 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
NAT: Neural Acoustic Transfer for Interactive Scenes in Real Time
Jun 06, 2025



Previous acoustic transfer methods rely on extensive precomputation and storage of data to enable real-time interaction and auditory feedback. However, these methods struggle with complex scenes, especially when dynamic changes in object position, material, and size significantly alter sound effects. These continuous variations lead to fluctuating acoustic transfer distributions, making it challenging to represent with basic data structures and render efficiently in real time. To address this challenge, we present Neural Acoustic Transfer, a novel approach that utilizes an implicit neural representation to encode precomputed acoustic transfer and its variations, allowing for real-time prediction of sound fields under varying conditions. To efficiently generate the training data required for the neural acoustic field, we developed a fast Monte-Carlo-based boundary element method (BEM) approximation for general scenarios with smooth Neumann conditions. Additionally, we implemented a GPU-accelerated version of standard BEM for scenarios requiring higher precision. These methods provide the necessary training data, enabling our neural network to accurately model the sound radiation space. We demonstrate our method's numerical accuracy and runtime efficiency (within several milliseconds for 30s audio) through comprehensive validation and comparisons in diverse acoustic transfer scenarios. Our approach allows for efficient and accurate modeling of sound behavior in dynamically changing environments, which can benefit a wide range of interactive applications such as virtual reality, augmented reality, and advanced audio production.
Real-Time Ground-Plane Refined LiDAR SLAM
Oct 21, 2021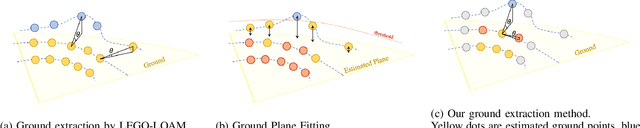

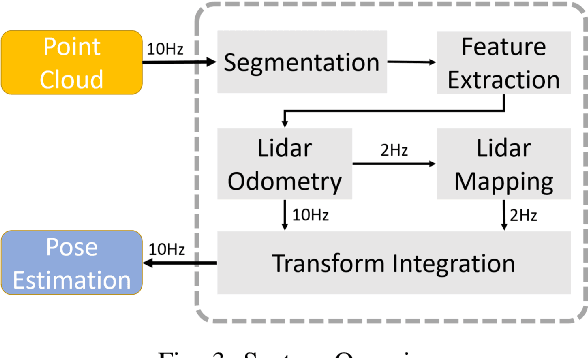
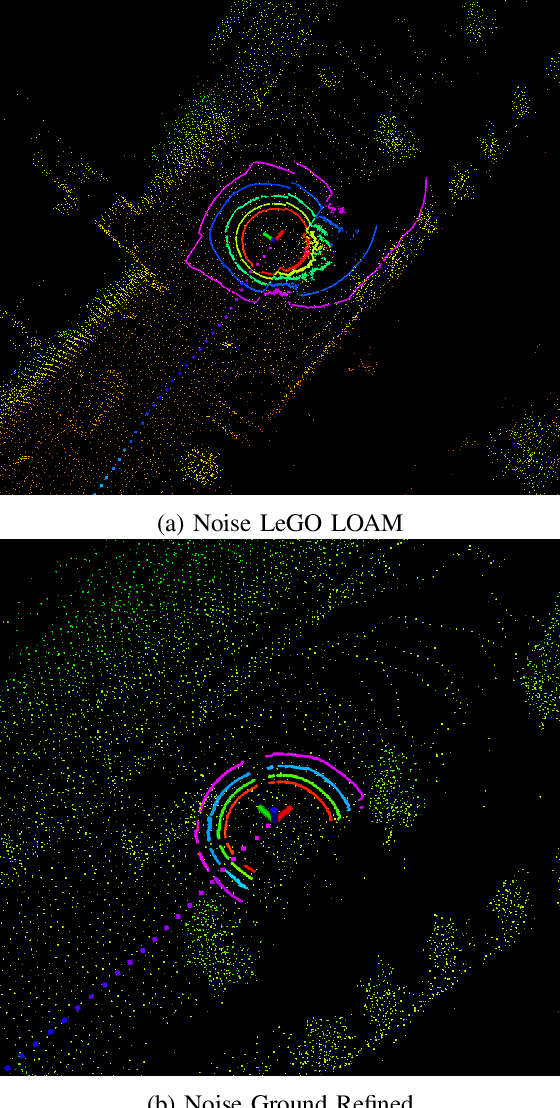
SLAM system using only point cloud has been proven successful in recent years. In most of these systems, they extract features for tracking after ground removal, which causes large variance on the z-axis. Ground actually provides robust information to obtain [t_z, \theta_{roll}, \theta_{pitch}]$. In this project, we followed the LeGO-LOAM, a light-weighted real-time SLAM system that extracts and registers ground as an addition to the original LOAM, and we proposed a new clustering-based method to refine the planar extraction algorithm for ground such that the system can handle much more noisy or dynamic environments. We implemented this method and compared it with LeGo-LOAM on our collected data of CMU campus, as well as a collected dataset for ATV (All-Terrain Vehicle) for off-road self-driving. Both visualization and evaluation results show obvious improvement of our algorithm.
Exposure: A White-Box Photo Post-Processing Framework
Feb 06, 2018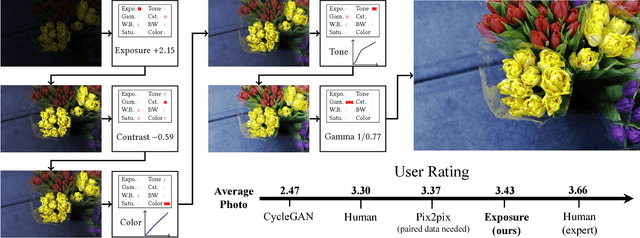


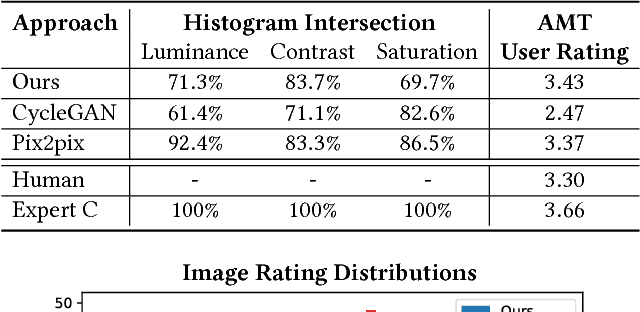
Retouching can significantly elevate the visual appeal of photos, but many casual photographers lack the expertise to do this well. To address this problem, previous works have proposed automatic retouching systems based on supervised learning from paired training images acquired before and after manual editing. As it is difficult for users to acquire paired images that reflect their retouching preferences, we present in this paper a deep learning approach that is instead trained on unpaired data, namely a set of photographs that exhibits a retouching style the user likes, which is much easier to collect. Our system is formulated using deep convolutional neural networks that learn to apply different retouching operations on an input image. Network training with respect to various types of edits is enabled by modeling these retouching operations in a unified manner as resolution-independent differentiable filters. To apply the filters in a proper sequence and with suitable parameters, we employ a deep reinforcement learning approach that learns to make decisions on what action to take next, given the current state of the image. In contrast to many deep learning systems, ours provides users with an understandable solution in the form of conventional retouching edits, rather than just a "black-box" result. Through quantitative comparisons and user studies, we show that this technique generates retouching results consistent with the provided photo set.