 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Ensemble Training by Jointly Learning Label Dependencies and Member Models
Jul 04, 2022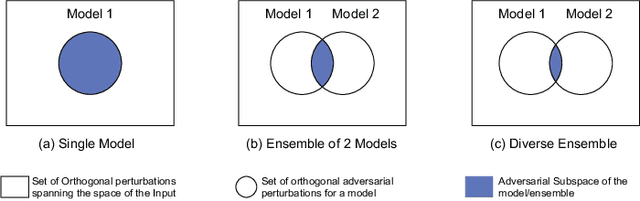
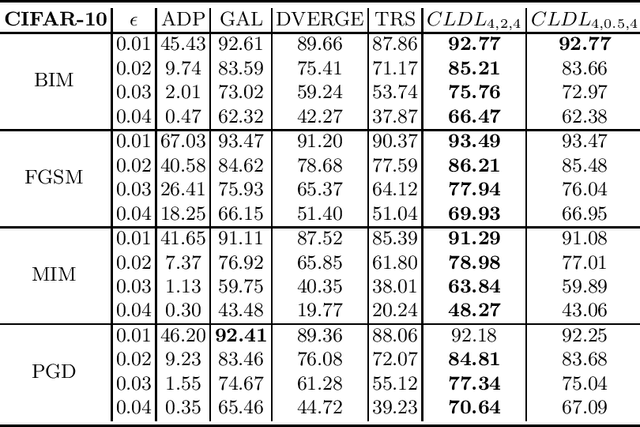
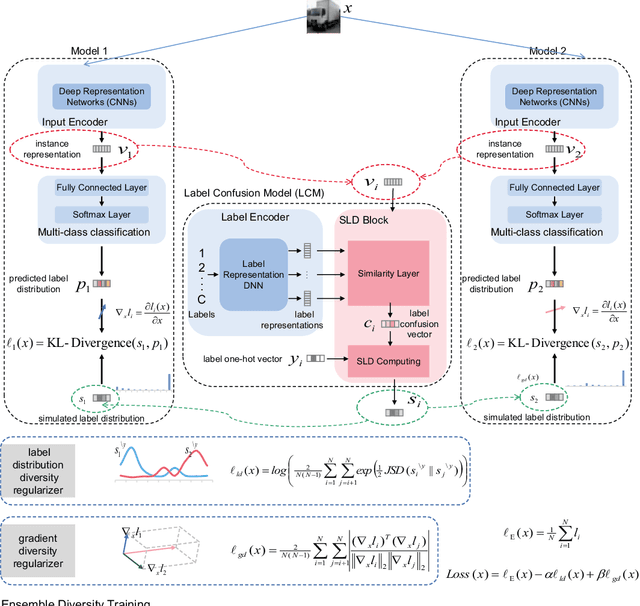
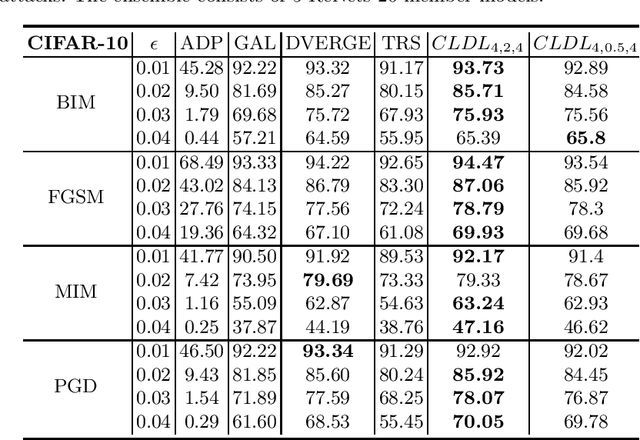
Training an ensemble of different sub-models has empirically proven to be an effective strategy to improve deep neural networks' adversarial robustness. Current ensemble training methods for image recognition usually encode the image labels by one-hot vectors, which neglect dependency relationships between the labels. Here we propose a novel adversarial ensemble training approach to jointly learn the label dependencies and the member models. Our approach adaptively exploits the learned label dependencies to promote the diversity of the member models. We test our approach on widely used datasets MNIST, FasionMNIST, and CIFAR-10. Results show that our approach is more robust against black-box attacks compared with the state-of-the-art methods. Our code is available at https://github.com/ZJLAB-AMMI/LSD.
Walle: An End-to-End, General-Purpose, and Large-Scale Production System for Device-Cloud Collaborative Machine Learning
May 30, 2022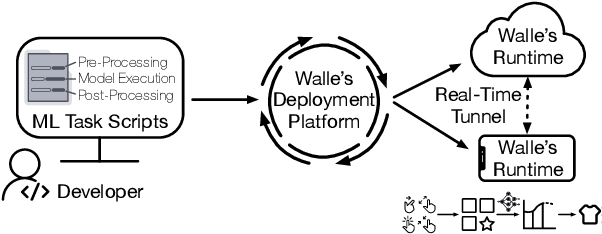
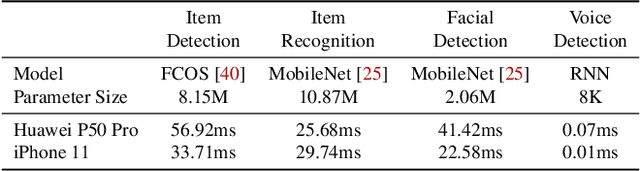
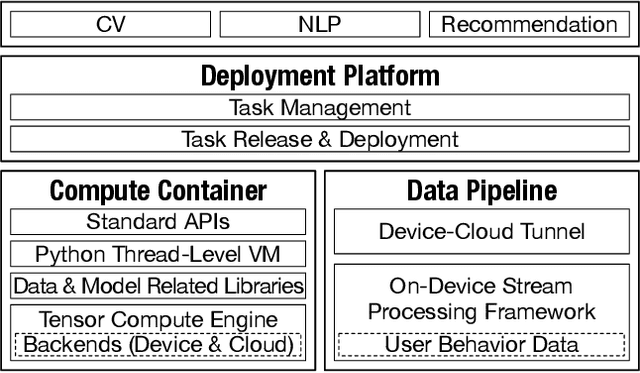

To break the bottlenecks of mainstream cloud-based machine learning (ML) paradigm, we adopt device-cloud collaborative ML and build the first end-to-end and general-purpose system, called Walle, as the foundation. Walle consists of a deployment platform, distributing ML tasks to billion-scale devices in time; a data pipeline, efficiently preparing task input; and a compute container, providing a cross-platform and high-performance execution environment, while facilitating daily task iteration. Specifically, the compute container is based on Mobile Neural Network (MNN), a tensor compute engine along with the data processing and model execution libraries, which are exposed through a refined Python thread-level virtual machine (VM) to support diverse ML tasks and concurrent task execution. The core of MNN is the novel mechanisms of operator decomposition and semi-auto search, sharply reducing the workload in manually optimizing hundreds of operators for tens of hardware backends and further quickly identifying the best backend with runtime optimization for a computation graph. The data pipeline introduces an on-device stream processing framework to enable processing user behavior data at source. The deployment platform releases ML tasks with an efficient push-then-pull method and supports multi-granularity deployment policies. We evaluate Walle in practical e-commerce application scenarios to demonstrate its effectiveness, efficiency, and scalability. Extensive micro-benchmarks also highlight the superior performance of MNN and the Python thread-level VM. Walle has been in large-scale production use in Alibaba, while MNN has been open source with a broad impact in the community.
Emergence of Double-slit Interference by Representing Visual Space in Artificial Neural Networks
May 20, 2022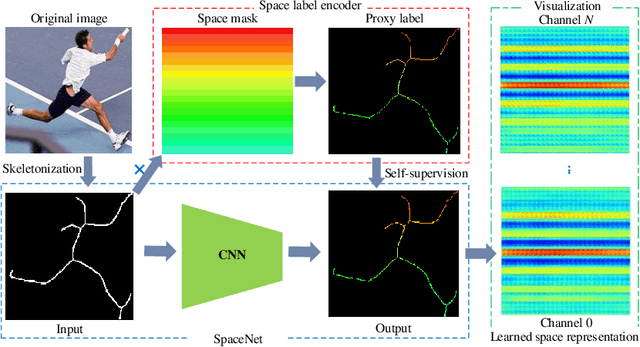
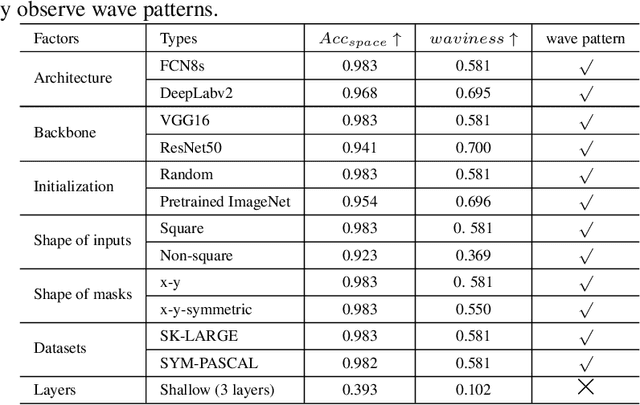
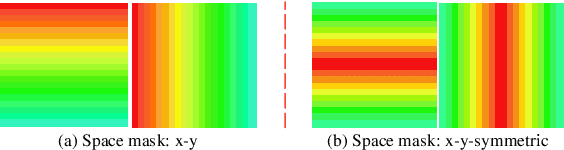
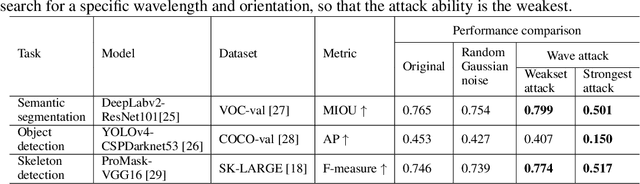
Artificial neural networks have realized incredible successes at image recognition, but the underlying mechanism of visual space representation remains a huge mystery. Grid cells (2014 Nobel Prize) in the entorhinal cortex support a periodic representation as a metric for coding space. Here, we develop a self-supervised convolutional neural network to perform visual space location, leading to the emergence of single-slit diffraction and double-slit interference patterns of waves. Our discoveries reveal the nature of CNN encoding visual space to a certain extent. CNN is no longer a black box in terms of visual spatial encoding, it is interpretable. Our findings indicate that the periodicity property of waves provides a space metric, suggesting a general role of spatial coordinate frame in artificial neural networks.
VQBB: Image-to-image Translation with Vector Quantized Brownian Bridge
May 16, 2022



Image-to-image translation is an important and challenging problem in computer vision. Existing approaches like Pixel2Pixel, DualGAN suffer from the instability of GAN and fail to generate diverse outputs because they model the task as a one-to-one mapping. Although diffusion models can generate images with high quality and diversity, current conditional diffusion models still can not maintain high similarity with the condition image on image-to-image translation tasks due to the Gaussian noise added in the reverse process. To address these issues, a novel Vector Quantized Brownian Bridge(VQBB) diffusion model is proposed in this paper. On one hand, Brownian Bridge diffusion process can model the transformation between two domains more accurate and flexible than the existing Markov diffusion methods. As far as the authors know, it is the first work for Brownian Bridge diffusion process proposed for image-to-image translation. On the other hand, the proposed method improved the learning efficiency and translation accuracy by confining the diffusion process in the quantized latent space. Finally, numerical experimental results validated the performance of the proposed method.
Real-time Online Multi-Object Tracking in Compressed Domain
Apr 05, 2022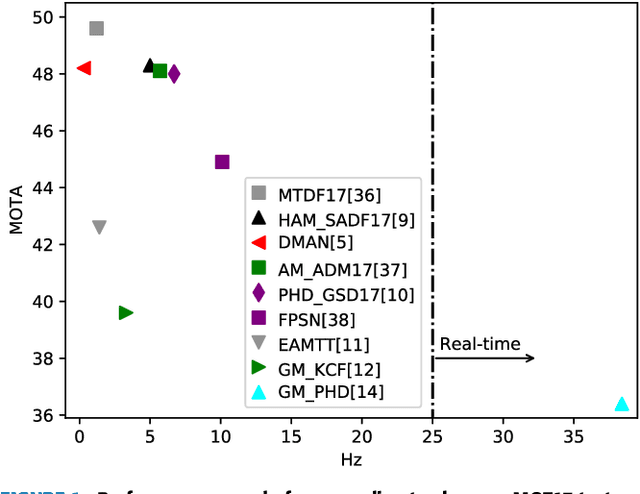

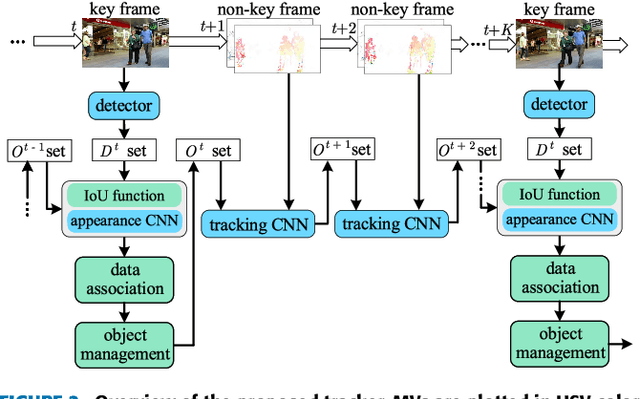
Recent online Multi-Object Tracking (MOT) methods have achieved desirable tracking performance. However, the tracking speed of most existing methods is rather slow. Inspired from the fact that the adjacent frames are highly relevant and redundant, we divide the frames into key and non-key frames respectively and track objects in the compressed domain. For the key frames, the RGB images are restored for detection and data association. To make data association more reliable, an appearance Convolutional Neural Network (CNN) which can be jointly trained with the detector is proposed. For the non-key frames, the objects are directly propagated by a tracking CNN based on the motion information provided in the compressed domain. Compared with the state-of-the-art online MOT methods,our tracker is about 6x faster while maintaining a comparable tracking performance.
Negative Sampling for Recommendation
Apr 02, 2022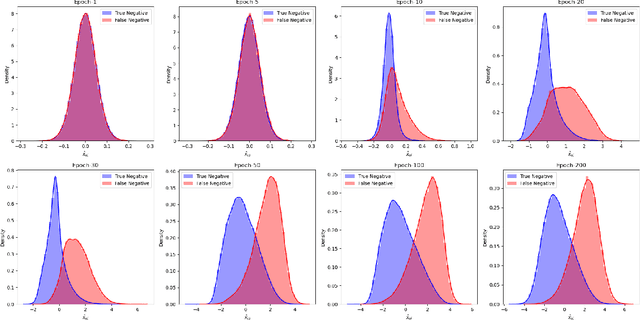
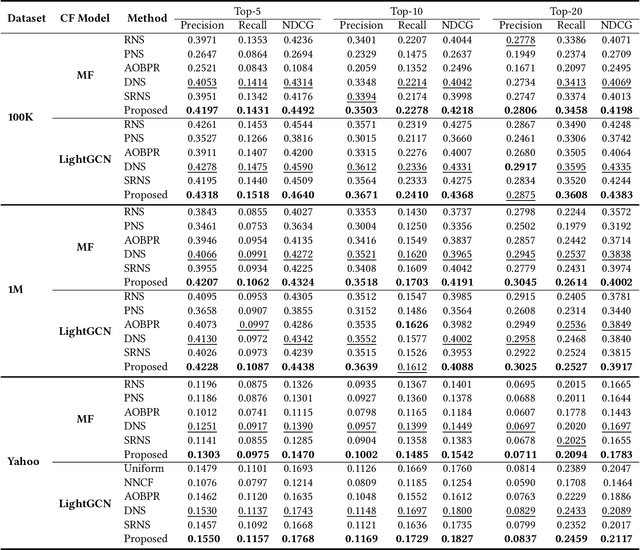
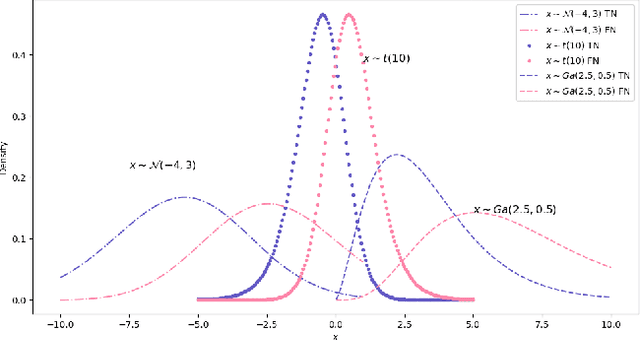
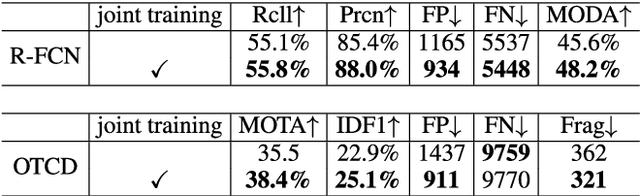
How to effectively sample high-quality negative instances is important for well training a recommendation model. We argue that a high-quality negative should be both \textit{informativeness} and \textit{unbiasedness}. Although previous studies have proposed some approaches to address the informativeness in negative sampling, few has been done to discriminating false negative from true negative for unbiased negative sampling, not to mention taking both into consideration. This paper first adopts a parameter learning perspective to analyze negative informativeness and unbiasedness in loss gradient-based model training. We argue that both negative sampling and collaborative filtering include an implicit task of negative classification, from which we report an insightful yet beneficial finding about the order relation in predicted negatives' scores. Based on our finding and by regarding negatives as random variables, we next derive the class condition density of true negatives and that of false negatives. We also design a Bayesian classifier for negative classification, from which we define a quantitative unbiasedness measure for negatives. Finally, we propose to use a harmonic mean of informativeness and unbiasedness to sample high-quality negatives. Experimental studies validate the superiority of our negative sampling algorithm over the peers in terms of better sampling quality and better recommendation performance.
i-Razor: A Neural Input Razor for Feature Selection and Dimension Search in Large-Scale Recommender Systems
Apr 01, 2022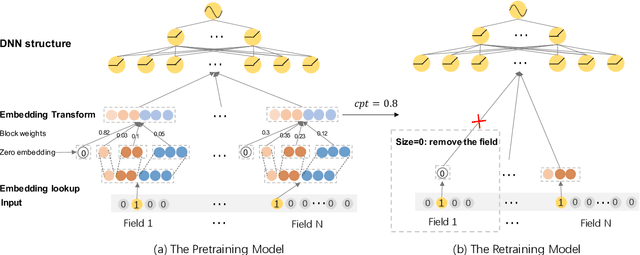


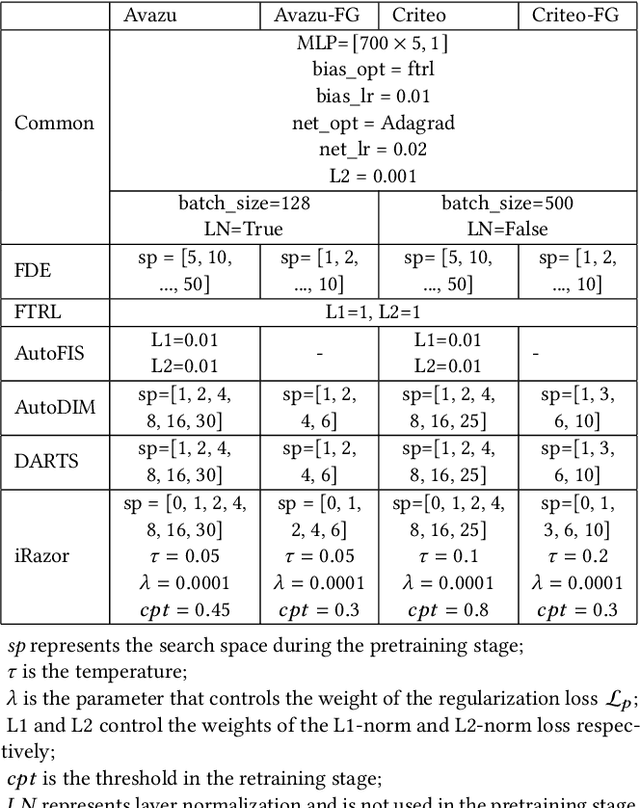
Input features play a crucial role in the predictive performance of DNN-based industrial recommender systems with thousands of categorical and continuous fields from users, items, contexts, and their interactions. Noisy features and inappropriate embedding dimension assignments can impair the performance of recommender systems and introduce unnecessary complexity in model training and online serving. Optimizing the input configuration of DNN models, including feature selection and embedding dimension assignment, has become one of the essential topics in feature engineering. Typically, feature selection and embedding dimension search are optimized sequentially, i.e., feature selection is performed first, followed by embedding dimension search to determine the optimal dimension size for each selected feature. In contrast, this paper studies the joint optimization of feature selection and embedding dimension search. To this end, we propose a differentiable neural \textbf{i}nput \textbf{razor}, namely \textbf{i-Razor}. Specifically, inspired by recent advances in neural architecture search, we introduce an end-to-end differentiable model to learn the relative importance between different embedding regions of each feature. Furthermore, a flexible pruning algorithm is proposed to simultaneously achieve feature filtering and dimension size derivation. Extensive experiments on two large-scale public datasets in the Click-Through-Rate (CTR) prediction task demonstrate the efficacy and superiority of i-Razor in balancing model complexity and performance.
EmotionNAS: Two-stream Architecture Search for Speech Emotion Recognition
Mar 25, 2022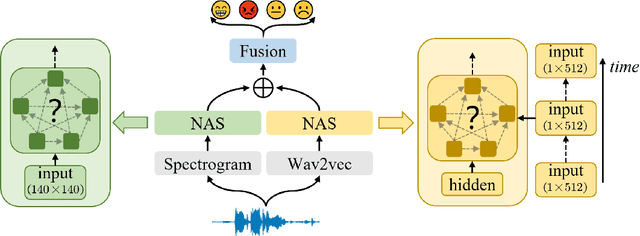
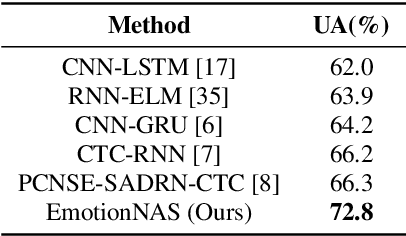
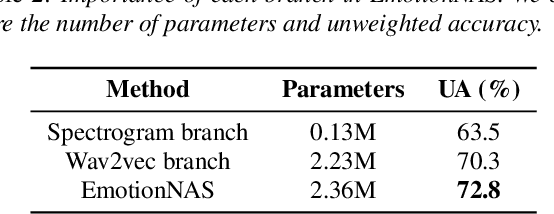
Speech emotion recognition (SER) is a crucial research topic in human-computer interactions. Existing works are mainly based on manually designed models. Despite their great success, these methods heavily rely on historical experience, which are time-consuming but cannot exhaust all possible structures. To address this problem, we propose a neural architecture search (NAS) based framework for SER, called "EmotionNAS". We take spectrogram and wav2vec features as the inputs, followed with NAS to optimize the network structure for these features separately. We further incorporate complementary information in these features through decision-level fusion. Experimental results on IEMOCAP demonstrate that our method succeeds over existing state-of-the-art strategies on SER.
GCNet: Graph Completion Network for Incomplete Multimodal Learning in Conversation
Mar 04, 2022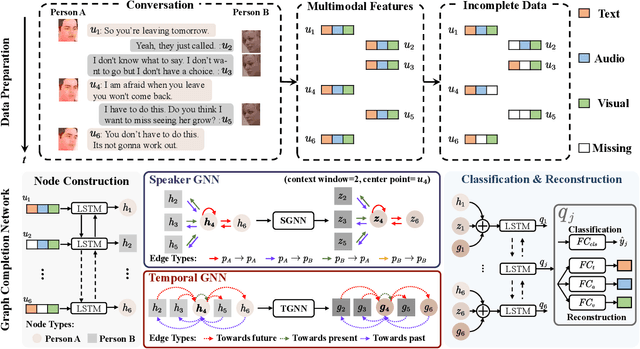

Conversations have become a critical data format on social media platforms. Understanding conversation from emotion, content, and other aspects also attracts increasing attention from researchers due to its widespread application in human-computer interaction. In real-world environments, we often encounter the problem of incomplete modalities, which has become a core issue of conversation understanding. To address this problem, researchers propose various methods. However, existing approaches are mainly designed for individual utterances or medical images rather than conversational data, which cannot exploit temporal and speaker information in conversations. To this end, we propose a novel framework for incomplete multimodal learning in conversations, called "Graph Complete Network (GCNet)", filling the gap of existing works. Our GCNet contains two well-designed graph neural network-based modules, "Speaker GNN" and "Temporal GNN", to capture temporal and speaker information in conversations. To make full use of complete and incomplete data in feature learning, we jointly optimize classification and reconstruction in an end-to-end manner. To verify the effectiveness of our method, we conduct experiments on three benchmark conversational datasets. Experimental results demonstrate that our GCNet is superior to existing state-of-the-art approaches in incomplete multimodal learning.
Approximate Nearest Neighbor Search under Neural Similarity Metric for Large-Scale Recommendation
Feb 28, 2022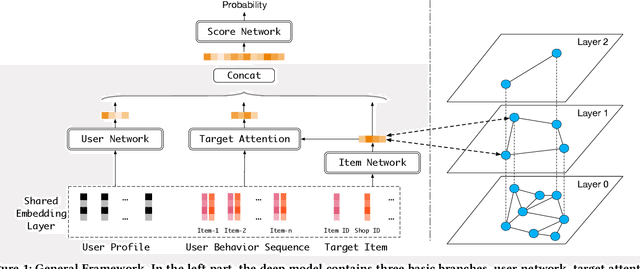

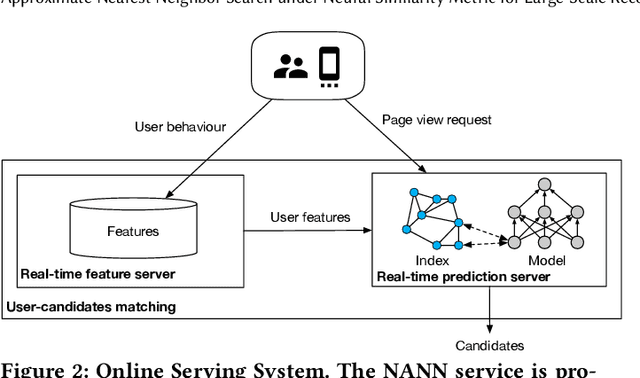
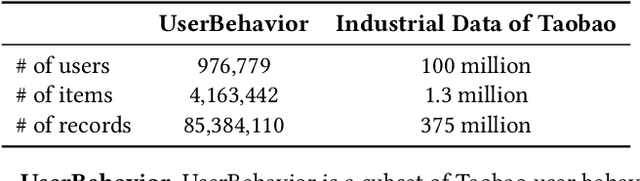
Model-based methods for recommender systems have been studied extensively for years. Modern recommender systems usually resort to 1) representation learning models which define user-item preference as the distance between their embedding representations, and 2) embedding-based Approximate Nearest Neighbor (ANN) search to tackle the efficiency problem introduced by large-scale corpus. While providing efficient retrieval, the embedding-based retrieval pattern also limits the model capacity since the form of user-item preference measure is restricted to the distance between their embedding representations. However, for other more precise user-item preference measures, e.g., preference scores directly derived from a deep neural network, they are computationally intractable because of the lack of an efficient retrieval method, and an exhaustive search for all user-item pairs is impractical. In this paper, we propose a novel method to extend ANN search to arbitrary matching functions, e.g., a deep neural network. Our main idea is to perform a greedy walk with a matching function in a similarity graph constructed from all items. To solve the problem that the similarity measures of graph construction and user-item matching function are heterogeneous, we propose a pluggable adversarial training task to ensure the graph search with arbitrary matching function can achieve fairly high precision. Experimental results in both open source and industry datasets demonstrate the effectiveness of our method. The proposed method has been fully deployed in the Taobao display advertising platform and brings a considerable advertising revenue increase. We also summarize our detailed experiences in deployment in this paper.