 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriving Hyperparameter Scaling Laws via Modern Optimization Theory
Mar 16, 2026Hyperparameter transfer has become an important component of modern large-scale training recipes. Existing methods, such as muP, primarily focus on transfer between model sizes, with transfer across batch sizes and training horizons often relying on empirical scaling rules informed by insights from timescale preservation, quadratic proxies, and continuous-time approximations. We study hyperparameter scaling laws for modern first-order optimizers through the lens of recent convergence bounds for methods based on the Linear Minimization Oracle (LMO), a framework that includes normalized SGD, signSGD (approximating Adam), and Muon. Treating bounds in recent literature as a proxy and minimizing them across different tuning regimes yields closed-form power-law schedules for learning rate, momentum, and batch size as functions of the iteration or token budget. Our analysis, holding model size fixed, recovers most insights and observations from the literature under a unified and principled perspective, with clear directions open for future research. Our results draw particular attention to the interaction between momentum and batch-size scaling, suggesting that optimal performance may be achieved with several scaling strategies.
First Provable Guarantees for Practical Private FL: Beyond Restrictive Assumptions
Dec 25, 2025Federated Learning (FL) enables collaborative training on decentralized data. Differential privacy (DP) is crucial for FL, but current private methods often rely on unrealistic assumptions (e.g., bounded gradients or heterogeneity), hindering practical application. Existing works that relax these assumptions typically neglect practical FL features, including multiple local updates and partial client participation. We introduce Fed-$α$-NormEC, the first differentially private FL framework providing provable convergence and DP guarantees under standard assumptions while fully supporting these practical features. Fed-$α$-NormE integrates local updates (full and incremental gradient steps), separate server and client stepsizes, and, crucially, partial client participation, which is essential for real-world deployment and vital for privacy amplification. Our theoretical guarantees are corroborated by experiments on private deep learning tasks.
Gluon: Making Muon & Scion Great Again! (Bridging Theory and Practice of LMO-based Optimizers for LLMs)
May 19, 2025Recent developments in deep learning optimization have brought about radically new algorithms based on the Linear Minimization Oracle (LMO) framework, such as $\sf Muon$ and $\sf Scion$. After over a decade of $\sf Adam$'s dominance, these LMO-based methods are emerging as viable replacements, offering several practical advantages such as improved memory efficiency, better hyperparameter transferability, and most importantly, superior empirical performance on large-scale tasks, including LLM training. However, a significant gap remains between their practical use and our current theoretical understanding: prior analyses (1) overlook the layer-wise LMO application of these optimizers in practice, and (2) rely on an unrealistic smoothness assumption, leading to impractically small stepsizes. To address both, we propose a new LMO-based method called $\sf Gluon$, capturing prior theoretically analyzed methods as special cases, and introduce a new refined generalized smoothness model that captures the layer-wise geometry of neural networks, matches the layer-wise practical implementation of $\sf Muon$ and $\sf Scion$, and leads to convergence guarantees with strong practical predictive power. Unlike prior results, our theoretical stepsizes closely match the fine-tuned values reported by Pethick et al. (2025). Our experiments with NanoGPT and CNN confirm that our assumption holds along the optimization trajectory, ultimately closing the gap between theory and practice.
Smoothed Normalization for Efficient Distributed Private Optimization
Feb 19, 2025Federated learning enables training machine learning models while preserving the privacy of participants. Surprisingly, there is no differentially private distributed method for smooth, non-convex optimization problems. The reason is that standard privacy techniques require bounding the participants' contributions, usually enforced via $\textit{clipping}$ of the updates. Existing literature typically ignores the effect of clipping by assuming the boundedness of gradient norms or analyzes distributed algorithms with clipping but ignores DP constraints. In this work, we study an alternative approach via $\textit{smoothed normalization}$ of the updates motivated by its favorable performance in the single-node setting. By integrating smoothed normalization with an error-feedback mechanism, we design a new distributed algorithm $\alpha$-$\sf NormEC$. We prove that our method achieves a superior convergence rate over prior works. By extending $\alpha$-$\sf NormEC$ to the DP setting, we obtain the first differentially private distributed optimization algorithm with provable convergence guarantees. Finally, our empirical results from neural network training indicate robust convergence of $\alpha$-$\sf NormEC$ across different parameter settings.
On the Convergence of DP-SGD with Adaptive Clipping
Dec 27, 2024
Stochastic Gradient Descent (SGD) with gradient clipping is a powerful technique for enabling differentially private optimization. Although prior works extensively investigated clipping with a constant threshold, private training remains highly sensitive to threshold selection, which can be expensive or even infeasible to tune. This sensitivity motivates the development of adaptive approaches, such as quantile clipping, which have demonstrated empirical success but lack a solid theoretical understanding. This paper provides the first comprehensive convergence analysis of SGD with quantile clipping (QC-SGD). We demonstrate that QC-SGD suffers from a bias problem similar to constant-threshold clipped SGD but show how this can be mitigated through a carefully designed quantile and step size schedule. Our analysis reveals crucial relationships between quantile selection, step size, and convergence behavior, providing practical guidelines for parameter selection. We extend these results to differentially private optimization, establishing the first theoretical guarantees for DP-QC-SGD. Our findings provide theoretical foundations for widely used adaptive clipping heuristic and highlight open avenues for future research.
SPAM: Stochastic Proximal Point Method with Momentum Variance Reduction for Non-convex Cross-Device Federated Learning
May 30, 2024

Cross-device training is a crucial subfield of federated learning, where the number of clients can reach into the billions. Standard approaches and local methods are prone to issues such as client drift and insensitivity to data similarities. We propose a novel algorithm (SPAM) for cross-device federated learning with non-convex losses, which solves both issues. We provide sharp analysis under second-order (Hessian) similarity, a condition satisfied by a variety of machine learning problems in practice. Additionally, we extend our results to the partial participation setting, where a cohort of selected clients communicate with the server at each communication round. Our method is the first in its kind, that does not require the smoothness of the objective and provably benefits from clients having similar data.
MAST: Model-Agnostic Sparsified Training
Nov 27, 2023We introduce a novel optimization problem formulation that departs from the conventional way of minimizing machine learning model loss as a black-box function. Unlike traditional formulations, the proposed approach explicitly incorporates an initially pre-trained model and random sketch operators, allowing for sparsification of both the model and gradient during training. We establish insightful properties of the proposed objective function and highlight its connections to the standard formulation. Furthermore, we present several variants of the Stochastic Gradient Descent (SGD) method adapted to the new problem formulation, including SGD with general sampling, a distributed version, and SGD with variance reduction techniques. We achieve tighter convergence rates and relax assumptions, bridging the gap between theoretical principles and practical applications, covering several important techniques such as Dropout and Sparse training. This work presents promising opportunities to enhance the theoretical understanding of model training through a sparsification-aware optimization approach.
Towards a Better Theoretical Understanding of Independent Subnetwork Training
Jun 28, 2023
Modern advancements in large-scale machine learning would be impossible without the paradigm of data-parallel distributed computing. Since distributed computing with large-scale models imparts excessive pressure on communication channels, significant recent research has been directed toward co-designing communication compression strategies and training algorithms with the goal of reducing communication costs. While pure data parallelism allows better data scaling, it suffers from poor model scaling properties. Indeed, compute nodes are severely limited by memory constraints, preventing further increases in model size. For this reason, the latest achievements in training giant neural network models also rely on some form of model parallelism. In this work, we take a closer theoretical look at Independent Subnetwork Training (IST), which is a recently proposed and highly effective technique for solving the aforementioned problems. We identify fundamental differences between IST and alternative approaches, such as distributed methods with compressed communication, and provide a precise analysis of its optimization performance on a quadratic model.
Shifted Compression Framework: Generalizations and Improvements
Jun 21, 2022
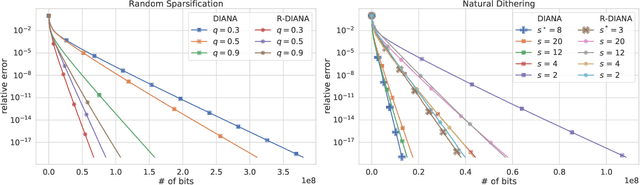
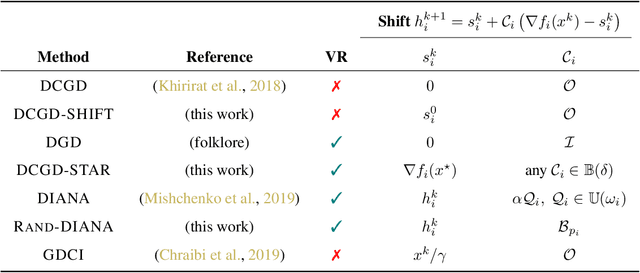
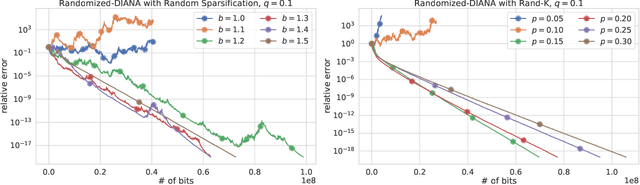
Communication is one of the key bottlenecks in the distributed training of large-scale machine learning models, and lossy compression of exchanged information, such as stochastic gradients or models, is one of the most effective instruments to alleviate this issue. Among the most studied compression techniques is the class of unbiased compression operators with variance bounded by a multiple of the square norm of the vector we wish to compress. By design, this variance may remain high, and only diminishes if the input vector approaches zero. However, unless the model being trained is overparameterized, there is no a-priori reason for the vectors we wish to compress to approach zero during the iterations of classical methods such as distributed compressed {\sf SGD}, which has adverse effects on the convergence speed. Due to this issue, several more elaborate and seemingly very different algorithms have been proposed recently, with the goal of circumventing this issue. These methods are based on the idea of compressing the {\em difference} between the vector we would normally wish to compress and some auxiliary vector which changes throughout the iterative process. In this work we take a step back, and develop a unified framework for studying such methods, conceptually, and theoretically. Our framework incorporates methods compressing both gradients and models, using unbiased and biased compressors, and sheds light on the construction of the auxiliary vectors. Furthermore, our general framework can lead to the improvement of several existing algorithms, and can produce new algorithms. Finally, we performed several numerical experiments which illustrate and support our theoretical findings.
Certified Robustness in Federated Learning
Jun 06, 2022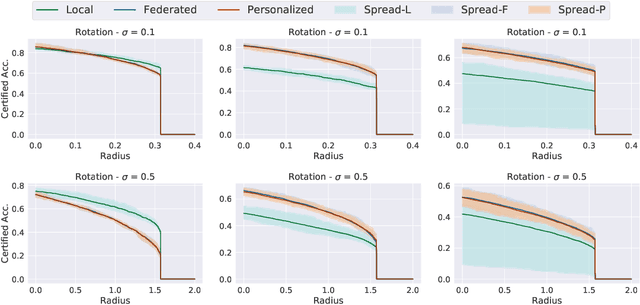
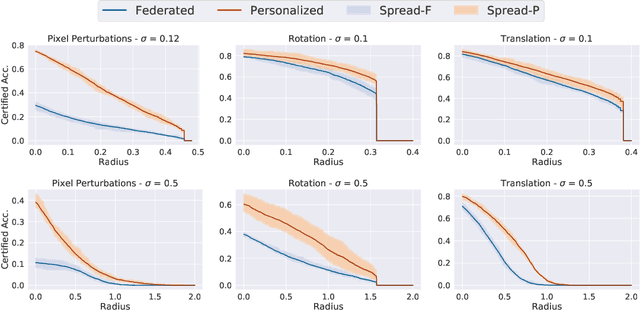

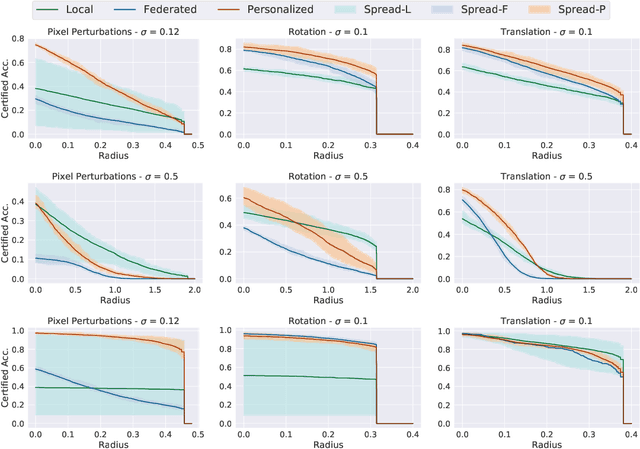
Federated learning has recently gained significant attention and popularity due to its effectiveness in training machine learning models on distributed data privately. However, as in the single-node supervised learning setup, models trained in federated learning suffer from vulnerability to imperceptible input transformations known as adversarial attacks, questioning their deployment in security-related applications. In this work, we study the interplay between federated training, personalization, and certified robustness. In particular, we deploy randomized smoothing, a widely-used and scalable certification method, to certify deep networks trained on a federated setup against input perturbations and transformations. We find that the simple federated averaging technique is effective in building not only more accurate, but also more certifiably-robust models, compared to training solely on local data. We further analyze personalization, a popular technique in federated training that increases the model's bias towards local data, on robustness. We show several advantages of personalization over both~(that is, only training on local data and federated training) in building more robust models with faster training. Finally, we explore the robustness of mixtures of global and local~(\ie personalized) models, and find that the robustness of local models degrades as they diverge from the global model