 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceptive Sequential Decision-Making via Regularized Policy Optimization
Jan 30, 2025



Autonomous systems are increasingly expected to operate in the presence of adversaries, though an adversary may infer sensitive information simply by observing a system, without even needing to interact with it. Therefore, in this work we present a deceptive decision-making framework that not only conceals sensitive information, but in fact actively misleads adversaries about it. We model autonomous systems as Markov decision processes, and we consider adversaries that attempt to infer their reward functions using inverse reinforcement learning. To counter such efforts, we present two regularization strategies for policy synthesis problems that actively deceive an adversary about a system's underlying rewards. The first form of deception is ``diversionary'', and it leads an adversary to draw any false conclusion about what the system's reward function is. The second form of deception is ``targeted'', and it leads an adversary to draw a specific false conclusion about what the system's reward function is. We then show how each form of deception can be implemented in policy optimization problems, and we analytically bound the loss in total accumulated reward that is induced by deception. Next, we evaluate these developments in a multi-agent sequential decision-making problem with one real agent and multiple decoys. We show that diversionary deception can cause the adversary to believe that the most important agent is the least important, while attaining a total accumulated reward that is $98.83\%$ of its optimal, non-deceptive value. Similarly, we show that targeted deception can make any decoy appear to be the most important agent, while still attaining a total accumulated reward that is $99.25\%$ of its optimal, non-deceptive value.
Modeling and Predicting Epidemic Spread: A Gaussian Process Regression Approach
Dec 14, 2023



Modeling and prediction of epidemic spread are critical to assist in policy-making for mitigation. Therefore, we present a new method based on Gaussian Process Regression to model and predict epidemics, and it quantifies prediction confidence through variance and high probability error bounds. Gaussian Process Regression excels in using small datasets and providing uncertainty bounds, and both of these properties are critical in modeling and predicting epidemic spreading processes with limited data. However, the derivation of formal uncertainty bounds remains lacking when using Gaussian Process Regression in the setting of epidemics, which limits its usefulness in guiding mitigation efforts. Therefore, in this work, we develop a novel bound on the variance of the prediction that quantifies the impact of the epidemic data on the predictions we make. Further, we develop a high probability error bound on the prediction, and we quantify how the epidemic spread, the infection data, and the length of the prediction horizon all affect this error bound. We also show that the error stays below a certain threshold based on the length of the prediction horizon. To illustrate this framework, we leverage Gaussian Process Regression to model and predict COVID-19 using real-world infection data from the United Kingdom.
DOMINO++: Domain-aware Loss Regularization for Deep Learning Generalizability
Aug 21, 2023



Out-of-distribution (OOD) generalization poses a serious challenge for modern deep learning (DL). OOD data consists of test data that is significantly different from the model's training data. DL models that perform well on in-domain test data could struggle on OOD data. Overcoming this discrepancy is essential to the reliable deployment of DL. Proper model calibration decreases the number of spurious connections that are made between model features and class outputs. Hence, calibrated DL can improve OOD generalization by only learning features that are truly indicative of the respective classes. Previous work proposed domain-aware model calibration (DOMINO) to improve DL calibration, but it lacks designs for model generalizability to OOD data. In this work, we propose DOMINO++, a dual-guidance and dynamic domain-aware loss regularization focused on OOD generalizability. DOMINO++ integrates expert-guided and data-guided knowledge in its regularization. Unlike DOMINO which imposed a fixed scaling and regularization rate, DOMINO++ designs a dynamic scaling factor and an adaptive regularization rate. Comprehensive evaluations compare DOMINO++ with DOMINO and the baseline model for head tissue segmentation from magnetic resonance images (MRIs) on OOD data. The OOD data consists of synthetic noisy and rotated datasets, as well as real data using a different MRI scanner from a separate site. DOMINO++'s superior performance demonstrates its potential to improve the trustworthy deployment of DL on real clinical data.
DOMINO: Domain-aware Loss for Deep Learning Calibration
Feb 10, 2023

Deep learning has achieved the state-of-the-art performance across medical imaging tasks; however, model calibration is often not considered. Uncalibrated models are potentially dangerous in high-risk applications since the user does not know when they will fail. Therefore, this paper proposes a novel domain-aware loss function to calibrate deep learning models. The proposed loss function applies a class-wise penalty based on the similarity between classes within a given target domain. Thus, the approach improves the calibration while also ensuring that the model makes less risky errors even when incorrect. The code for this software is available at https://github.com/lab-smile/DOMINO.
Differential Privacy in Cooperative Multiagent Planning
Jan 20, 2023



Privacy-aware multiagent systems must protect agents' sensitive data while simultaneously ensuring that agents accomplish their shared objectives. Towards this goal, we propose a framework to privatize inter-agent communications in cooperative multiagent decision-making problems. We study sequential decision-making problems formulated as cooperative Markov games with reach-avoid objectives. We apply a differential privacy mechanism to privatize agents' communicated symbolic state trajectories, and then we analyze tradeoffs between the strength of privacy and the team's performance. For a given level of privacy, this tradeoff is shown to depend critically upon the total correlation among agents' state-action processes. We synthesize policies that are robust to privacy by reducing the value of the total correlation. Numerical experiments demonstrate that the team's performance under these policies decreases by only 3 percent when comparing private versus non-private implementations of communication. By contrast, the team's performance decreases by roughly 86 percent when using baseline policies that ignore total correlation and only optimize team performance.
DOMINO: Domain-aware Model Calibration in Medical Image Segmentation
Sep 13, 2022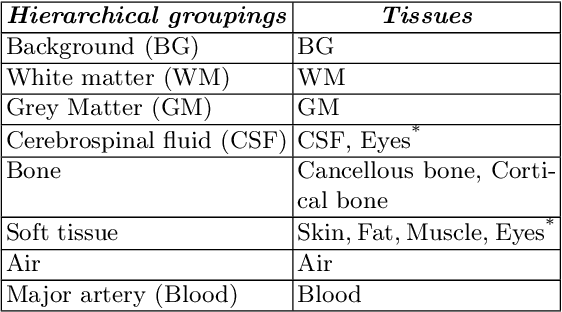
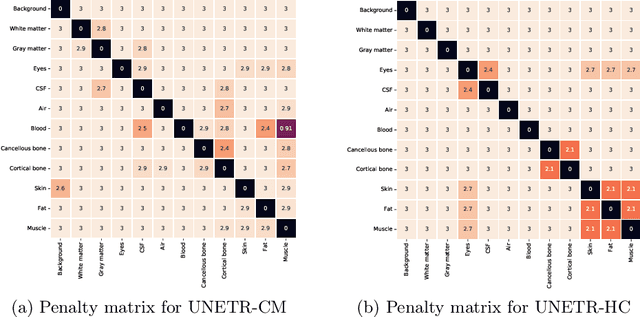
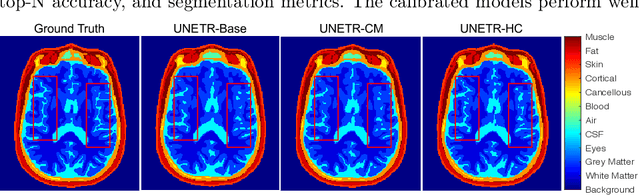
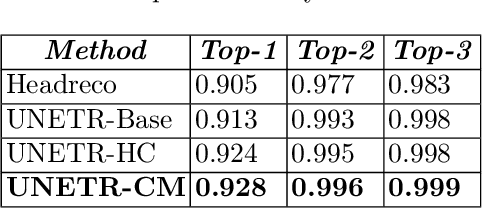
Model calibration measures the agreement between the predicted probability estimates and the true correctness likelihood. Proper model calibration is vital for high-risk applications. Unfortunately, modern deep neural networks are poorly calibrated, compromising trustworthiness and reliability. Medical image segmentation particularly suffers from this due to the natural uncertainty of tissue boundaries. This is exasperated by their loss functions, which favor overconfidence in the majority classes. We address these challenges with DOMINO, a domain-aware model calibration method that leverages the semantic confusability and hierarchical similarity between class labels. Our experiments demonstrate that our DOMINO-calibrated deep neural networks outperform non-calibrated models and state-of-the-art morphometric methods in head image segmentation. Our results show that our method can consistently achieve better calibration, higher accuracy, and faster inference times than these methods, especially on rarer classes. This performance is attributed to our domain-aware regularization to inform semantic model calibration. These findings show the importance of semantic ties between class labels in building confidence in deep learning models. The framework has the potential to improve the trustworthiness and reliability of generic medical image segmentation models. The code for this article is available at: https://github.com/lab-smile/DOMINO.
Privacy-Preserving Teacher-Student Deep Reinforcement Learning
Feb 18, 2021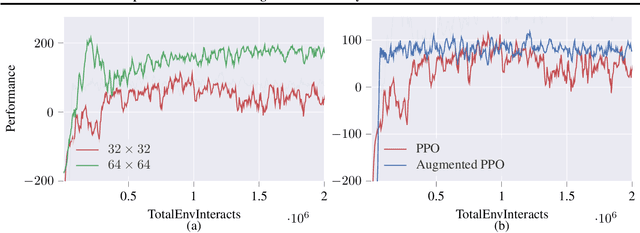
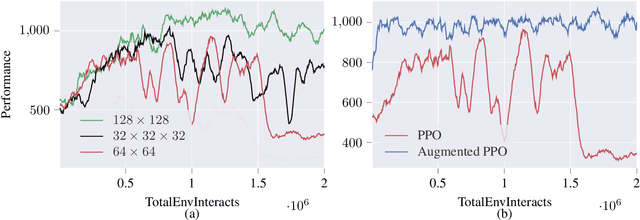
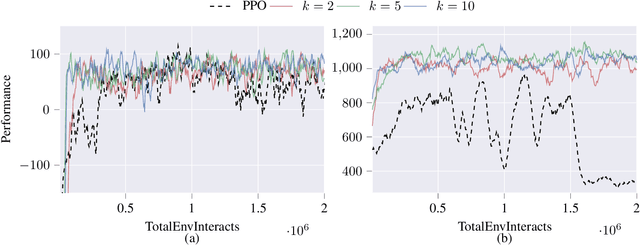
Deep reinforcement learning agents may learn complex tasks more efficiently when they coordinate with one another. We consider a teacher-student coordination scheme wherein an agent may ask another agent for demonstrations. Despite the benefits of sharing demonstrations, however, potential adversaries may obtain sensitive information belonging to the teacher by observing the demonstrations. In particular, deep reinforcement learning algorithms are known to be vulnerable to membership attacks, which make accurate inferences about the membership of the entries of training datasets. Therefore, there is a need to safeguard the teacher against such privacy threats. We fix the teacher's policy as the context of the demonstrations, which allows for different internal models across the student and the teacher, and contrasts the existing methods. We make the following two contributions. (i) We develop a differentially private mechanism that protects the privacy of the teacher's training dataset. (ii) We propose a proximal policy-optimization objective that enables the student to benefit from the demonstrations despite the perturbations of the privacy mechanism. We empirically show that the algorithm improves the student's learning upon convergence rate and utility. Specifically, compared with an agent who learns the same task on its own, we observe that the student's policy converges faster, and the converging policy accumulates higher rewards more robustly.