and upper bounds for the global value function corresponding to the team task. Experimental results in three discrete settings exemplify the effectiveness of the proposed RM decomposition approach, which converges to a successful team policy two orders of magnitude faster than a centralized learner and significantly outperforms hierarchical and independent q-learning approaches.
Temporal-Logic-Based Reward Shaping for Continuing Learning Tasks
Jul 03, 2020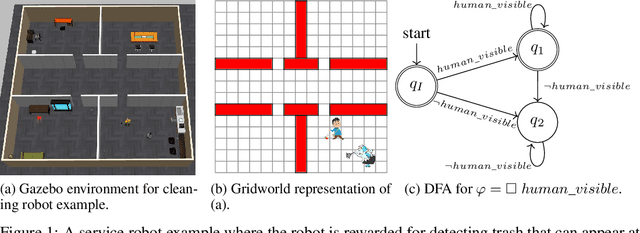
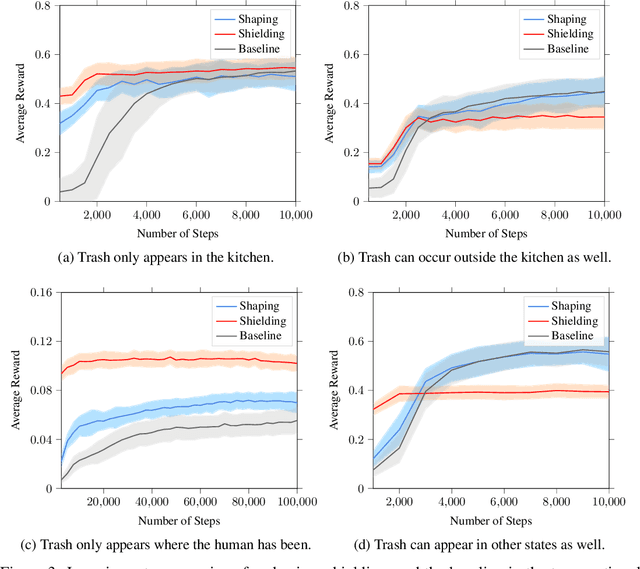
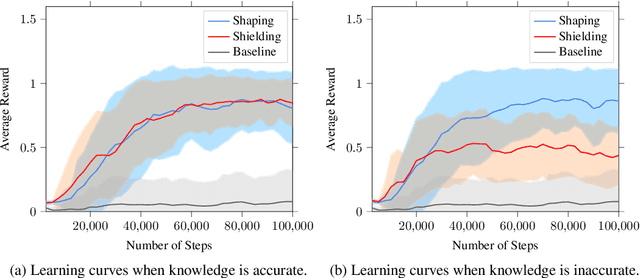
In continuing tasks, average-reward reinforcement learning may be a more appropriate problem formulation than the more common discounted reward formulation. As usual, learning an optimal policy in this setting typically requires a large amount of training experiences. Reward shaping is a common approach for incorporating domain knowledge into reinforcement learning in order to speed up convergence to an optimal policy. However, to the best of our knowledge, the theoretical properties of reward shaping have thus far only been established in the discounted setting. This paper presents the first reward shaping framework for average-reward learning and proves that, under standard assumptions, the optimal policy under the original reward function can be recovered. In order to avoid the need for manual construction of the shaping function, we introduce a method for utilizing domain knowledge expressed as a temporal logic formula. The formula is automatically translated to a shaping function that provides additional reward throughout the learning process. We evaluate the proposed method on three continuing tasks. In all cases, shaping speeds up the average-reward learning rate without any reduction in the performance of the learned policy compared to relevant baselines.
Active Finite Reward Automaton Inference and Reinforcement Learning Using Queries and Counterexamples
Jun 28, 2020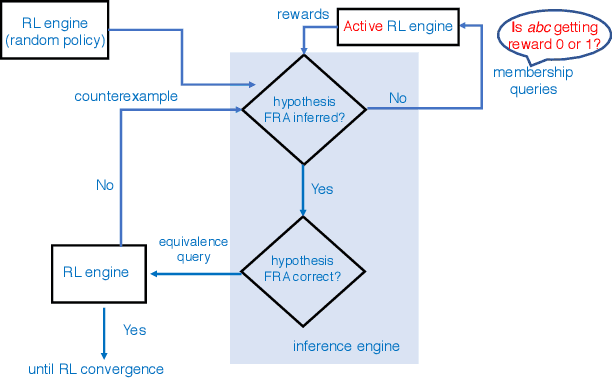
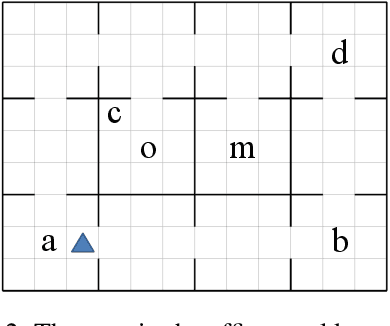
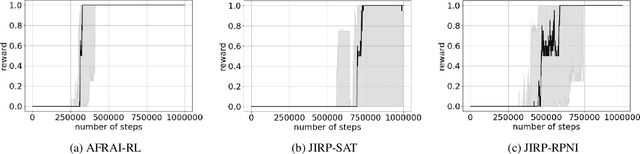
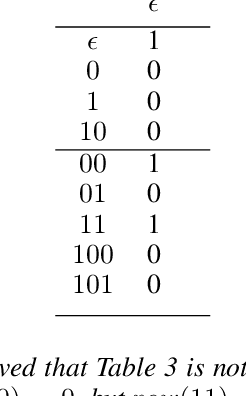
Despite the fact that deep reinforcement learning (RL) has surpassed human-level performances in various tasks, it still has several fundamental challenges such as extensive data requirement and lack of interpretability. We investigate the RL problem with non-Markovian reward functions to address such challenges. We enable an RL agent to extract high-level knowledge in the form of finite reward automata, a type of Mealy machines that encode non-Markovian reward functions. The finite reward automata can be converted to deterministic finite state machines, which can be further translated to regular expressions. Thus, this representation is more interpretable than other forms of knowledge representation such as neural networks. We propose an active learning approach that iteratively infers finite reward automata and performs RL (specifically, q-learning) based on the inferred finite reward automata. The inference method is inspired by the L* learning algorithm, and modified in the framework of RL. We maintain two different q-functions, one for answering the membership queries in the L* learning algorithm and the other one for obtaining optimal policies for the inferred finite reward automaton. The experiments show that the proposed approach converges to optimal policies in at most 50% of the training steps as in the two state-of-the-art baselines.
Learning the Compositional Visual Coherence for Complementary Recommendations
Jun 08, 2020
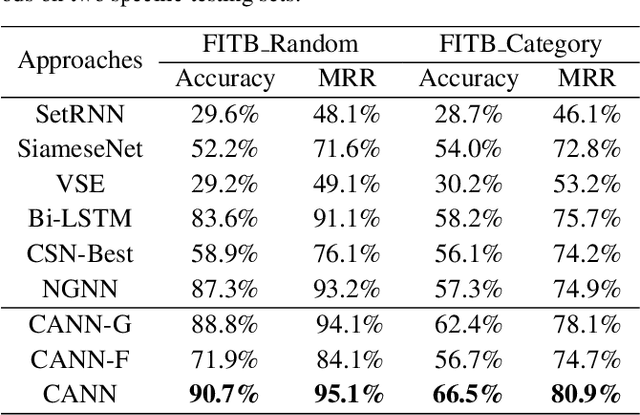
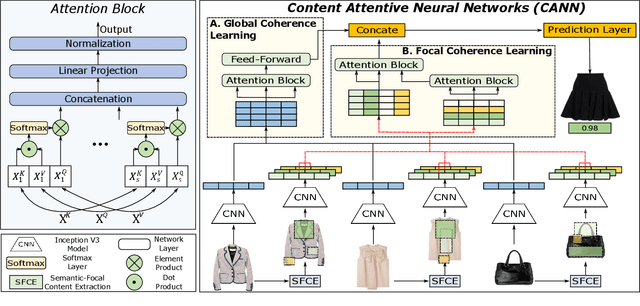
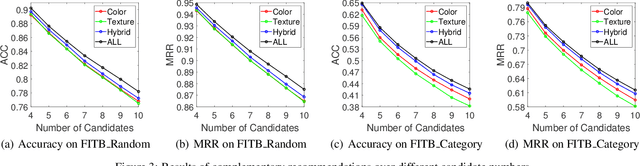
Complementary recommendations, which aim at providing users product suggestions that are supplementary and compatible with their obtained items, have become a hot topic in both academia and industry in recent years. %However, it is challenging due to its complexity and subjectivity. Existing work mainly focused on modeling the co-purchased relations between two items, but the compositional associations of item collections are largely unexplored. Actually, when a user chooses the complementary items for the purchased products, it is intuitive that she will consider the visual semantic coherence (such as color collocations, texture compatibilities) in addition to global impressions. Towards this end, in this paper, we propose a novel Content Attentive Neural Network (CANN) to model the comprehensive compositional coherence on both global contents and semantic contents. Specifically, we first propose a \textit{Global Coherence Learning} (GCL) module based on multi-heads attention to model the global compositional coherence. Then, we generate the semantic-focal representations from different semantic regions and design a \textit{Focal Coherence Learning} (FCL) module to learn the focal compositional coherence from different semantic-focal representations. Finally, we optimize the CANN in a novel compositional optimization strategy. Extensive experiments on the large-scale real-world data clearly demonstrate the effectiveness of CANN compared with several state-of-the-art methods.