 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBernard Ghanem
Pix4Point: Image Pretrained Transformers for 3D Point Cloud Understanding
Aug 25, 2022
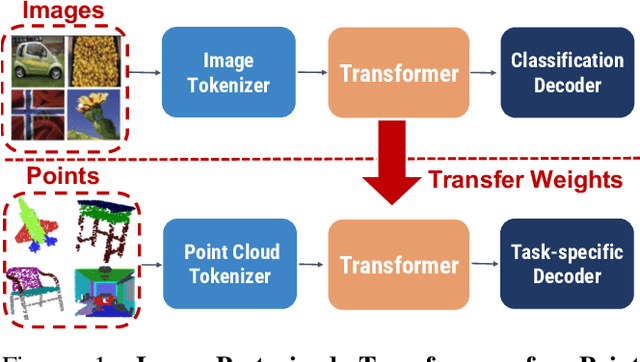
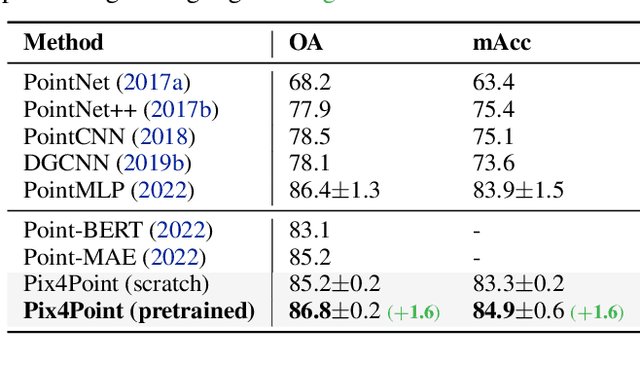
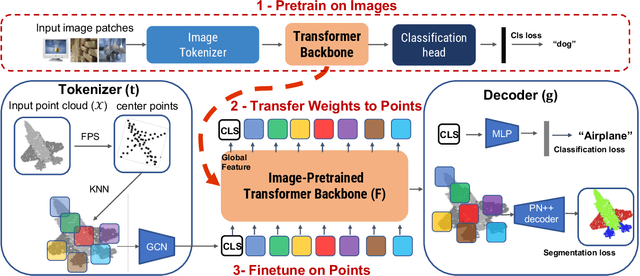
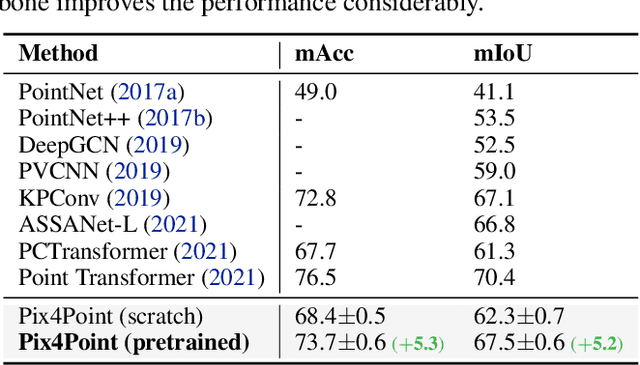
Pure Transformer models have achieved impressive success in natural language processing and computer vision. However, one limitation with Transformers is their need for large training data. In the realm of 3D point clouds, the availability of large datasets is a challenge, which exacerbates the issue of training Transformers for 3D tasks. In this work, we empirically study and investigate the effect of utilizing knowledge from a large number of images for point cloud understanding. We formulate a pipeline dubbed \textit{Pix4Point} that allows harnessing pretrained Transformers in the image domain to improve downstream point cloud tasks. This is achieved by a modality-agnostic pure Transformer backbone with the help of tokenizer and decoder layers specialized in the 3D domain. Using image-pretrained Transformers, we observe significant performance gains of Pix4Point on the tasks of 3D point cloud classification, part segmentation, and semantic segmentation on ScanObjectNN, ShapeNetPart, and S3DIS benchmarks, respectively. Our code and models are available at: \url{https://github.com/guochengqian/Pix4Point}.
Combating Mode Collapse in GANs via Manifold Entropy Estimation
Aug 25, 2022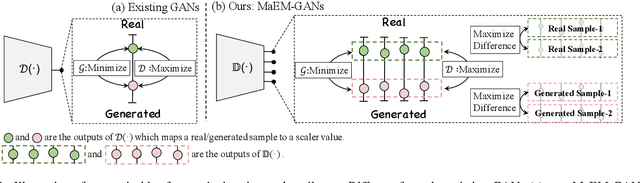
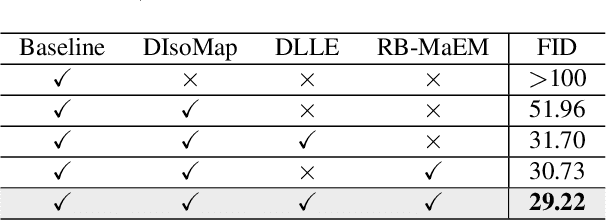
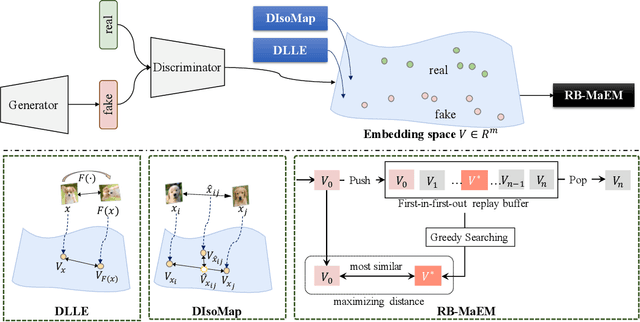
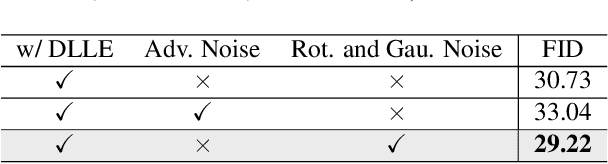
Generative Adversarial Networks (GANs) have shown compelling results in various tasks and applications in recent years. However, mode collapse remains a critical problem in GANs. In this paper, we propose a novel training pipeline to address the mode collapse issue of GANs. Different from existing methods, we propose to generalize the discriminator as feature embedding, and maximize the entropy of distributions in the embedding space learned by the discriminator. Specifically, two regularization terms, i.e.Deep Local Linear Embedding (DLLE) and Deep Isometric feature Mapping (DIsoMap), are designed to encourage the discriminator to learn the structural information embedded in the data, such that the embedding space learned by the discriminator can be well formed. Based on the well-learned embedding space supported by the discriminator, a non-parametric entropy estimator is designed to efficiently maximize the entropy of embedding vectors, playing as an approximation of maximizing the entropy of the generated distribution. Through improving the discriminator and maximizing the distance of the most similar samples in the embedding space, our pipeline effectively reduces the mode collapse without sacrificing the quality of generated samples. Extensive experimental results show the effectiveness of our method which outperforms the GAN baseline, MaF-GAN on CelebA (9.13 vs. 12.43 in FID) and surpasses the recent state-of-the-art energy-based model on the ANIME-FACE dataset (2.80 vs. 2.26 in Inception score).
Negative Frames Matter in Egocentric Visual Query 2D Localization
Aug 03, 2022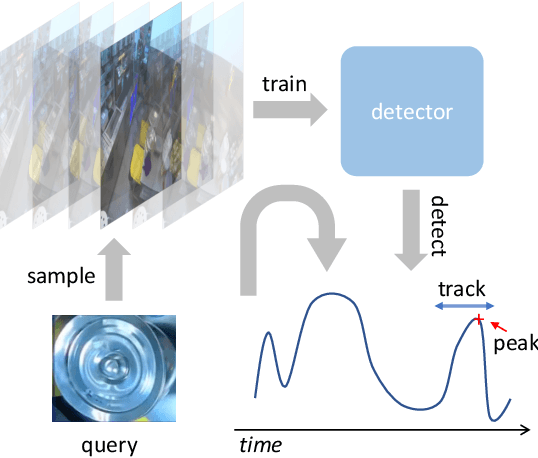
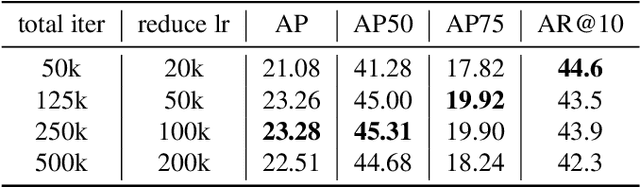

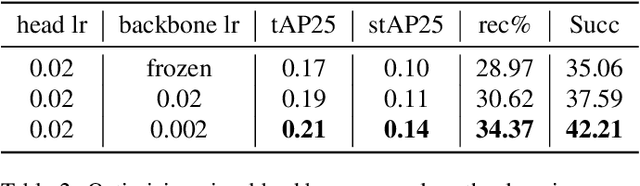
The recently released Ego4D dataset and benchmark significantly scales and diversifies the first-person visual perception data. In Ego4D, the Visual Queries 2D Localization task aims to retrieve objects appeared in the past from the recording in the first-person view. This task requires a system to spatially and temporally localize the most recent appearance of a given object query, where query is registered by a single tight visual crop of the object in a different scene. Our study is based on the three-stage baseline introduced in the Episodic Memory benchmark. The baseline solves the problem by detection and tracking: detect the similar objects in all the frames, then run a tracker from the most confident detection result. In the VQ2D challenge, we identified two limitations of the current baseline. (1) The training configuration has redundant computation. Although the training set has millions of instances, most of them are repetitive and the number of unique object is only around 14.6k. The repeated gradient computation of the same object lead to an inefficient training; (2) The false positive rate is high on background frames. This is due to the distribution gap between training and evaluation. During training, the model is only able to see the clean, stable, and labeled frames, but the egocentric videos also have noisy, blurry, or unlabeled background frames. To this end, we developed a more efficient and effective solution. Concretely, we bring the training loop from ~15 days to less than 24 hours, and we achieve 0.17% spatial-temporal AP, which is 31% higher than the baseline. Our solution got the first ranking on the public leaderboard. Our code is publicly available at https://github.com/facebookresearch/vq2d_cvpr.
Egocentric Video-Language Pretraining @ Ego4D Challenge 2022
Jul 04, 2022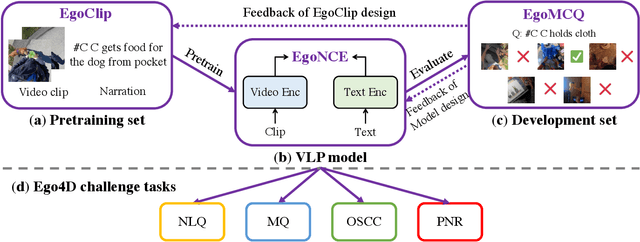
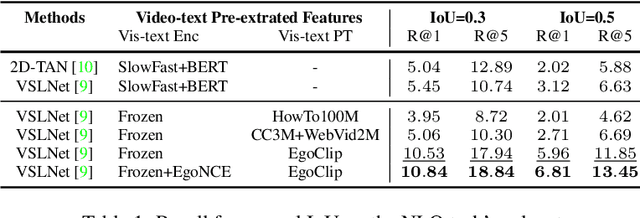
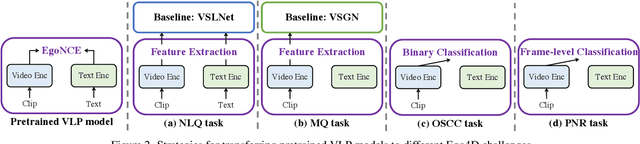
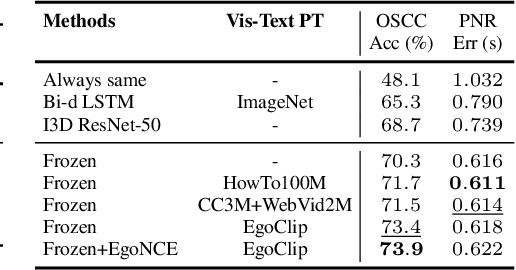
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for four Ego4D challenge tasks, including Natural Language Query (NLQ), Moment Query (MQ), Object State Change Classification (OSCC), and PNR Localization (PNR). Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation or video-only representation to several video downstream tasks. Our Egocentric VLP achieves 10.46R@1&IoU @0.3 on NLQ, 10.33 mAP on MQ, 74% Acc on OSCC, 0.67 sec error on PNR. The code is available at https://github.com/showlab/EgoVLP.
PointNeXt: Revisiting PointNet++ with Improved Training and Scaling Strategies
Jun 09, 2022
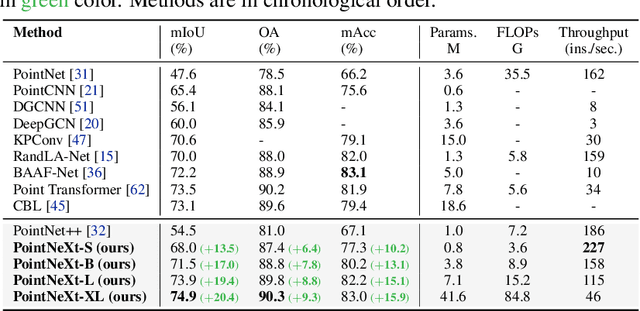
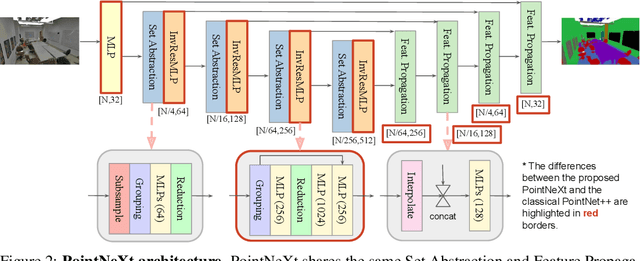
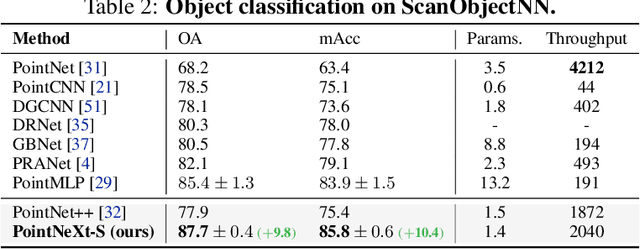
PointNet++ is one of the most influential neural architectures for point cloud understanding. Although the accuracy of PointNet++ has been largely surpassed by recent networks such as PointMLP and Point Transformer, we find that a large portion of the performance gain is due to improved training strategies, i.e. data augmentation and optimization techniques, and increased model sizes rather than architectural innovations. Thus, the full potential of PointNet++ has yet to be explored. In this work, we revisit the classical PointNet++ through a systematic study of model training and scaling strategies, and offer two major contributions. First, we propose a set of improved training strategies that significantly improve PointNet++ performance. For example, we show that, without any change in architecture, the overall accuracy (OA) of PointNet++ on ScanObjectNN object classification can be raised from 77.9\% to 86.1\%, even outperforming state-of-the-art PointMLP. Second, we introduce an inverted residual bottleneck design and separable MLPs into PointNet++ to enable efficient and effective model scaling and propose PointNeXt, the next version of PointNets. PointNeXt can be flexibly scaled up and outperforms state-of-the-art methods on both 3D classification and segmentation tasks. For classification, PointNeXt reaches an overall accuracy of $87.7\%$ on ScanObjectNN, surpassing PointMLP by $2.3\%$, while being $10 \times$ faster in inference. For semantic segmentation, PointNeXt establishes a new state-of-the-art performance with $74.9\%$ mean IoU on S3DIS (6-fold cross-validation), being superior to the recent Point Transformer. The code and models are available at https://github.com/guochengqian/pointnext.
Certified Robustness in Federated Learning
Jun 06, 2022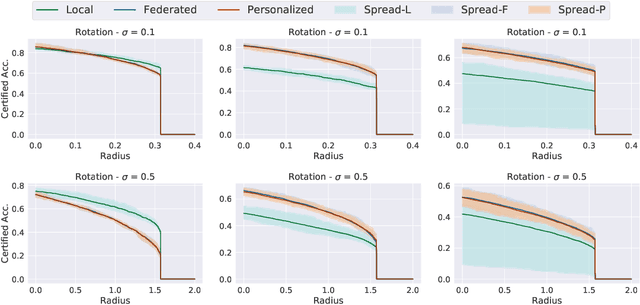
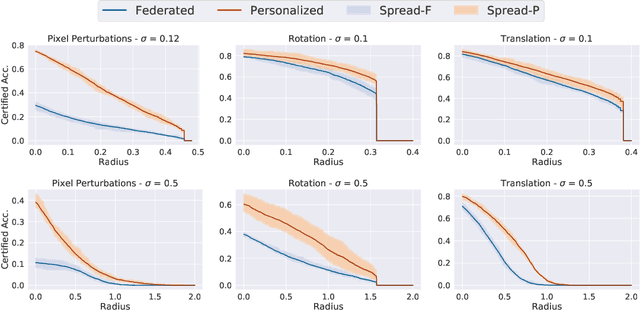

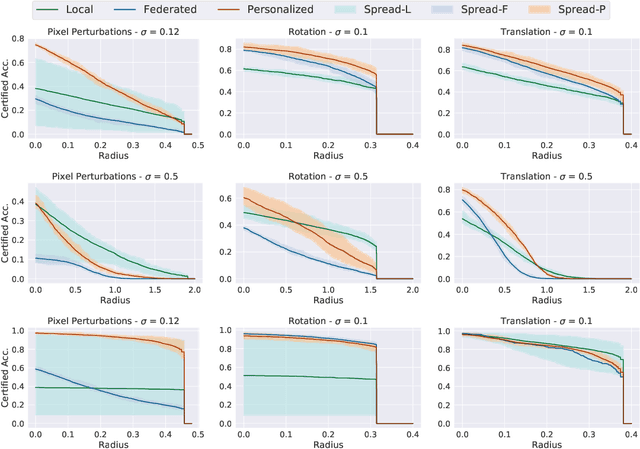
Federated learning has recently gained significant attention and popularity due to its effectiveness in training machine learning models on distributed data privately. However, as in the single-node supervised learning setup, models trained in federated learning suffer from vulnerability to imperceptible input transformations known as adversarial attacks, questioning their deployment in security-related applications. In this work, we study the interplay between federated training, personalization, and certified robustness. In particular, we deploy randomized smoothing, a widely-used and scalable certification method, to certify deep networks trained on a federated setup against input perturbations and transformations. We find that the simple federated averaging technique is effective in building not only more accurate, but also more certifiably-robust models, compared to training solely on local data. We further analyze personalization, a popular technique in federated training that increases the model's bias towards local data, on robustness. We show several advantages of personalization over both~(that is, only training on local data and federated training) in building more robust models with faster training. Finally, we explore the robustness of mixtures of global and local~(\ie personalized) models, and find that the robustness of local models degrades as they diverge from the global model
Egocentric Video-Language Pretraining
Jun 03, 2022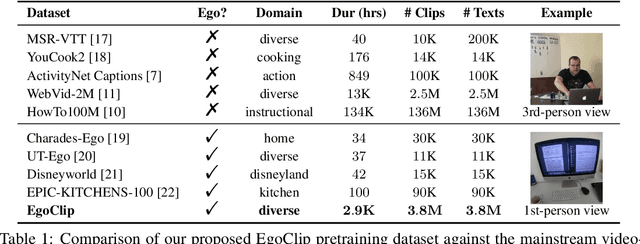
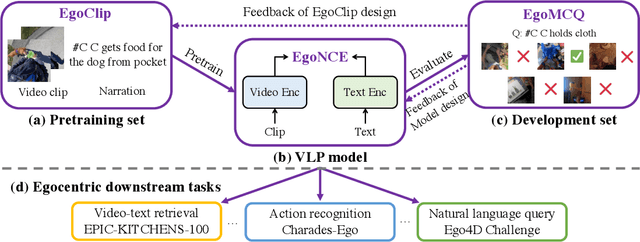

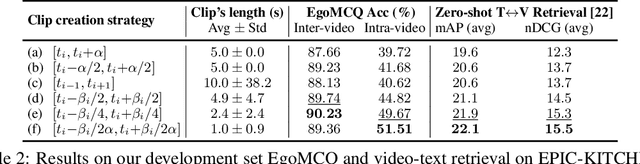
Video-Language Pretraining (VLP), aiming to learn transferable representation to advance a wide range of video-text downstream tasks, has recently received increasing attention. Dominant works that achieve strong performance rely on large-scale, 3rd-person video-text datasets, such as HowTo100M. In this work, we exploit the recently released Ego4D dataset to pioneer Egocentric VLP along three directions. (i) We create EgoClip, a 1st-person video-text pretraining dataset comprising 3.8M clip-text pairs well-chosen from Ego4D, covering a large variety of human daily activities. (ii) We propose a novel pretraining objective, dubbed as EgoNCE, which adapts video-text contrastive learning to egocentric domain by mining egocentric-aware positive and negative samples. (iii) We introduce EgoMCQ, a development benchmark that is close to EgoClip and hence can support effective validation and fast exploration of our design decisions regarding EgoClip and EgoNCE. Furthermore, we demonstrate strong performance on five egocentric downstream tasks across three datasets: video-text retrieval on EPIC-KITCHENS-100; action recognition on Charades-Ego; and natural language query, moment query, and object state change classification on Ego4D challenge benchmarks. The dataset and code will be available at https://github.com/showlab/EgoVLP.
UnrealNAS: Can We Search Neural Architectures with Unreal Data?
May 19, 2022
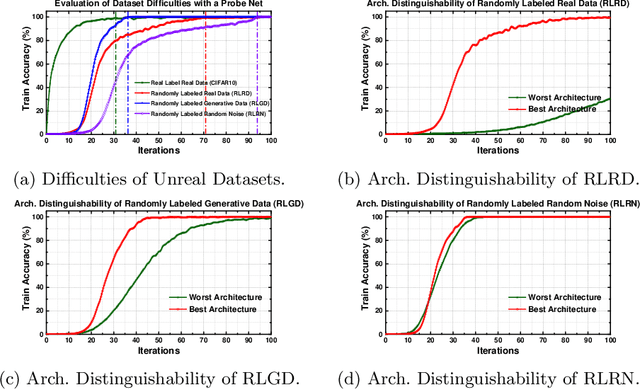
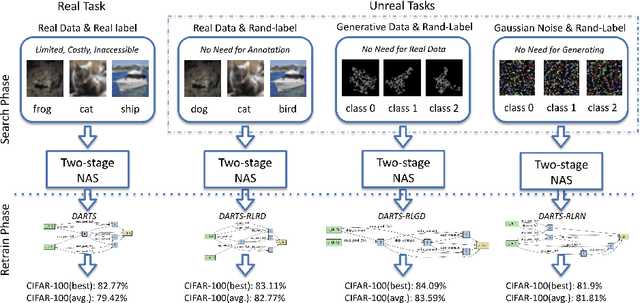
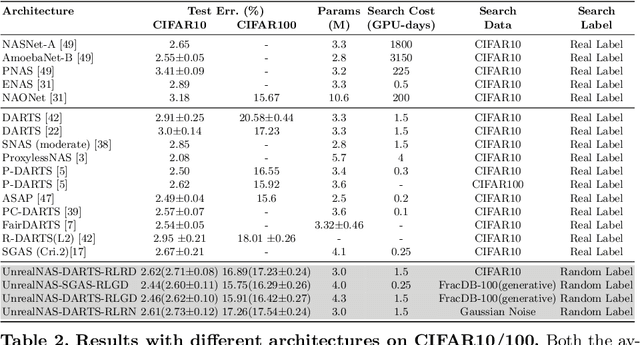
Neural architecture search (NAS) has shown great success in the automatic design of deep neural networks (DNNs). However, the best way to use data to search network architectures is still unclear and under exploration. Previous work has analyzed the necessity of having ground-truth labels in NAS and inspired broad interest. In this work, we take a further step to question whether real data is necessary for NAS to be effective. The answer to this question is important for applications with limited amount of accessible data, and can help people improve NAS by leveraging the extra flexibility of data generation. To explore if NAS needs real data, we construct three types of unreal datasets using: 1) randomly labeled real images; 2) generated images and labels; and 3) generated Gaussian noise with random labels. These datasets facilitate to analyze the generalization and expressivity of the searched architectures. We study the performance of architectures searched on these constructed datasets using popular differentiable NAS methods. Extensive experiments on CIFAR, ImageNet and CheXpert show that the searched architectures can achieve promising results compared with those derived from the conventional NAS pipeline with real labeled data, suggesting the feasibility of performing NAS with unreal data.
ETAD: A Unified Framework for Efficient Temporal Action Detection
May 14, 2022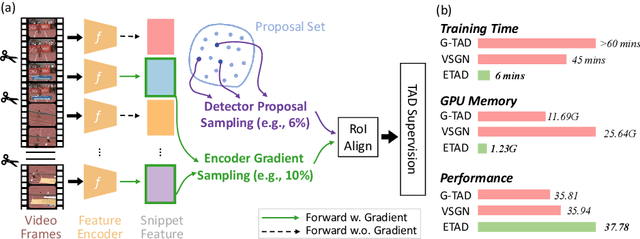
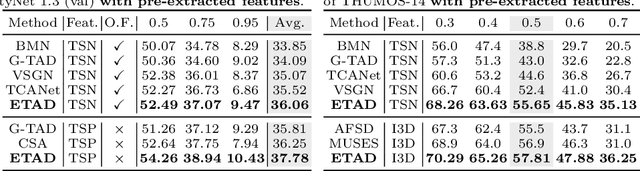
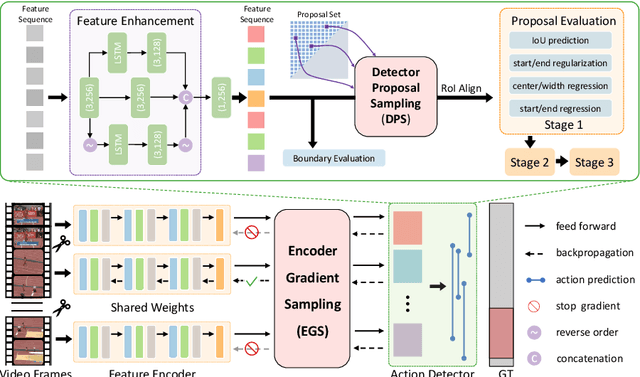
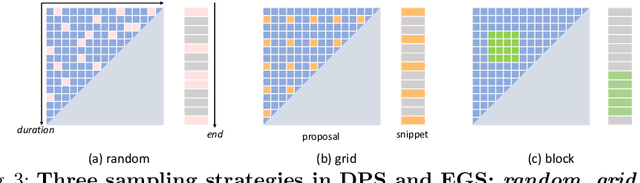
Untrimmed video understanding such as temporal action detection (TAD) often suffers from the pain of huge demand for computing resources. Because of long video durations and limited GPU memory, most action detectors can only operate on pre-extracted features rather than the original videos, and they still require a lot of computation to achieve high detection performance. To alleviate the heavy computation problem in TAD, in this work, we first propose an efficient action detector with detector proposal sampling, based on the observation that performance saturates at a small number of proposals. This detector is designed with several important techniques, such as LSTM-boosted temporal aggregation and cascaded proposal refinement to achieve high detection quality as well as low computational cost. To enable joint optimization of this action detector and the feature encoder, we also propose encoder gradient sampling, which selectively back-propagates through video snippets and tremendously reduces GPU memory consumption. With the two sampling strategies and the effective detector, we build a unified framework for efficient end-to-end temporal action detection (ETAD), making real-world untrimmed video understanding tractable. ETAD achieves state-of-the-art performance on both THUMOS-14 and ActivityNet-1.3. Interestingly, on ActivityNet-1.3, it reaches 37.78% average mAP, while only requiring 6 mins of training time and 1.23 GB memory based on pre-extracted features. With end-to-end training, it reduces the GPU memory footprint by more than 70% with even higher performance (38.21% average mAP), as compared with traditional end-to-end methods. The code is available at https://github.com/sming256/ETAD.