 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPU Kernel Optimization Beyond Full Builds: An LLM Framework with Minimal Executable Programs
Dec 15, 2025In high-performance computing, hotspot GPU kernels are primary bottlenecks, and expert manual tuning is costly and hard to port. Large language model methods often assume kernels can be compiled and executed cheaply, which fails in large applications where full builds and runs are expensive. We present an end-to-end LLM framework with performance feedback that optimizes kernels without building the full application. From independently extracted hotspot kernels, it automatically completes code into a Minimal Executable Program (MEP), then performs multi-round iterative optimization and evaluation outside the full application. The framework integrates Automatic Error Repair and Performance Pattern Inheritance to fix faults, preserve correctness, reuse effective tiling/memory/synchronization strategies, and reduce search cost. Optimized variants are reintegrated into the original application for validation. We evaluate on NVIDIA GPUs and the Haiguang Deep Computing Unit (DCU) platform (AMD-licensed architecture) using PolyBench, the AMD APP SDK, and hotspot kernels from large-scale supercomputing applications. The method achieves average speedups of 5.05x (PolyBench on NVIDIA), 7.77x (PolyBench on DCU), 1.77x (AMD APP SDK), and 1.25x on three hotspot kernels, surpassing direct LLM optimization. The approach requires no full-source dependencies, offers cross-platform portability, and enables practical, low-cost GPU kernel optimization.
Refining CLIP's Spatial Awareness: A Visual-Centric Perspective
Apr 03, 2025



Contrastive Language-Image Pre-training (CLIP) excels in global alignment with language but exhibits limited sensitivity to spatial information, leading to strong performance in zero-shot classification tasks but underperformance in tasks requiring precise spatial understanding. Recent approaches have introduced Region-Language Alignment (RLA) to enhance CLIP's performance in dense multimodal tasks by aligning regional visual representations with corresponding text inputs. However, we find that CLIP ViTs fine-tuned with RLA suffer from notable loss in spatial awareness, which is crucial for dense prediction tasks. To address this, we propose the Spatial Correlation Distillation (SCD) framework, which preserves CLIP's inherent spatial structure and mitigates the above degradation. To further enhance spatial correlations, we introduce a lightweight Refiner that extracts refined correlations directly from CLIP before feeding them into SCD, based on an intriguing finding that CLIP naturally captures high-quality dense features. Together, these components form a robust distillation framework that enables CLIP ViTs to integrate both visual-language and visual-centric improvements, achieving state-of-the-art results across various open-vocabulary dense prediction benchmarks.
Accelerate 3D Object Detection Models via Zero-Shot Attention Key Pruning
Mar 11, 2025



Query-based methods with dense features have demonstrated remarkable success in 3D object detection tasks. However, the computational demands of these models, particularly with large image sizes and multiple transformer layers, pose significant challenges for efficient running on edge devices. Existing pruning and distillation methods either need retraining or are designed for ViT models, which are hard to migrate to 3D detectors. To address this issue, we propose a zero-shot runtime pruning method for transformer decoders in 3D object detection models. The method, termed tgGBC (trim keys gradually Guided By Classification scores), systematically trims keys in transformer modules based on their importance. We expand the classification score to multiply it with the attention map to get the importance score of each key and then prune certain keys after each transformer layer according to their importance scores. Our method achieves a 1.99x speedup in the transformer decoder of the latest ToC3D model, with only a minimal performance loss of less than 1%. Interestingly, for certain models, our method even enhances their performance. Moreover, we deploy 3D detectors with tgGBC on an edge device, further validating the effectiveness of our method. The code can be found at https://github.com/iseri27/tg_gbc.
Redundant Queries in DETR-Based 3D Detection Methods: Unnecessary and Prunable
Dec 03, 2024



Query-based models are extensively used in 3D object detection tasks, with a wide range of pre-trained checkpoints readily available online. However, despite their popularity, these models often require an excessive number of object queries, far surpassing the actual number of objects to detect. The redundant queries result in unnecessary computational and memory costs. In this paper, we find that not all queries contribute equally -- a significant portion of queries have a much smaller impact compared to others. Based on this observation, we propose an embarrassingly simple approach called \bd{G}radually \bd{P}runing \bd{Q}ueries (GPQ), which prunes queries incrementally based on their classification scores. It is straightforward to implement in any query-based method, as it can be seamlessly integrated as a fine-tuning step using an existing checkpoint after training. With GPQ, users can easily generate multiple models with fewer queries, starting from a checkpoint with an excessive number of queries. Experiments on various advanced 3D detectors show that GPQ effectively reduces redundant queries while maintaining performance. Using our method, model inference on desktop GPUs can be accelerated by up to 1.31x. Moreover, after deployment on edge devices, it achieves up to a 67.86\% reduction in FLOPs and a 76.38\% decrease in inference time. The code will be available at \url{https://github.com/iseri27/Gpq}.
Positional Prompt Tuning for Efficient 3D Representation Learning
Aug 21, 2024



Point cloud analysis has achieved significant development and is well-performed in multiple downstream tasks like point cloud classification and segmentation, etc. Being conscious of the simplicity of the position encoding structure in Transformer-based architectures, we attach importance to the position encoding as a high-dimensional part and the patch encoder to offer multi-scale information. Together with the sequential Transformer, the whole module with position encoding comprehensively constructs a multi-scale feature abstraction module that considers both the local parts from the patch and the global parts from center points as position encoding. With only a few parameters, the position embedding module fits the setting of PEFT (Parameter-Efficient Fine-Tuning) tasks pretty well. Thus we unfreeze these parameters as a fine-tuning part. At the same time, we review the existing prompt and adapter tuning methods, proposing a fresh way of prompts and synthesizing them with adapters as dynamic adjustments. Our Proposed method of PEFT tasks, namely PPT, with only 1.05% of parameters for training, gets state-of-the-art results in several mainstream datasets, such as 95.01% accuracy in the ScanObjectNN OBJ_BG dataset. Codes will be released at https://github.com/zsc000722/PPT.
Mode-locking Theory for Long-Range Interaction in Artificial Neural Networks
Mar 10, 2023



Visual long-range interaction refers to modeling dependencies between distant feature points or blocks within an image, which can significantly enhance the model's robustness. Both CNN and Transformer can establish long-range interactions through layering and patch calculations. However, the underlying mechanism of long-range interaction in visual space remains unclear. We propose the mode-locking theory as the underlying mechanism, which constrains the phase and wavelength relationship between waves to achieve mode-locked interference waveform. We verify this theory through simulation experiments and demonstrate the mode-locking pattern in real-world scene models. Our proposed theory of long-range interaction provides a comprehensive understanding of the mechanism behind this phenomenon in artificial neural networks. This theory can inspire the integration of the mode-locking pattern into models to enhance their robustness.
Emergence of Double-slit Interference by Representing Visual Space in Artificial Neural Networks
May 20, 2022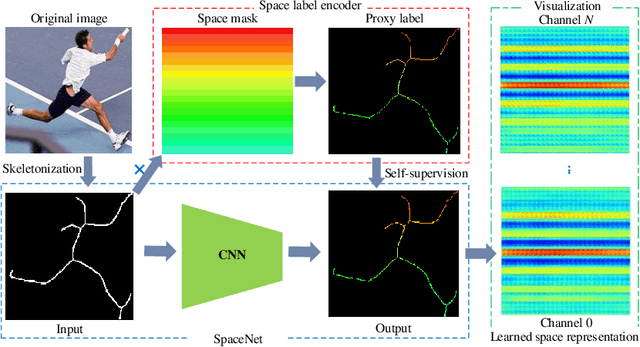
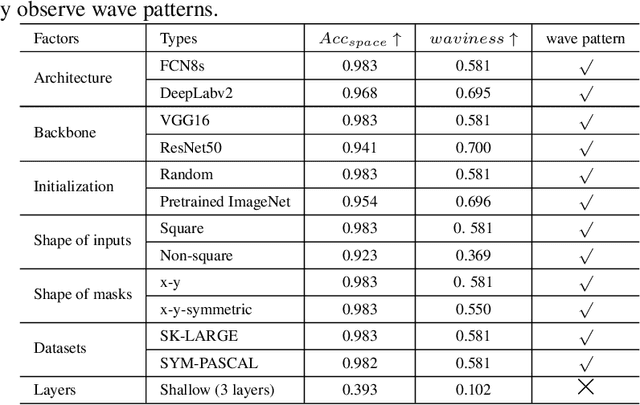
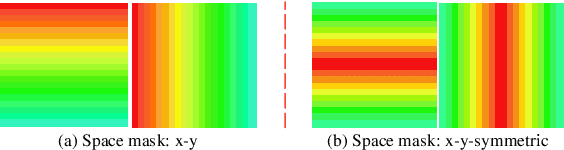
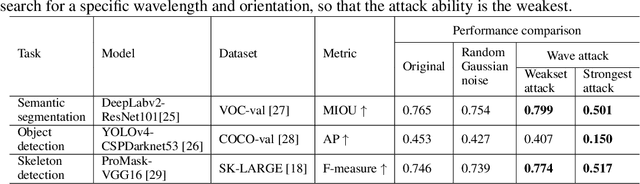
Artificial neural networks have realized incredible successes at image recognition, but the underlying mechanism of visual space representation remains a huge mystery. Grid cells (2014 Nobel Prize) in the entorhinal cortex support a periodic representation as a metric for coding space. Here, we develop a self-supervised convolutional neural network to perform visual space location, leading to the emergence of single-slit diffraction and double-slit interference patterns of waves. Our discoveries reveal the nature of CNN encoding visual space to a certain extent. CNN is no longer a black box in terms of visual spatial encoding, it is interpretable. Our findings indicate that the periodicity property of waves provides a space metric, suggesting a general role of spatial coordinate frame in artificial neural networks.
ProMask: Probability Mask for Skeleton Detection
Dec 05, 2020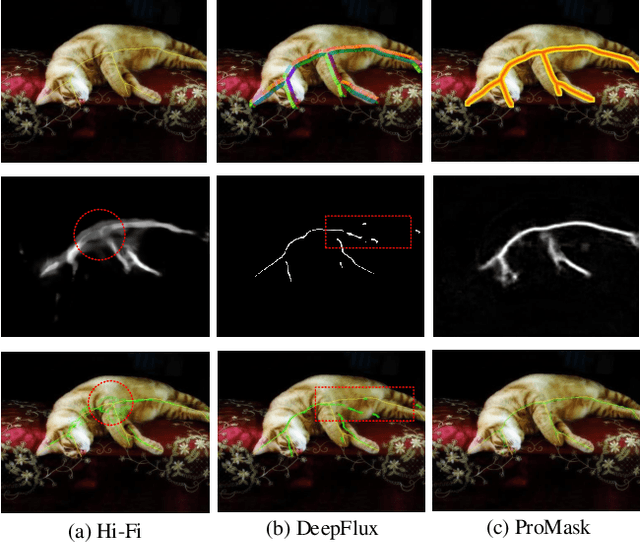
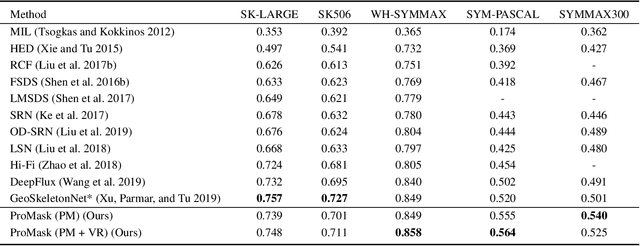
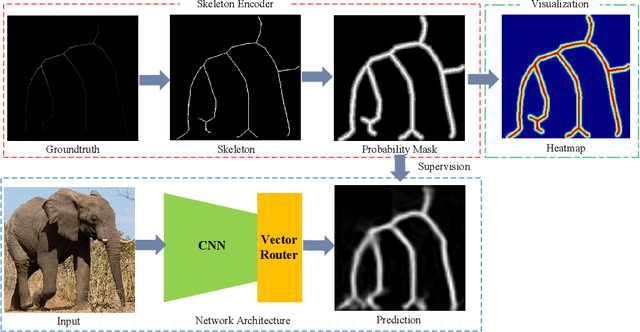
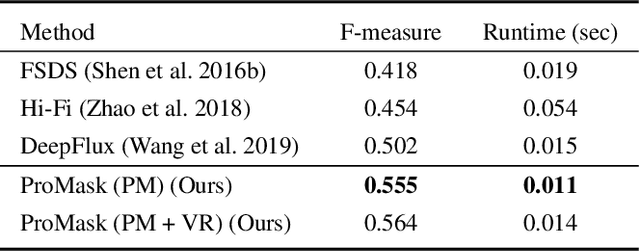
Detecting object skeletons in natural images presents challenging, due to varied object scales, the complexity of backgrounds and various noises. The skeleton is a highly compressing shape representation, which can bring some essential advantages but cause the difficulties of detection. This skeleton line occupies a rare proportion of an image and is overly sensitive to spatial position. Inspired by these issues, we propose the ProMask, which is a novel skeleton detection model. The ProMask includes the probability mask and vector router. The skeleton probability mask representation explicitly encodes skeletons with segmentation signals, which can provide more supervised information to learn and pay more attention to ground-truth skeleton pixels. Moreover, the vector router module possesses two sets of orthogonal basis vectors in a two-dimensional space, which can dynamically adjust the predicted skeleton position. We evaluate our method on the well-known skeleton datasets, realizing the better performance than state-of-the-art approaches. Especially, ProMask significantly outperforms the competitive DeepFlux by 6.2% on the challenging SYM-PASCAL dataset. We consider that our proposed skeleton probability mask could serve as a solid baseline for future skeleton detection, since it is very effective and it requires about 10 lines of code.