 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edget-DGR: A Trajectory-Based Deep Generative Replay Method for Continual Learning in Decision Making
Jan 04, 2024



Deep generative replay has emerged as a promising approach for continual learning in decision-making tasks. This approach addresses the problem of catastrophic forgetting by leveraging the generation of trajectories from previously encountered tasks to augment the current dataset. However, existing deep generative replay methods for continual learning rely on autoregressive models, which suffer from compounding errors in the generated trajectories. In this paper, we propose a simple, scalable, and non-autoregressive method for continual learning in decision-making tasks using a generative model that generates task samples conditioned on the trajectory timestep. We evaluate our method on Continual World benchmarks and find that our approach achieves state-of-the-art performance on the average success rate metric among continual learning methods. Code is available at https://github.com/WilliamYue37/t-DGR .
Query-Based Knowledge Sharing for Open-Vocabulary Multi-Label Classification
Jan 02, 2024Identifying labels that did not appear during training, known as multi-label zero-shot learning, is a non-trivial task in computer vision. To this end, recent studies have attempted to explore the multi-modal knowledge of vision-language pre-training (VLP) models by knowledge distillation, allowing to recognize unseen labels in an open-vocabulary manner. However, experimental evidence shows that knowledge distillation is suboptimal and provides limited performance gain in unseen label prediction. In this paper, a novel query-based knowledge sharing paradigm is proposed to explore the multi-modal knowledge from the pretrained VLP model for open-vocabulary multi-label classification. Specifically, a set of learnable label-agnostic query tokens is trained to extract critical vision knowledge from the input image, and further shared across all labels, allowing them to select tokens of interest as visual clues for recognition. Besides, we propose an effective prompt pool for robust label embedding, and reformulate the standard ranking learning into a form of classification to allow the magnitude of feature vectors for matching, which both significantly benefit label recognition. Experimental results show that our framework significantly outperforms state-of-the-art methods on zero-shot task by 5.9% and 4.5% in mAP on the NUS-WIDE and Open Images, respectively.
Cross-Layer Optimization for Fault-Tolerant Deep Learning
Dec 21, 2023Fault-tolerant deep learning accelerator is the basis for highly reliable deep learning processing and critical to deploy deep learning in safety-critical applications such as avionics and robotics. Since deep learning is known to be computing- and memory-intensive, traditional fault-tolerant approaches based on redundant computing will incur substantial overhead including power consumption and chip area. To this end, we propose to characterize deep learning vulnerability difference across both neurons and bits of each neuron, and leverage the vulnerability difference to enable selective protection of the deep learning processing components from the perspective of architecture layer and circuit layer respectively. At the same time, we observe the correlation between model quantization and bit protection overhead of the underlying processing elements of deep learning accelerators, and propose to reduce the bit protection overhead by adding additional quantization constrain without compromising the model accuracy. Finally, we employ Bayesian optimization strategy to co-optimize the correlated cross-layer design parameters at algorithm layer, architecture layer, and circuit layer to minimize the hardware resource consumption while fulfilling multiple user constraints including reliability, accuracy, and performance of the deep learning processing at the same time.
Integration and Performance Analysis of Artificial Intelligence and Computer Vision Based on Deep Learning Algorithms
Dec 20, 2023



This paper focuses on the analysis of the application effectiveness of the integration of deep learning and computer vision technologies. Deep learning achieves a historic breakthrough by constructing hierarchical neural networks, enabling end-to-end feature learning and semantic understanding of images. The successful experiences in the field of computer vision provide strong support for training deep learning algorithms. The tight integration of these two fields has given rise to a new generation of advanced computer vision systems, significantly surpassing traditional methods in tasks such as machine vision image classification and object detection. In this paper, typical image classification cases are combined to analyze the superior performance of deep neural network models while also pointing out their limitations in generalization and interpretability, proposing directions for future improvements. Overall, the efficient integration and development trend of deep learning with massive visual data will continue to drive technological breakthroughs and application expansion in the field of computer vision, making it possible to build truly intelligent machine vision systems. This deepening fusion paradigm will powerfully promote unprecedented tasks and functions in computer vision, providing stronger development momentum for related disciplines and industries.
From Past to Future: Rethinking Eligibility Traces
Dec 20, 2023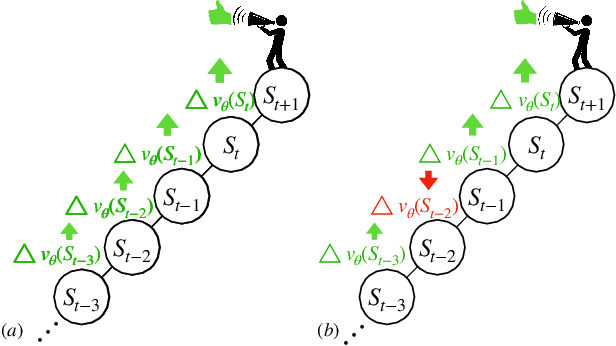
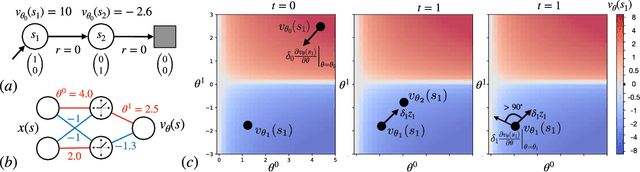
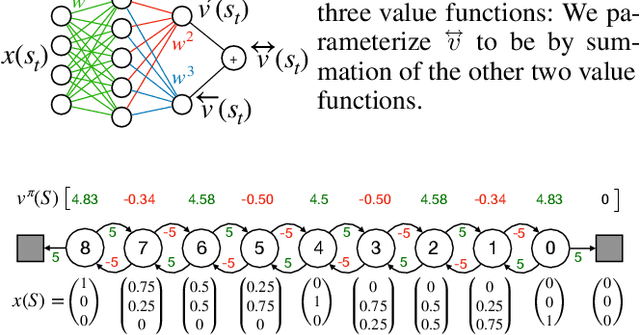
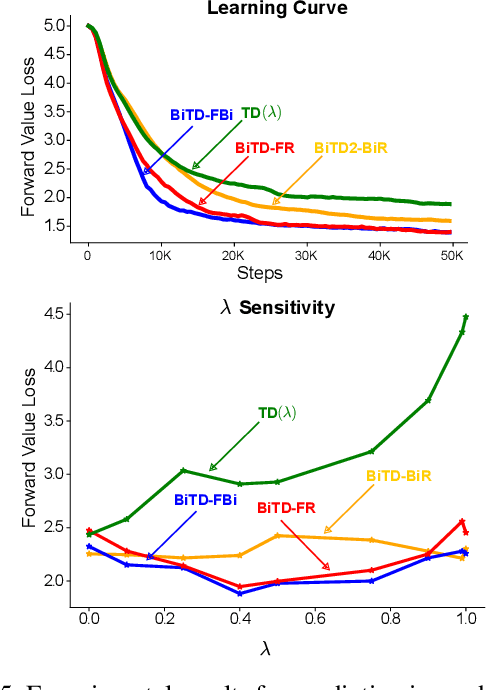
In this paper, we introduce a fresh perspective on the challenges of credit assignment and policy evaluation. First, we delve into the nuances of eligibility traces and explore instances where their updates may result in unexpected credit assignment to preceding states. From this investigation emerges the concept of a novel value function, which we refer to as the \emph{bidirectional value function}. Unlike traditional state value functions, bidirectional value functions account for both future expected returns (rewards anticipated from the current state onward) and past expected returns (cumulative rewards from the episode's start to the present). We derive principled update equations to learn this value function and, through experimentation, demonstrate its efficacy in enhancing the process of policy evaluation. In particular, our results indicate that the proposed learning approach can, in certain challenging contexts, perform policy evaluation more rapidly than TD($\lambda$) -- a method that learns forward value functions, $v^\pi$, \emph{directly}. Overall, our findings present a new perspective on eligibility traces and potential advantages associated with the novel value function it inspires, especially for policy evaluation.
Text as Image: Learning Transferable Adapter for Multi-Label Classification
Dec 07, 2023



Pre-trained vision-language models have notably accelerated progress of open-world concept recognition. Their impressive zero-shot ability has recently been transferred to multi-label image classification via prompt tuning, enabling to discover novel labels in an open-vocabulary manner. However, this paradigm suffers from non-trivial training costs, and becomes computationally prohibitive for a large number of candidate labels. To address this issue, we note that vision-language pre-training aligns images and texts in a unified embedding space, making it potential for an adapter network to identify labels in visual modality while be trained in text modality. To enhance such cross-modal transfer ability, a simple yet effective method termed random perturbation is proposed, which enables the adapter to search for potential visual embeddings by perturbing text embeddings with noise during training, resulting in better performance in visual modality. Furthermore, we introduce an effective approach to employ large language models for multi-label instruction-following text generation. In this way, a fully automated pipeline for visual label recognition is developed without relying on any manual data. Extensive experiments on public benchmarks show the superiority of our method in various multi-label classification tasks.
UGG: Unified Generative Grasping
Nov 28, 2023Dexterous grasping aims to produce diverse grasping postures with a high grasping success rate. Regression-based methods that directly predict grasping parameters given the object may achieve a high success rate but often lack diversity. Generation-based methods that generate grasping postures conditioned on the object can often produce diverse grasping, but they are insufficient for high grasping success due to lack of discriminative information. To mitigate, we introduce a unified diffusion-based dexterous grasp generation model, dubbed the name UGG, which operates within the object point cloud and hand parameter spaces. Our all-transformer architecture unifies the information from the object, the hand, and the contacts, introducing a novel representation of contact points for improved contact modeling. The flexibility and quality of our model enable the integration of a lightweight discriminator, benefiting from simulated discriminative data, which pushes for a high success rate while preserving high diversity. Beyond grasp generation, our model can also generate objects based on hand information, offering valuable insights into object design and studying how the generative model perceives objects. Our model achieves state-of-the-art dexterous grasping on the large-scale DexGraspNet dataset while facilitating human-centric object design, marking a significant advancement in dexterous grasping research. Our project page is https://jiaxin-lu.github.io/ugg/ .
Beyond Visual Cues: Synchronously Exploring Target-Centric Semantics for Vision-Language Tracking
Nov 28, 2023



Single object tracking aims to locate one specific target in video sequences, given its initial state. Classical trackers rely solely on visual cues, restricting their ability to handle challenges such as appearance variations, ambiguity, and distractions. Hence, Vision-Language (VL) tracking has emerged as a promising approach, incorporating language descriptions to directly provide high-level semantics and enhance tracking performance. However, current VL trackers have not fully exploited the power of VL learning, as they suffer from limitations such as heavily relying on off-the-shelf backbones for feature extraction, ineffective VL fusion designs, and the absence of VL-related loss functions. Consequently, we present a novel tracker that progressively explores target-centric semantics for VL tracking. Specifically, we propose the first Synchronous Learning Backbone (SLB) for VL tracking, which consists of two novel modules: the Target Enhance Module (TEM) and the Semantic Aware Module (SAM). These modules enable the tracker to perceive target-related semantics and comprehend the context of both visual and textual modalities at the same pace, facilitating VL feature extraction and fusion at different semantic levels. Moreover, we devise the dense matching loss to further strengthen multi-modal representation learning. Extensive experiments on VL tracking datasets demonstrate the superiority and effectiveness of our methods.
HiH: A Multi-modal Hierarchy in Hierarchy Network for Unconstrained Gait Recognition
Nov 19, 2023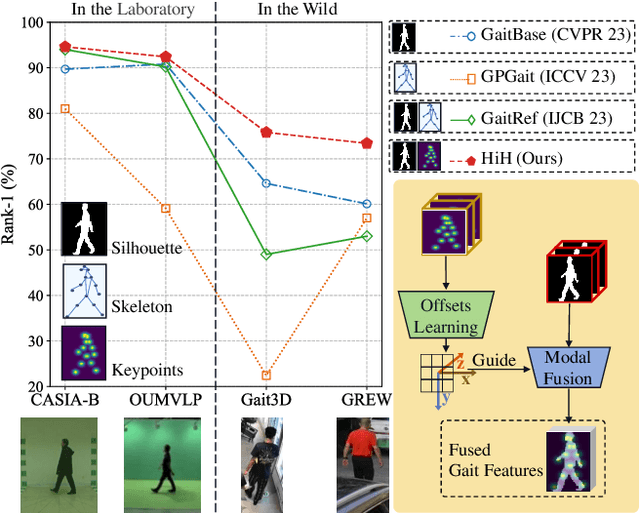
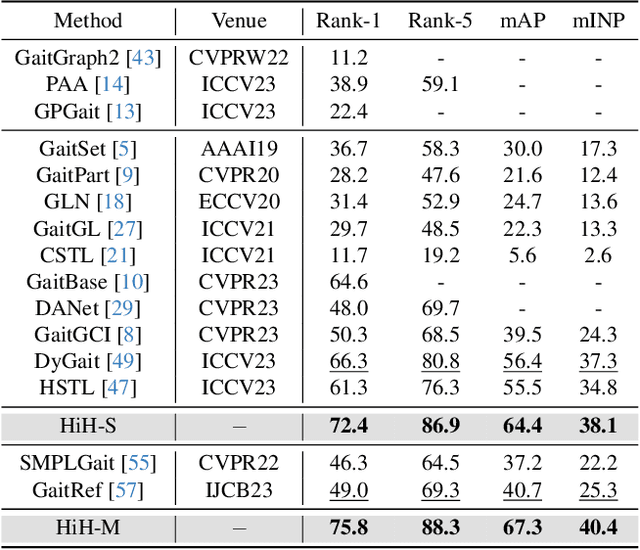
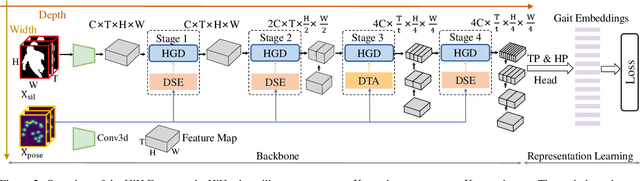
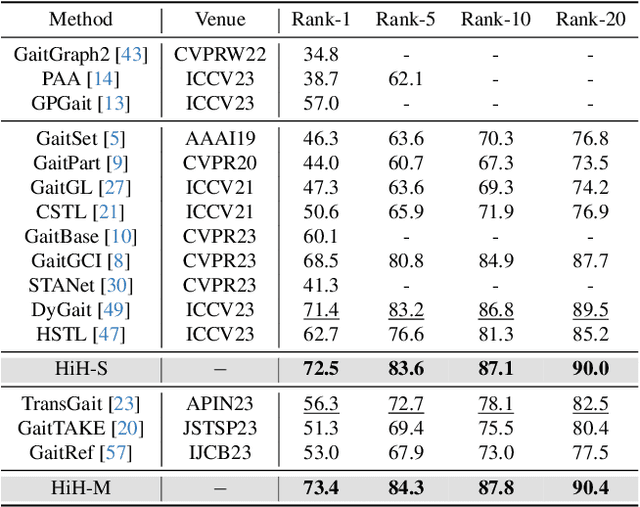
Gait recognition has achieved promising advances in controlled settings, yet it significantly struggles in unconstrained environments due to challenges such as view changes, occlusions, and varying walking speeds. Additionally, efforts to fuse multiple modalities often face limited improvements because of cross-modality incompatibility, particularly in outdoor scenarios. To address these issues, we present a multi-modal Hierarchy in Hierarchy network (HiH) that integrates silhouette and pose sequences for robust gait recognition. HiH features a main branch that utilizes Hierarchical Gait Decomposer (HGD) modules for depth-wise and intra-module hierarchical examination of general gait patterns from silhouette data. This approach captures motion hierarchies from overall body dynamics to detailed limb movements, facilitating the representation of gait attributes across multiple spatial resolutions. Complementing this, an auxiliary branch, based on 2D joint sequences, enriches the spatial and temporal aspects of gait analysis. It employs a Deformable Spatial Enhancement (DSE) module for pose-guided spatial attention and a Deformable Temporal Alignment (DTA) module for aligning motion dynamics through learned temporal offsets. Extensive evaluations across diverse indoor and outdoor datasets demonstrate HiH's state-of-the-art performance, affirming a well-balanced trade-off between accuracy and efficiency.
FD-MIA: Efficient Attacks on Fairness-enhanced Models
Nov 07, 2023



Previous studies have developed fairness methods for biased models that exhibit discriminatory behaviors towards specific subgroups. While these models have shown promise in achieving fair predictions, recent research has identified their potential vulnerability to score-based membership inference attacks (MIAs). In these attacks, adversaries can infer whether a particular data sample was used during training by analyzing the model's prediction scores. However, our investigations reveal that these score-based MIAs are ineffective when targeting fairness-enhanced models in binary classifications. The attack models trained to launch the MIAs degrade into simplistic threshold models, resulting in lower attack performance. Meanwhile, we observe that fairness methods often lead to prediction performance degradation for the majority subgroups of the training data. This raises the barrier to successful attacks and widens the prediction gaps between member and non-member data. Building upon these insights, we propose an efficient MIA method against fairness-enhanced models based on fairness discrepancy results (FD-MIA). It leverages the difference in the predictions from both the original and fairness-enhanced models and exploits the observed prediction gaps as attack clues. We also explore potential strategies for mitigating privacy leakages. Extensive experiments validate our findings and demonstrate the efficacy of the proposed method.