 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePush Quantization-Aware Training Toward Full Precision Performances via Consistency Regularization
Feb 21, 2024Existing Quantization-Aware Training (QAT) methods intensively depend on the complete labeled dataset or knowledge distillation to guarantee the performances toward Full Precision (FP) accuracies. However, empirical results show that QAT still has inferior results compared to its FP counterpart. One question is how to push QAT toward or even surpass FP performances. In this paper, we address this issue from a new perspective by injecting the vicinal data distribution information to improve the generalization performances of QAT effectively. We present a simple, novel, yet powerful method introducing an Consistency Regularization (CR) for QAT. Concretely, CR assumes that augmented samples should be consistent in the latent feature space. Our method generalizes well to different network architectures and various QAT methods. Extensive experiments demonstrate that our approach significantly outperforms the current state-of-the-art QAT methods and even FP counterparts.
Class-Imbalanced Semi-Supervised Learning for Large-Scale Point Cloud Semantic Segmentation via Decoupling Optimization
Jan 13, 2024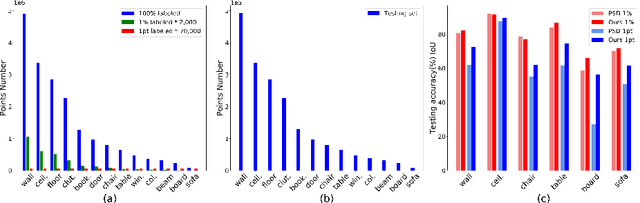
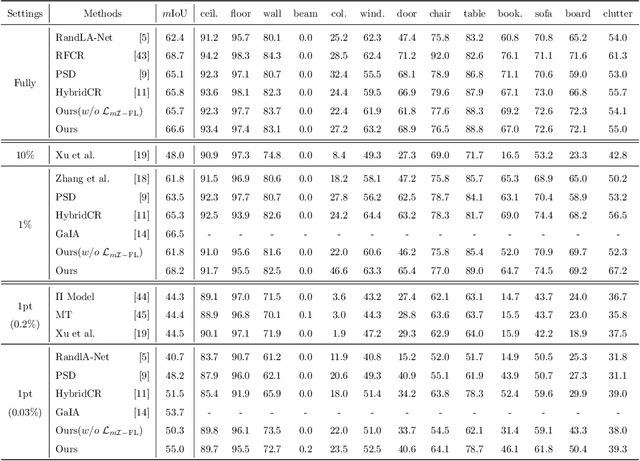
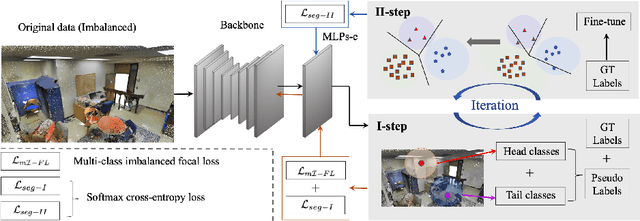

Semi-supervised learning (SSL), thanks to the significant reduction of data annotation costs, has been an active research topic for large-scale 3D scene understanding. However, the existing SSL-based methods suffer from severe training bias, mainly due to class imbalance and long-tail distributions of the point cloud data. As a result, they lead to a biased prediction for the tail class segmentation. In this paper, we introduce a new decoupling optimization framework, which disentangles feature representation learning and classifier in an alternative optimization manner to shift the bias decision boundary effectively. In particular, we first employ two-round pseudo-label generation to select unlabeled points across head-to-tail classes. We further introduce multi-class imbalanced focus loss to adaptively pay more attention to feature learning across head-to-tail classes. We fix the backbone parameters after feature learning and retrain the classifier using ground-truth points to update its parameters. Extensive experiments demonstrate the effectiveness of our method outperforming previous state-of-the-art methods on both indoor and outdoor 3D point cloud datasets (i.e., S3DIS, ScanNet-V2, Semantic3D, and SemanticKITTI) using 1% and 1pt evaluation.
ZONE: Zero-Shot Instruction-Guided Local Editing
Dec 28, 2023



Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., ``make his tie blue") into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods.
Tuning-Free Inversion-Enhanced Control for Consistent Image Editing
Dec 22, 2023

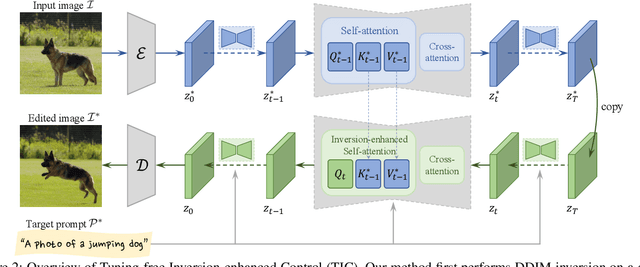

Consistent editing of real images is a challenging task, as it requires performing non-rigid edits (e.g., changing postures) to the main objects in the input image without changing their identity or attributes. To guarantee consistent attributes, some existing methods fine-tune the entire model or the textual embedding for structural consistency, but they are time-consuming and fail to perform non-rigid edits. Other works are tuning-free, but their performances are weakened by the quality of Denoising Diffusion Implicit Model (DDIM) reconstruction, which often fails in real-world scenarios. In this paper, we present a novel approach called Tuning-free Inversion-enhanced Control (TIC), which directly correlates features from the inversion process with those from the sampling process to mitigate the inconsistency in DDIM reconstruction. Specifically, our method effectively obtains inversion features from the key and value features in the self-attention layers, and enhances the sampling process by these inversion features, thus achieving accurate reconstruction and content-consistent editing. To extend the applicability of our method to general editing scenarios, we also propose a mask-guided attention concatenation strategy that combines contents from both the inversion and the naive DDIM editing processes. Experiments show that the proposed method outperforms previous works in reconstruction and consistent editing, and produces impressive results in various settings.
Federated Learning via Input-Output Collaborative Distillation
Dec 22, 2023



Federated learning (FL) is a machine learning paradigm in which distributed local nodes collaboratively train a central model without sharing individually held private data. Existing FL methods either iteratively share local model parameters or deploy co-distillation. However, the former is highly susceptible to private data leakage, and the latter design relies on the prerequisites of task-relevant real data. Instead, we propose a data-free FL framework based on local-to-central collaborative distillation with direct input and output space exploitation. Our design eliminates any requirement of recursive local parameter exchange or auxiliary task-relevant data to transfer knowledge, thereby giving direct privacy control to local users. In particular, to cope with the inherent data heterogeneity across locals, our technique learns to distill input on which each local model produces consensual yet unique results to represent each expertise. Our proposed FL framework achieves notable privacy-utility trade-offs with extensive experiments on image classification and segmentation tasks under various real-world heterogeneous federated learning settings on both natural and medical images.
LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation
Nov 01, 2023



Leveraging the generative ability of image diffusion models offers great potential for zero-shot video-to-video translation. The key lies in how to maintain temporal consistency across generated video frames by image diffusion models. Previous methods typically adopt cross-frame attention, \emph{i.e.,} sharing the \textit{key} and \textit{value} tokens across attentions of different frames, to encourage the temporal consistency. However, in those works, temporal inconsistency issue may not be thoroughly solved, rendering the fidelity of generated videos limited.%The current state of the art cross-frame attention method aims at maintaining fine-grained visual details across frames, but it is still challenged by the temporal coherence problem. In this paper, we find the bottleneck lies in the unconstrained query tokens and propose a new zero-shot video-to-video translation framework, named \textit{LatentWarp}. Our approach is simple: to constrain the query tokens to be temporally consistent, we further incorporate a warping operation in the latent space to constrain the query tokens. Specifically, based on the optical flow obtained from the original video, we warp the generated latent features of last frame to align with the current frame during the denoising process. As a result, the corresponding regions across the adjacent frames can share closely-related query tokens and attention outputs, which can further improve latent-level consistency to enhance visual temporal coherence of generated videos. Extensive experiment results demonstrate the superiority of \textit{LatentWarp} in achieving video-to-video translation with temporal coherence.
IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
Oct 09, 2023


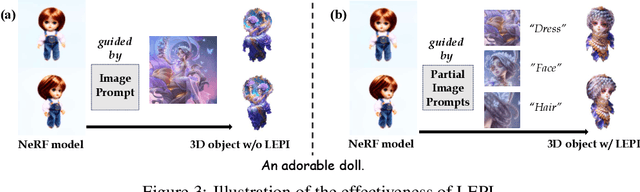
Recent advances in text-to-3D generation have been remarkable, with methods such as DreamFusion leveraging large-scale text-to-image diffusion-based models to supervise 3D generation. These methods, including the variational score distillation proposed by ProlificDreamer, enable the synthesis of detailed and photorealistic textured meshes. However, the appearance of 3D objects generated by these methods is often random and uncontrollable, posing a challenge in achieving appearance-controllable 3D objects. To address this challenge, we introduce IPDreamer, a novel approach that incorporates image prompts to provide specific and comprehensive appearance information for 3D object generation. Our results demonstrate that IPDreamer effectively generates high-quality 3D objects that are consistent with both the provided text and image prompts, demonstrating its promising capability in appearance-controllable 3D object generation.
Heterogeneous Generative Knowledge Distillation with Masked Image Modeling
Sep 18, 2023



Small CNN-based models usually require transferring knowledge from a large model before they are deployed in computationally resource-limited edge devices. Masked image modeling (MIM) methods achieve great success in various visual tasks but remain largely unexplored in knowledge distillation for heterogeneous deep models. The reason is mainly due to the significant discrepancy between the Transformer-based large model and the CNN-based small network. In this paper, we develop the first Heterogeneous Generative Knowledge Distillation (H-GKD) based on MIM, which can efficiently transfer knowledge from large Transformer models to small CNN-based models in a generative self-supervised fashion. Our method builds a bridge between Transformer-based models and CNNs by training a UNet-style student with sparse convolution, which can effectively mimic the visual representation inferred by a teacher over masked modeling. Our method is a simple yet effective learning paradigm to learn the visual representation and distribution of data from heterogeneous teacher models, which can be pre-trained using advanced generative methods. Extensive experiments show that it adapts well to various models and sizes, consistently achieving state-of-the-art performance in image classification, object detection, and semantic segmentation tasks. For example, in the Imagenet 1K dataset, H-GKD improves the accuracy of Resnet50 (sparse) from 76.98% to 80.01%.
Representation Disparity-aware Distillation for 3D Object Detection
Aug 20, 2023



In this paper, we focus on developing knowledge distillation (KD) for compact 3D detectors. We observe that off-the-shelf KD methods manifest their efficacy only when the teacher model and student counterpart share similar intermediate feature representations. This might explain why they are less effective in building extreme-compact 3D detectors where significant representation disparity arises due primarily to the intrinsic sparsity and irregularity in 3D point clouds. This paper presents a novel representation disparity-aware distillation (RDD) method to address the representation disparity issue and reduce performance gap between compact students and over-parameterized teachers. This is accomplished by building our RDD from an innovative perspective of information bottleneck (IB), which can effectively minimize the disparity of proposal region pairs from student and teacher in features and logits. Extensive experiments are performed to demonstrate the superiority of our RDD over existing KD methods. For example, our RDD increases mAP of CP-Voxel-S to 57.1% on nuScenes dataset, which even surpasses teacher performance while taking up only 42% FLOPs.
Q-YOLO: Efficient Inference for Real-time Object Detection
Jul 01, 2023Real-time object detection plays a vital role in various computer vision applications. However, deploying real-time object detectors on resource-constrained platforms poses challenges due to high computational and memory requirements. This paper describes a low-bit quantization method to build a highly efficient one-stage detector, dubbed as Q-YOLO, which can effectively address the performance degradation problem caused by activation distribution imbalance in traditional quantized YOLO models. Q-YOLO introduces a fully end-to-end Post-Training Quantization (PTQ) pipeline with a well-designed Unilateral Histogram-based (UH) activation quantization scheme, which determines the maximum truncation values through histogram analysis by minimizing the Mean Squared Error (MSE) quantization errors. Extensive experiments on the COCO dataset demonstrate the effectiveness of Q-YOLO, outperforming other PTQ methods while achieving a more favorable balance between accuracy and computational cost. This research contributes to advancing the efficient deployment of object detection models on resource-limited edge devices, enabling real-time detection with reduced computational and memory overhead.