 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025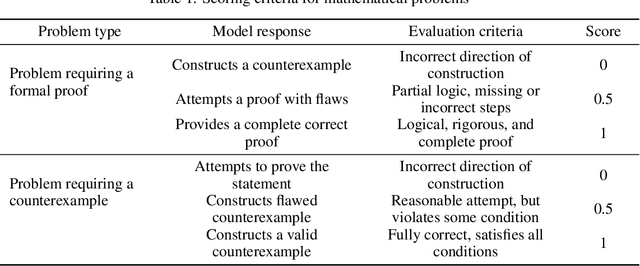
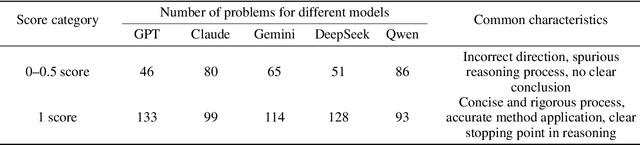
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
LecEval: An Automated Metric for Multimodal Knowledge Acquisition in Multimedia Learning
May 04, 2025Evaluating the quality of slide-based multimedia instruction is challenging. Existing methods like manual assessment, reference-based metrics, and large language model evaluators face limitations in scalability, context capture, or bias. In this paper, we introduce LecEval, an automated metric grounded in Mayer's Cognitive Theory of Multimedia Learning, to evaluate multimodal knowledge acquisition in slide-based learning. LecEval assesses effectiveness using four rubrics: Content Relevance (CR), Expressive Clarity (EC), Logical Structure (LS), and Audience Engagement (AE). We curate a large-scale dataset of over 2,000 slides from more than 50 online course videos, annotated with fine-grained human ratings across these rubrics. A model trained on this dataset demonstrates superior accuracy and adaptability compared to existing metrics, bridging the gap between automated and human assessments. We release our dataset and toolkits at https://github.com/JoylimJY/LecEval.
An LMM for Efficient Video Understanding via Reinforced Compression of Video Cubes
Apr 21, 2025



Large Multimodal Models (LMMs) uniformly perceive video frames, creating computational inefficiency for videos with inherently varying temporal information density. This paper present \textbf{Quicksviewer}, an LMM with new perceiving paradigm that partitions a video of nonuniform density into varying cubes using Gumbel Softmax, followed by a unified resampling for each cube to achieve efficient video understanding. This simple and intuitive approach dynamically compress video online based on its temporal density, significantly reducing spatiotemporal redundancy (overall 45$\times$ compression rate), while enabling efficient training with large receptive field. We train the model from a language backbone through three progressive stages, each incorporating lengthy videos on average of 420s/1fps thanks to the perceiving efficiency. With only 0.8M total video-text samples for training, our model outperforms the direct baseline employing a fixed partitioning strategy by a maximum of 8.72 in accuracy, demonstrating the effectiveness in performance. On Video-MME, Quicksviewer achieves SOTA under modest sequence lengths using just up to 5\% of tokens per frame required by baselines. With this paradigm, scaling up the number of input frames reveals a clear power law of the model capabilities. It is also empirically verified that the segments generated by the cubing network can help for analyzing continuous events in videos.
SDHN: Skewness-Driven Hypergraph Networks for Enhanced Localized Multi-Robot Coordination
Apr 09, 2025



Multi-Agent Reinforcement Learning is widely used for multi-robot coordination, where simple graphs typically model pairwise interactions. However, such representations fail to capture higher-order collaborations, limiting effectiveness in complex tasks. While hypergraph-based approaches enhance cooperation, existing methods often generate arbitrary hypergraph structures and lack adaptability to environmental uncertainties. To address these challenges, we propose the Skewness-Driven Hypergraph Network (SDHN), which employs stochastic Bernoulli hyperedges to explicitly model higher-order multi-robot interactions. By introducing a skewness loss, SDHN promotes an efficient structure with Small-Hyperedge Dominant Hypergraph, allowing robots to prioritize localized synchronization while still adhering to the overall information, similar to human coordination. Extensive experiments on Moving Agents in Formation and Robotic Warehouse tasks validate SDHN's effectiveness, demonstrating superior performance over state-of-the-art baselines.
DSU-Net:An Improved U-Net Model Based on DINOv2 and SAM2 with Multi-scale Cross-model Feature Enhancement
Mar 31, 2025



Despite the significant advancements in general image segmentation achieved by large-scale pre-trained foundation models (such as Meta's Segment Any-thing Model (SAM) series and DINOv2), their performance in specialized fields remains limited by two critical issues: the excessive training costs due to large model parameters, and the insufficient ability to represent specific domain characteristics. This paper proposes a multi-scale feature collabora-tion framework guided by DINOv2 for SAM2, with core innovations in three aspects: (1) Establishing a feature collaboration mechanism between DINOv2 and SAM2 backbones, where high-dimensional semantic features extracted by the self-supervised model guide multi-scale feature fusion; (2) Designing lightweight adapter modules and cross-modal, cross-layer feature fusion units to inject cross-domain knowledge while freezing the base model parameters; (3) Constructing a U-shaped network structure based on U-net, which utilizes attention mechanisms to achieve adaptive aggregation decoding of multi-granularity features. This framework surpasses existing state-of-the-art meth-ods in downstream tasks such as camouflage target detection and salient ob-ject detection, without requiring costly training processes. It provides a tech-nical pathway for efficient deployment of visual image segmentation, demon-strating significant application value in a wide range of downstream tasks and specialized fields within image segmentation.Project page: https://github.com/CheneyXuYiMin/SAM2DINO-Seg
Rule-Based Conflict-Free Decision Framework in Swarm Confrontation
Mar 10, 2025Traditional rule-based decision-making methods with interpretable advantage, such as finite state machine, suffer from the jitter or deadlock(JoD) problems in extremely dynamic scenarios. To realize agent swarm confrontation, decision conflicts causing many JoD problems are a key issue to be solved. Here, we propose a novel decision-making framework that integrates probabilistic finite state machine, deep convolutional networks, and reinforcement learning to implement interpretable intelligence into agents. Our framework overcomes state machine instability and JoD problems, ensuring reliable and adaptable decisions in swarm confrontation. The proposed approach demonstrates effective performance via enhanced human-like cooperation and competitive strategies in the rigorous evaluation of real experiments, outperforming other methods.
Extrapolation Merging: Keep Improving With Extrapolation and Merging
Mar 05, 2025Large Language Models (LLMs) require instruction fine-tuning to perform different downstream tasks. However, the instruction fine-tuning phase still demands significant computational resources and labeled data, lacking a paradigm that can improve model performance without additional computational power and data. Model merging aims to enhance performance by combining the parameters of different models, but the lack of a clear optimization direction during the merging process does not always guarantee improved performance. In this paper, we attempt to provide a clear optimization direction for model merging. We first validate the effectiveness of the model extrapolation method during the instruction fine-tuning phase. Then, we propose Extrapolation Merging, a paradigm that can continue improving model performance without requiring extra computational resources or data. Using the extrapolation method, we provide a clear direction for model merging, achieving local optimization search, and consequently enhancing the merged model's performance. We conduct experiments on seven different tasks, and the results show that our method can consistently improve the model's performance after fine-tuning.
Agentic Reward Modeling: Integrating Human Preferences with Verifiable Correctness Signals for Reliable Reward Systems
Feb 26, 2025Reward models (RMs) are crucial for the training and inference-time scaling up of large language models (LLMs). However, existing reward models primarily focus on human preferences, neglecting verifiable correctness signals which have shown strong potential in training LLMs. In this paper, we propose agentic reward modeling, a reward system that combines reward models with verifiable correctness signals from different aspects to provide reliable rewards. We empirically implement a reward agent, named RewardAgent, that combines human preference rewards with two verifiable signals: factuality and instruction following, to provide more reliable rewards. We conduct comprehensive experiments on existing reward model benchmarks and inference time best-of-n searches on real-world downstream tasks. RewardAgent significantly outperforms vanilla reward models, demonstrating its effectiveness. We further construct training preference pairs using RewardAgent and train an LLM with the DPO objective, achieving superior performance on various NLP benchmarks compared to conventional reward models. Our codes are publicly released to facilitate further research (https://github.com/THU-KEG/Agentic-Reward-Modeling).
LongWriter-V: Enabling Ultra-Long and High-Fidelity Generation in Vision-Language Models
Feb 20, 2025Existing Large Vision-Language Models (LVLMs) can process inputs with context lengths up to 128k visual and text tokens, yet they struggle to generate coherent outputs beyond 1,000 words. We find that the primary limitation is the absence of long output examples during supervised fine-tuning (SFT). To tackle this issue, we introduce LongWriter-V-22k, a SFT dataset comprising 22,158 examples, each with multiple input images, an instruction, and corresponding outputs ranging from 0 to 10,000 words. Moreover, to achieve long outputs that maintain high-fidelity to the input images, we employ Direct Preference Optimization (DPO) to the SFT model. Given the high cost of collecting human feedback for lengthy outputs (e.g., 3,000 words), we propose IterDPO, which breaks long outputs into segments and uses iterative corrections to form preference pairs with the original outputs. Additionally, we develop MMLongBench-Write, a benchmark featuring six tasks to evaluate the long-generation capabilities of VLMs. Our 7B parameter model, trained with LongWriter-V-22k and IterDPO, achieves impressive performance on this benchmark, outperforming larger proprietary models like GPT-4o. Code and data: https://github.com/THU-KEG/LongWriter-V
Generating customized prompts for Zero-Shot Rare Event Medical Image Classification using LLM
Jan 27, 2025Rare events, due to their infrequent occurrences, do not have much data, and hence deep learning techniques fail in estimating the distribution for such data. Open-vocabulary models represent an innovative approach to image classification. Unlike traditional models, these models classify images into any set of categories specified with natural language prompts during inference. These prompts usually comprise manually crafted templates (e.g., 'a photo of a {}') that are filled in with the names of each category. This paper introduces a simple yet effective method for generating highly accurate and contextually descriptive prompts containing discriminative characteristics. Rare event detection, especially in medicine, is more challenging due to low inter-class and high intra-class variability. To address these, we propose a novel approach that uses domain-specific expert knowledge on rare events to generate customized and contextually relevant prompts, which are then used by large language models for image classification. Our zero-shot, privacy-preserving method enhances rare event classification without additional training, outperforming state-of-the-art techniques.