 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-view Spatio-Temporal Feature Fusion with CNN-Transformer Hybrid Network for Chinese Isolated Sign Language Recognition
Jun 08, 2025Due to the emergence of many sign language datasets, isolated sign language recognition (ISLR) has made significant progress in recent years. In addition, the development of various advanced deep neural networks is another reason for this breakthrough. However, challenges remain in applying the technique in the real world. First, existing sign language datasets do not cover the whole sign vocabulary. Second, most of the sign language datasets provide only single view RGB videos, which makes it difficult to handle hand occlusions when performing ISLR. To fill this gap, this paper presents a dual-view sign language dataset for ISLR named NationalCSL-DP, which fully covers the Chinese national sign language vocabulary. The dataset consists of 134140 sign videos recorded by ten signers with respect to two vertical views, namely, the front side and the left side. Furthermore, a CNN transformer network is also proposed as a strong baseline and an extremely simple but effective fusion strategy for prediction. Extensive experiments were conducted to prove the effectiveness of the datasets as well as the baseline. The results show that the proposed fusion strategy can significantly increase the performance of the ISLR, but it is not easy for the sequence-to-sequence model, regardless of whether the early-fusion or late-fusion strategy is applied, to learn the complementary features from the sign videos of two vertical views.
Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
May 13, 2025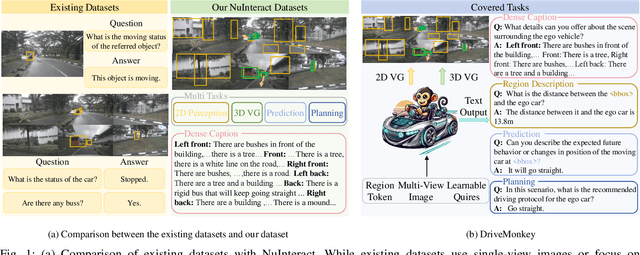

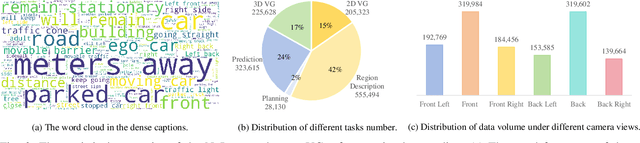
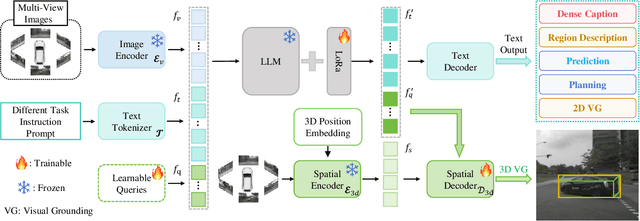
The Large Visual-Language Models (LVLMs) have significantly advanced image understanding. Their comprehension and reasoning capabilities enable promising applications in autonomous driving scenarios. However, existing research typically focuses on front-view perspectives and partial objects within scenes, struggling to achieve comprehensive scene understanding. Meanwhile, existing LVLMs suffer from the lack of mapping relationship between 2D and 3D and insufficient integration of 3D object localization and instruction understanding. To tackle these limitations, we first introduce NuInteract, a large-scale dataset with over 1.5M multi-view image language pairs spanning dense scene captions and diverse interactive tasks. Furthermore, we propose DriveMonkey, a simple yet effective framework that seamlessly integrates LVLMs with a spatial processor using a series of learnable queries. The spatial processor, designed as a plug-and-play component, can be initialized with pre-trained 3D detectors to improve 3D perception. Our experiments show that DriveMonkey outperforms general LVLMs, especially achieving a 9.86% notable improvement on the 3D visual grounding task. The dataset and code will be released at https://github.com/zc-zhao/DriveMonkey.
Robust Misinformation Detection by Visiting Potential Commonsense Conflict
Apr 30, 2025



The development of Internet technology has led to an increased prevalence of misinformation, causing severe negative effects across diverse domains. To mitigate this challenge, Misinformation Detection (MD), aiming to detect online misinformation automatically, emerges as a rapidly growing research topic in the community. In this paper, we propose a novel plug-and-play augmentation method for the MD task, namely Misinformation Detection with Potential Commonsense Conflict (MD-PCC). We take inspiration from the prior studies indicating that fake articles are more likely to involve commonsense conflict. Accordingly, we construct commonsense expressions for articles, serving to express potential commonsense conflicts inferred by the difference between extracted commonsense triplet and golden ones inferred by the well-established commonsense reasoning tool COMET. These expressions are then specified for each article as augmentation. Any specific MD methods can be then trained on those commonsense-augmented articles. Besides, we also collect a novel commonsense-oriented dataset named CoMis, whose all fake articles are caused by commonsense conflict. We integrate MD-PCC with various existing MD backbones and compare them across both 4 public benchmark datasets and CoMis. Empirical results demonstrate that MD-PCC can consistently outperform the existing MD baselines.
NormalCrafter: Learning Temporally Consistent Normals from Video Diffusion Priors
Apr 15, 2025



Surface normal estimation serves as a cornerstone for a spectrum of computer vision applications. While numerous efforts have been devoted to static image scenarios, ensuring temporal coherence in video-based normal estimation remains a formidable challenge. Instead of merely augmenting existing methods with temporal components, we present NormalCrafter to leverage the inherent temporal priors of video diffusion models. To secure high-fidelity normal estimation across sequences, we propose Semantic Feature Regularization (SFR), which aligns diffusion features with semantic cues, encouraging the model to concentrate on the intrinsic semantics of the scene. Moreover, we introduce a two-stage training protocol that leverages both latent and pixel space learning to preserve spatial accuracy while maintaining long temporal context. Extensive evaluations demonstrate the efficacy of our method, showcasing a superior performance in generating temporally consistent normal sequences with intricate details from diverse videos.
Collaboration and Controversy Among Experts: Rumor Early Detection by Tuning a Comment Generator
Apr 05, 2025Over the past decade, social media platforms have been key in spreading rumors, leading to significant negative impacts. To counter this, the community has developed various Rumor Detection (RD) algorithms to automatically identify them using user comments as evidence. However, these RD methods often fail in the early stages of rumor propagation when only limited user comments are available, leading the community to focus on a more challenging topic named Rumor Early Detection (RED). Typically, existing RED methods learn from limited semantics in early comments. However, our preliminary experiment reveals that the RED models always perform best when the number of training and test comments is consistent and extensive. This inspires us to address the RED issue by generating more human-like comments to support this hypothesis. To implement this idea, we tune a comment generator by simulating expert collaboration and controversy and propose a new RED framework named CAMERED. Specifically, we integrate a mixture-of-expert structure into a generative language model and present a novel routing network for expert collaboration. Additionally, we synthesize a knowledgeable dataset and design an adversarial learning strategy to align the style of generated comments with real-world comments. We further integrate generated and original comments with a mutual controversy fusion module. Experimental results show that CAMERED outperforms state-of-the-art RED baseline models and generation methods, demonstrating its effectiveness.
CoGen: 3D Consistent Video Generation via Adaptive Conditioning for Autonomous Driving
Mar 28, 2025Recent progress in driving video generation has shown significant potential for enhancing self-driving systems by providing scalable and controllable training data. Although pretrained state-of-the-art generation models, guided by 2D layout conditions (e.g., HD maps and bounding boxes), can produce photorealistic driving videos, achieving controllable multi-view videos with high 3D consistency remains a major challenge. To tackle this, we introduce a novel spatial adaptive generation framework, CoGen, which leverages advances in 3D generation to improve performance in two key aspects: (i) To ensure 3D consistency, we first generate high-quality, controllable 3D conditions that capture the geometry of driving scenes. By replacing coarse 2D conditions with these fine-grained 3D representations, our approach significantly enhances the spatial consistency of the generated videos. (ii) Additionally, we introduce a consistency adapter module to strengthen the robustness of the model to multi-condition control. The results demonstrate that this method excels in preserving geometric fidelity and visual realism, offering a reliable video generation solution for autonomous driving.
ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
Mar 25, 2025End-to-end (E2E) autonomous driving methods still struggle to make correct decisions in interactive closed-loop evaluation due to limited causal reasoning capability. Current methods attempt to leverage the powerful understanding and reasoning abilities of Vision-Language Models (VLMs) to resolve this dilemma. However, the problem is still open that few VLMs for E2E methods perform well in the closed-loop evaluation due to the gap between the semantic reasoning space and the purely numerical trajectory output in the action space. To tackle this issue, we propose ORION, a holistic E2E autonomous driving framework by vision-language instructed action generation. ORION uniquely combines a QT-Former to aggregate long-term history context, a Large Language Model (LLM) for driving scenario reasoning, and a generative planner for precision trajectory prediction. ORION further aligns the reasoning space and the action space to implement a unified E2E optimization for both visual question-answering (VQA) and planning tasks. Our method achieves an impressive closed-loop performance of 77.74 Driving Score (DS) and 54.62% Success Rate (SR) on the challenge Bench2Drive datasets, which outperforms state-of-the-art (SOTA) methods by a large margin of 14.28 DS and 19.61% SR.
MiLA: Multi-view Intensive-fidelity Long-term Video Generation World Model for Autonomous Driving
Mar 20, 2025In recent years, data-driven techniques have greatly advanced autonomous driving systems, but the need for rare and diverse training data remains a challenge, requiring significant investment in equipment and labor. World models, which predict and generate future environmental states, offer a promising solution by synthesizing annotated video data for training. However, existing methods struggle to generate long, consistent videos without accumulating errors, especially in dynamic scenes. To address this, we propose MiLA, a novel framework for generating high-fidelity, long-duration videos up to one minute. MiLA utilizes a Coarse-to-Re(fine) approach to both stabilize video generation and correct distortion of dynamic objects. Additionally, we introduce a Temporal Progressive Denoising Scheduler and Joint Denoising and Correcting Flow modules to improve the quality of generated videos. Extensive experiments on the nuScenes dataset show that MiLA achieves state-of-the-art performance in video generation quality. For more information, visit the project website: https://github.com/xiaomi-mlab/mila.github.io.
Uni-Gaussians: Unifying Camera and Lidar Simulation with Gaussians for Dynamic Driving Scenarios
Mar 11, 2025Ensuring the safety of autonomous vehicles necessitates comprehensive simulation of multi-sensor data, encompassing inputs from both cameras and LiDAR sensors, across various dynamic driving scenarios. Neural rendering techniques, which utilize collected raw sensor data to simulate these dynamic environments, have emerged as a leading methodology. While NeRF-based approaches can uniformly represent scenes for rendering data from both camera and LiDAR, they are hindered by slow rendering speeds due to dense sampling. Conversely, Gaussian Splatting-based methods employ Gaussian primitives for scene representation and achieve rapid rendering through rasterization. However, these rasterization-based techniques struggle to accurately model non-linear optical sensors. This limitation restricts their applicability to sensors beyond pinhole cameras. To address these challenges and enable unified representation of dynamic driving scenarios using Gaussian primitives, this study proposes a novel hybrid approach. Our method utilizes rasterization for rendering image data while employing Gaussian ray-tracing for LiDAR data rendering. Experimental results on public datasets demonstrate that our approach outperforms current state-of-the-art methods. This work presents a unified and efficient solution for realistic simulation of camera and LiDAR data in autonomous driving scenarios using Gaussian primitives, offering significant advancements in both rendering quality and computational efficiency.
Cross-platform Prediction of Depression Treatment Outcome Using Location Sensory Data on Smartphones
Mar 10, 2025Currently, depression treatment relies on closely monitoring patients response to treatment and adjusting the treatment as needed. Using self-reported or physician-administrated questionnaires to monitor treatment response is, however, burdensome, costly and suffers from recall bias. In this paper, we explore using location sensory data collected passively on smartphones to predict treatment outcome. To address heterogeneous data collection on Android and iOS phones, the two predominant smartphone platforms, we explore using domain adaptation techniques to map their data to a common feature space, and then use the data jointly to train machine learning models. Our results show that this domain adaptation approach can lead to significantly better prediction than that with no domain adaptation. In addition, our results show that using location features and baseline self-reported questionnaire score can lead to F1 score up to 0.67, comparable to that obtained using periodic self-reported questionnaires, indicating that using location data is a promising direction for predicting depression treatment outcome.