 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDPE: A Multimodal Deception Dataset with Personality and Emotional Characteristics
Jul 17, 2024



Deception detection has garnered increasing attention in recent years due to the significant growth of digital media and heightened ethical and security concerns. It has been extensively studied using multimodal methods, including video, audio, and text. In addition, individual differences in deception production and detection are believed to play a crucial role.Although some studies have utilized individual information such as personality traits to enhance the performance of deception detection, current systems remain limited, partly due to a lack of sufficient datasets for evaluating performance. To address this issue, we introduce a multimodal deception dataset MDPE. Besides deception features, this dataset also includes individual differences information in personality and emotional expression characteristics. It can explore the impact of individual differences on deception behavior. It comprises over 104 hours of deception and emotional videos from 193 subjects. Furthermore, we conducted numerous experiments to provide valuable insights for future deception detection research. MDPE not only supports deception detection, but also provides conditions for tasks such as personality recognition and emotion recognition, and can even study the relationships between them. We believe that MDPE will become a valuable resource for promoting research in the field of affective computing.
Two-Aspect Information Fusion Model For ABAW4 Multi-task Challenge
Jul 23, 2022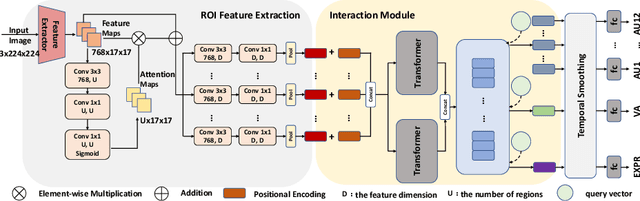
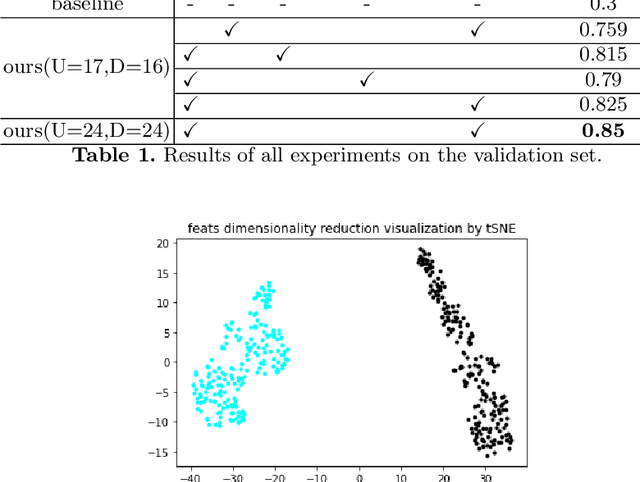

In this paper, we propose the solution to the Multi-Task Learning (MTL) Challenge of the 4th Affective Behavior Analysis in-the-wild (ABAW) competition. The task of ABAW is to predict frame-level emotion descriptors from videos: discrete emotional state; valence and arousal; and action units. Although researchers have proposed several approaches and achieved promising results in ABAW, current works in this task rarely consider interactions between different emotion descriptors. To this end, we propose a novel end to end architecture to achieve full integration of different types of information. Experimental results demonstrate the effectiveness of our proposed solution.
EmotionNAS: Two-stream Architecture Search for Speech Emotion Recognition
Mar 25, 2022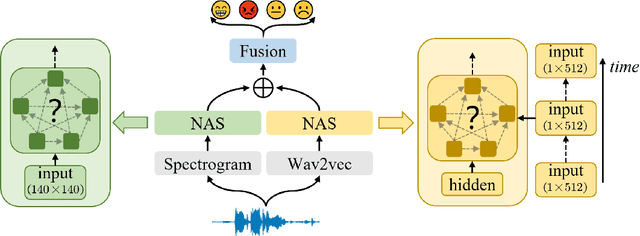
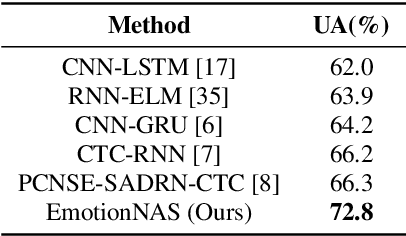
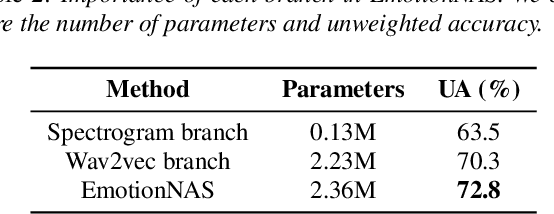
Speech emotion recognition (SER) is a crucial research topic in human-computer interactions. Existing works are mainly based on manually designed models. Despite their great success, these methods heavily rely on historical experience, which are time-consuming but cannot exhaust all possible structures. To address this problem, we propose a neural architecture search (NAS) based framework for SER, called "EmotionNAS". We take spectrogram and wav2vec features as the inputs, followed with NAS to optimize the network structure for these features separately. We further incorporate complementary information in these features through decision-level fusion. Experimental results on IEMOCAP demonstrate that our method succeeds over existing state-of-the-art strategies on SER.