 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-DETR: An Efficient Low-Bit Quantized Detection Transformer
Apr 01, 2023



The recent detection transformer (DETR) has advanced object detection, but its application on resource-constrained devices requires massive computation and memory resources. Quantization stands out as a solution by representing the network in low-bit parameters and operations. However, there is a significant performance drop when performing low-bit quantized DETR (Q-DETR) with existing quantization methods. We find that the bottlenecks of Q-DETR come from the query information distortion through our empirical analyses. This paper addresses this problem based on a distribution rectification distillation (DRD). We formulate our DRD as a bi-level optimization problem, which can be derived by generalizing the information bottleneck (IB) principle to the learning of Q-DETR. At the inner level, we conduct a distribution alignment for the queries to maximize the self-information entropy. At the upper level, we introduce a new foreground-aware query matching scheme to effectively transfer the teacher information to distillation-desired features to minimize the conditional information entropy. Extensive experimental results show that our method performs much better than prior arts. For example, the 4-bit Q-DETR can theoretically accelerate DETR with ResNet-50 backbone by 6.6x and achieve 39.4% AP, with only 2.6% performance gaps than its real-valued counterpart on the COCO dataset.
Implicit Diffusion Models for Continuous Super-Resolution
Mar 29, 2023



Image super-resolution (SR) has attracted increasing attention due to its wide applications. However, current SR methods generally suffer from over-smoothing and artifacts, and most work only with fixed magnifications. This paper introduces an Implicit Diffusion Model (IDM) for high-fidelity continuous image super-resolution. IDM integrates an implicit neural representation and a denoising diffusion model in a unified end-to-end framework, where the implicit neural representation is adopted in the decoding process to learn continuous-resolution representation. Furthermore, we design a scale-controllable conditioning mechanism that consists of a low-resolution (LR) conditioning network and a scaling factor. The scaling factor regulates the resolution and accordingly modulates the proportion of the LR information and generated features in the final output, which enables the model to accommodate the continuous-resolution requirement. Extensive experiments validate the effectiveness of our IDM and demonstrate its superior performance over prior arts.
Confidence-driven Bounding Box Localization for Small Object Detection
Mar 03, 2023Despite advancements in generic object detection, there remains a performance gap in detecting small objects compared to normal-scale objects. We for the first time observe that existing bounding box regression methods tend to produce distorted gradients for small objects and result in less accurate localization. To address this issue, we present a novel Confidence-driven Bounding Box Localization (C-BBL) method to rectify the gradients. C-BBL quantizes continuous labels into grids and formulates two-hot ground truth labels. In prediction, the bounding box head generates a confidence distribution over the grids. Unlike the bounding box regression paradigms in conventional detectors, we introduce a classification-based localization objective through cross entropy between ground truth and predicted confidence distribution, generating confidence-driven gradients. Additionally, C-BBL describes a uncertainty loss based on distribution entropy in labels and predictions to further reduce the uncertainty in small object localization. The method is evaluated on multiple detectors using three object detection benchmarks and consistently improves baseline detectors, achieving state-of-the-art performance. We also demonstrate the generalizability of C-BBL to different label systems and effectiveness for high resolution detection, which validates its prospect as a general solution.
Resilient Binary Neural Network
Feb 05, 2023



Binary neural networks (BNNs) have received ever-increasing popularity for their great capability of reducing storage burden as well as quickening inference time. However, there is a severe performance drop compared with real-valued networks, due to its intrinsic frequent weight oscillation during training. In this paper, we introduce a Resilient Binary Neural Network (ReBNN) to mitigate the frequent oscillation for better BNNs' training. We identify that the weight oscillation mainly stems from the non-parametric scaling factor. To address this issue, we propose to parameterize the scaling factor and introduce a weighted reconstruction loss to build an adaptive training objective. For the first time, we show that the weight oscillation is controlled by the balanced parameter attached to the reconstruction loss, which provides a theoretical foundation to parameterize it in back propagation. Based on this, we learn our ReBNN by calculating the balanced parameter based on its maximum magnitude, which can effectively mitigate the weight oscillation with a resilient training process. Extensive experiments are conducted upon various network models, such as ResNet and Faster-RCNN for computer vision, as well as BERT for natural language processing. The results demonstrate the overwhelming performance of our ReBNN over prior arts. For example, our ReBNN achieves 66.9% Top-1 accuracy with ResNet-18 backbone on the ImageNet dataset, surpassing existing state-of-the-arts by a significant margin. Our code is open-sourced at https://github.com/SteveTsui/ReBNN.
CircleNet: Reciprocating Feature Adaptation for Robust Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially when the scene contains significant occlusion and/or low resolution of the pedestrians to be detected. Existing methods are unable to adapt to these difficult cases while maintaining acceptable performance. In this paper we propose a novel feature learning model, referred to as CircleNet, to achieve feature adaptation by mimicking the process humans looking at low resolution and occluded objects: focusing on it again, at a finer scale, if the object can not be identified clearly for the first time. CircleNet is implemented as a set of feature pyramids and uses weight sharing path augmentation for better feature fusion. It targets at reciprocating feature adaptation and iterative object detection using multiple top-down and bottom-up pathways. To take full advantage of the feature adaptation capability in CircleNet, we design an instance decomposition training strategy to focus on detecting pedestrian instances of various resolutions and different occlusion levels in each cycle. Specifically, CircleNet implements feature ensemble with the idea of hard negative boosting in an end-to-end manner. Experiments on two pedestrian detection datasets, Caltech and CityPersons, show that CircleNet improves the performance of occluded and low-resolution pedestrians with significant margins while maintaining good performance on normal instances.
Feature Calibration Network for Occluded Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially for scenes containing serious occlusion. In this paper, we propose a novel feature learning method in the deep learning framework, referred to as Feature Calibration Network (FC-Net), to adaptively detect pedestrians under various occlusions. FC-Net is based on the observation that the visible parts of pedestrians are selective and decisive for detection, and is implemented as a self-paced feature learning framework with a self-activation (SA) module and a feature calibration (FC) module. In a new self-activated manner, FC-Net learns features which highlight the visible parts and suppress the occluded parts of pedestrians. The SA module estimates pedestrian activation maps by reusing classifier weights, without any additional parameter involved, therefore resulting in an extremely parsimony model to reinforce the semantics of features, while the FC module calibrates the convolutional features for adaptive pedestrian representation in both pixel-wise and region-based ways. Experiments on CityPersons and Caltech datasets demonstrate that FC-Net improves detection performance on occluded pedestrians up to 10% while maintaining excellent performance on non-occluded instances.
Rethinking the Number of Shots in Robust Model-Agnostic Meta-Learning
Nov 28, 2022



Robust Model-Agnostic Meta-Learning (MAML) is usually adopted to train a meta-model which may fast adapt to novel classes with only a few exemplars and meanwhile remain robust to adversarial attacks. The conventional solution for robust MAML is to introduce robustness-promoting regularization during meta-training stage. With such a regularization, previous robust MAML methods simply follow the typical MAML practice that the number of training shots should match with the number of test shots to achieve an optimal adaptation performance. However, although the robustness can be largely improved, previous methods sacrifice clean accuracy a lot. In this paper, we observe that introducing robustness-promoting regularization into MAML reduces the intrinsic dimension of clean sample features, which results in a lower capacity of clean representations. This may explain why the clean accuracy of previous robust MAML methods drops severely. Based on this observation, we propose a simple strategy, i.e., increasing the number of training shots, to mitigate the loss of intrinsic dimension caused by robustness-promoting regularization. Though simple, our method remarkably improves the clean accuracy of MAML without much loss of robustness, producing a robust yet accurate model. Extensive experiments demonstrate that our method outperforms prior arts in achieving a better trade-off between accuracy and robustness. Besides, we observe that our method is less sensitive to the number of fine-tuning steps during meta-training, which allows for a reduced number of fine-tuning steps to improve training efficiency.
Q-ViT: Accurate and Fully Quantized Low-bit Vision Transformer
Oct 13, 2022
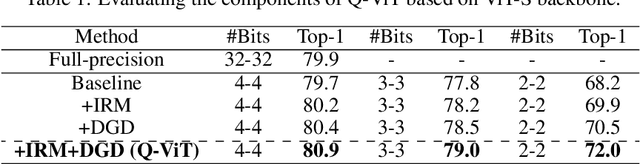
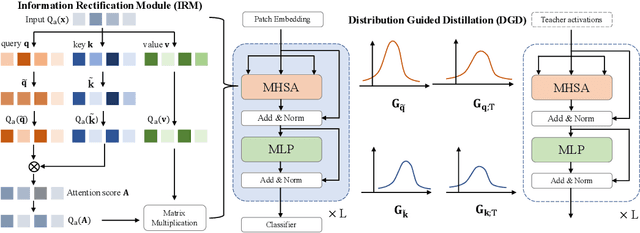
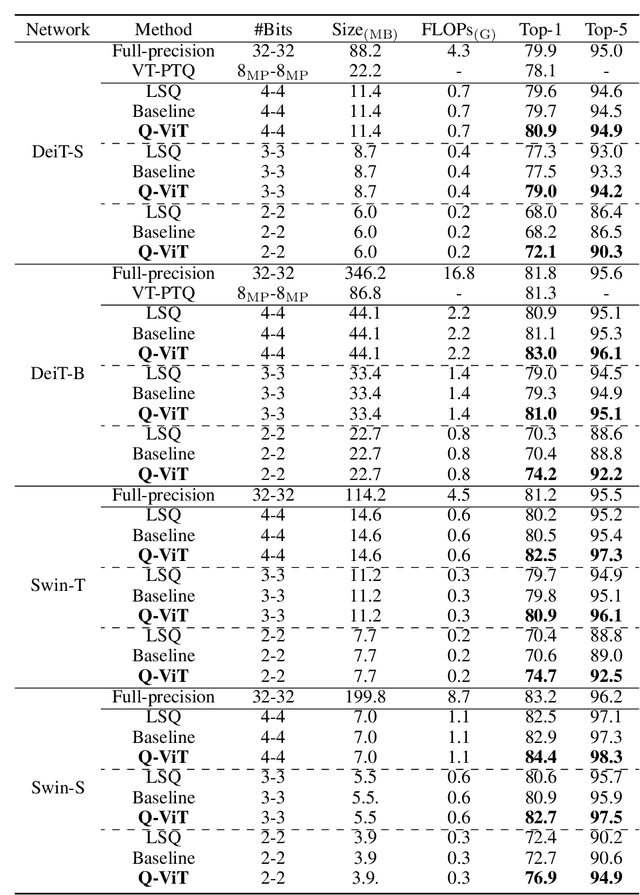
The large pre-trained vision transformers (ViTs) have demonstrated remarkable performance on various visual tasks, but suffer from expensive computational and memory cost problems when deployed on resource-constrained devices. Among the powerful compression approaches, quantization extremely reduces the computation and memory consumption by low-bit parameters and bit-wise operations. However, low-bit ViTs remain largely unexplored and usually suffer from a significant performance drop compared with the real-valued counterparts. In this work, through extensive empirical analysis, we first identify the bottleneck for severe performance drop comes from the information distortion of the low-bit quantized self-attention map. We then develop an information rectification module (IRM) and a distribution guided distillation (DGD) scheme for fully quantized vision transformers (Q-ViT) to effectively eliminate such distortion, leading to a fully quantized ViTs. We evaluate our methods on popular DeiT and Swin backbones. Extensive experimental results show that our method achieves a much better performance than the prior arts. For example, our Q-ViT can theoretically accelerates the ViT-S by 6.14x and achieves about 80.9% Top-1 accuracy, even surpassing the full-precision counterpart by 1.0% on ImageNet dataset. Our codes and models are attached on https://github.com/YanjingLi0202/Q-ViT
IDa-Det: An Information Discrepancy-aware Distillation for 1-bit Detectors
Oct 07, 2022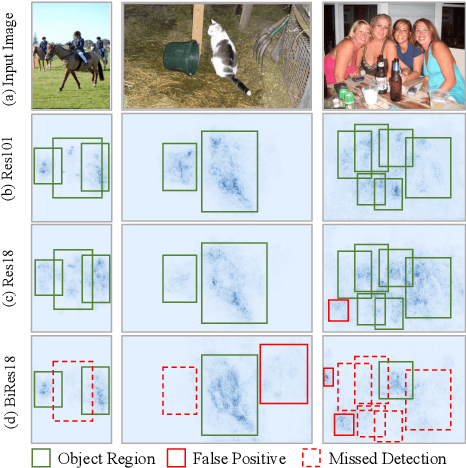
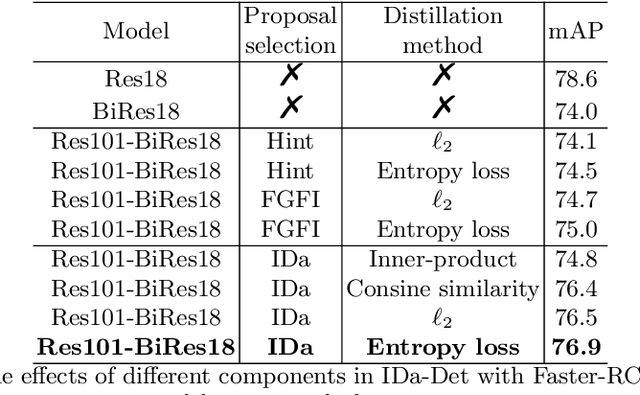
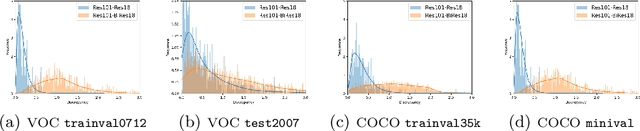
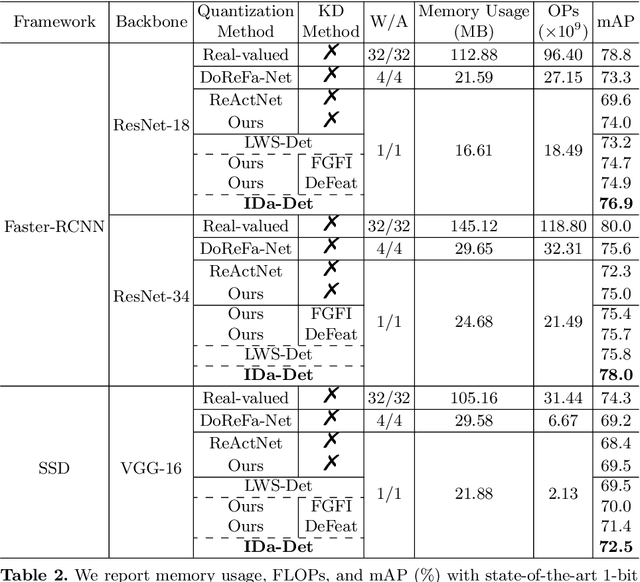
Knowledge distillation (KD) has been proven to be useful for training compact object detection models. However, we observe that KD is often effective when the teacher model and student counterpart share similar proposal information. This explains why existing KD methods are less effective for 1-bit detectors, caused by a significant information discrepancy between the real-valued teacher and the 1-bit student. This paper presents an Information Discrepancy-aware strategy (IDa-Det) to distill 1-bit detectors that can effectively eliminate information discrepancies and significantly reduce the performance gap between a 1-bit detector and its real-valued counterpart. We formulate the distillation process as a bi-level optimization formulation. At the inner level, we select the representative proposals with maximum information discrepancy. We then introduce a novel entropy distillation loss to reduce the disparity based on the selected proposals. Extensive experiments demonstrate IDa-Det's superiority over state-of-the-art 1-bit detectors and KD methods on both PASCAL VOC and COCO datasets. IDa-Det achieves a 76.9% mAP for a 1-bit Faster-RCNN with ResNet-18 backbone. Our code is open-sourced on https://github.com/SteveTsui/IDa-Det.
FNeVR: Neural Volume Rendering for Face Animation
Sep 21, 2022
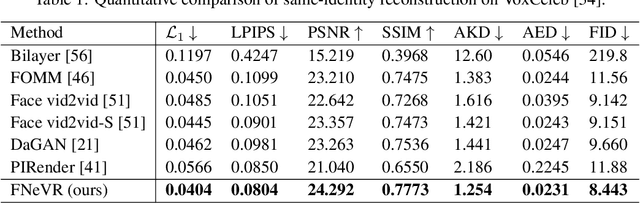
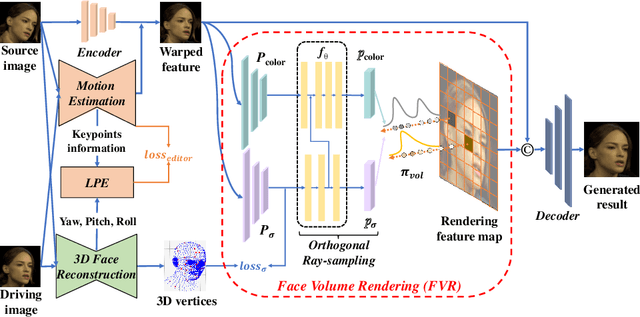
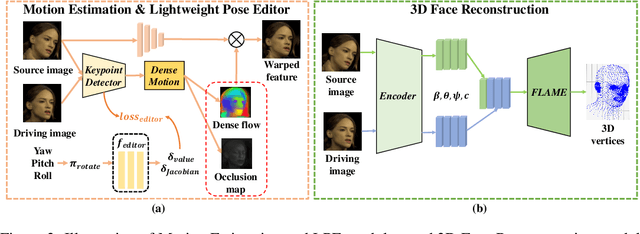
Face animation, one of the hottest topics in computer vision, has achieved a promising performance with the help of generative models. However, it remains a critical challenge to generate identity preserving and photo-realistic images due to the sophisticated motion deformation and complex facial detail modeling. To address these problems, we propose a Face Neural Volume Rendering (FNeVR) network to fully explore the potential of 2D motion warping and 3D volume rendering in a unified framework. In FNeVR, we design a 3D Face Volume Rendering (FVR) module to enhance the facial details for image rendering. Specifically, we first extract 3D information with a well-designed architecture, and then introduce an orthogonal adaptive ray-sampling module for efficient rendering. We also design a lightweight pose editor, enabling FNeVR to edit the facial pose in a simple yet effective way. Extensive experiments show that our FNeVR obtains the best overall quality and performance on widely used talking-head benchmarks.