 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Token-Level Confidence Improves Caption Correctness
May 11, 2023



The ability to judge whether a caption correctly describes an image is a critical part of vision-language understanding. However, state-of-the-art models often misinterpret the correctness of fine-grained details, leading to errors in outputs such as hallucinating objects in generated captions or poor compositional reasoning. In this work, we explore Token-Level Confidence, or TLC, as a simple yet surprisingly effective method to assess caption correctness. Specifically, we fine-tune a vision-language model on image captioning, input an image and proposed caption to the model, and aggregate either algebraic or learned token confidences over words or sequences to estimate image-caption consistency. Compared to sequence-level scores from pretrained models, TLC with algebraic confidence measures achieves a relative improvement in accuracy by 10% on verb understanding in SVO-Probes and outperforms prior state-of-the-art in image and group scores for compositional reasoning in Winoground by a relative 37% and 9%, respectively. When training data are available, a learned confidence estimator provides further improved performance, reducing object hallucination rates in MS COCO Captions by a relative 30% over the original model and setting a new state-of-the-art.
Shape-Guided Diffusion with Inside-Outside Attention
Dec 01, 2022



Shape can specify key object constraints, yet existing text-to-image diffusion models ignore this cue and synthesize objects that are incorrectly scaled, cut off, or replaced with background content. We propose a training-free method, Shape-Guided Diffusion, which uses a novel Inside-Outside Attention mechanism to constrain the cross-attention (and self-attention) maps such that prompt tokens (and pixels) referring to the inside of the shape cannot attend outside the shape, and vice versa. To demonstrate the efficacy of our method, we propose a new image editing task where the model must replace an object specified by its mask and a text prompt. We curate a new ShapePrompts benchmark based on MS-COCO and achieve SOTA results in shape faithfulness, text alignment, and realism according to both quantitative metrics and human preferences. Our data and code will be made available at https://shape-guided-diffusion.github.io.
Focus! Relevant and Sufficient Context Selection for News Image Captioning
Dec 01, 2022



News Image Captioning requires describing an image by leveraging additional context from a news article. Previous works only coarsely leverage the article to extract the necessary context, which makes it challenging for models to identify relevant events and named entities. In our paper, we first demonstrate that by combining more fine-grained context that captures the key named entities (obtained via an oracle) and the global context that summarizes the news, we can dramatically improve the model's ability to generate accurate news captions. This begs the question, how to automatically extract such key entities from an image? We propose to use the pre-trained vision and language retrieval model CLIP to localize the visually grounded entities in the news article and then capture the non-visual entities via an open relation extraction model. Our experiments demonstrate that by simply selecting a better context from the article, we can significantly improve the performance of existing models and achieve new state-of-the-art performance on multiple benchmarks.
G^3: Geolocation via Guidebook Grounding
Nov 28, 2022



We demonstrate how language can improve geolocation: the task of predicting the location where an image was taken. Here we study explicit knowledge from human-written guidebooks that describe the salient and class-discriminative visual features humans use for geolocation. We propose the task of Geolocation via Guidebook Grounding that uses a dataset of StreetView images from a diverse set of locations and an associated textual guidebook for GeoGuessr, a popular interactive geolocation game. Our approach predicts a country for each image by attending over the clues automatically extracted from the guidebook. Supervising attention with country-level pseudo labels achieves the best performance. Our approach substantially outperforms a state-of-the-art image-only geolocation method, with an improvement of over 5% in Top-1 accuracy. Our dataset and code can be found at https://github.com/g-luo/geolocation_via_guidebook_grounding.
TL;DW? Summarizing Instructional Videos with Task Relevance & Cross-Modal Saliency
Aug 14, 2022
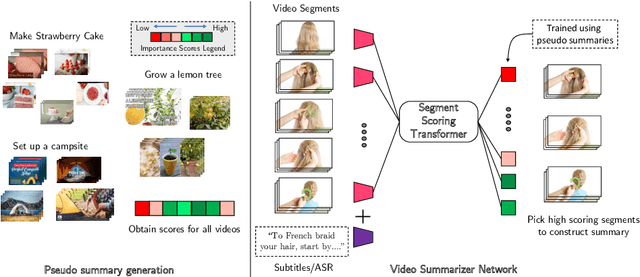
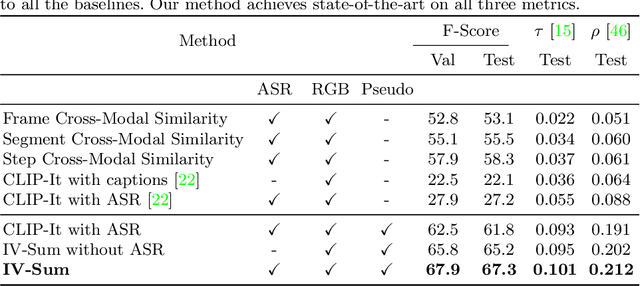
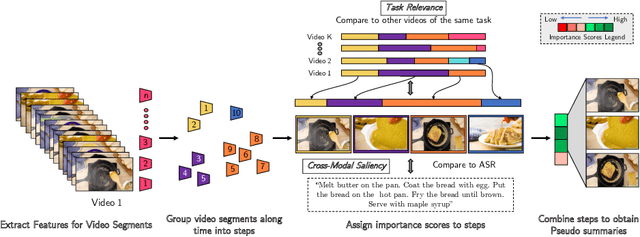
YouTube users looking for instructions for a specific task may spend a long time browsing content trying to find the right video that matches their needs. Creating a visual summary (abridged version of a video) provides viewers with a quick overview and massively reduces search time. In this work, we focus on summarizing instructional videos, an under-explored area of video summarization. In comparison to generic videos, instructional videos can be parsed into semantically meaningful segments that correspond to important steps of the demonstrated task. Existing video summarization datasets rely on manual frame-level annotations, making them subjective and limited in size. To overcome this, we first automatically generate pseudo summaries for a corpus of instructional videos by exploiting two key assumptions: (i) relevant steps are likely to appear in multiple videos of the same task (Task Relevance), and (ii) they are more likely to be described by the demonstrator verbally (Cross-Modal Saliency). We propose an instructional video summarization network that combines a context-aware temporal video encoder and a segment scoring transformer. Using pseudo summaries as weak supervision, our network constructs a visual summary for an instructional video given only video and transcribed speech. To evaluate our model, we collect a high-quality test set, WikiHow Summaries, by scraping WikiHow articles that contain video demonstrations and visual depictions of steps allowing us to obtain the ground-truth summaries. We outperform several baselines and a state-of-the-art video summarization model on this new benchmark.
Structured Video Tokens @ Ego4D PNR Temporal Localization Challenge 2022
Jun 15, 2022


This technical report describes the SViT approach for the Ego4D Point of No Return (PNR) Temporal Localization Challenge. We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a "Frame-Clip Consistency" loss, which ensures the flow of structured information between images and videos. SViT obtains strong performance on the challenge test set with 0.656 absolute temporal localization error.
Bringing Image Scene Structure to Video via Frame-Clip Consistency of Object Tokens
Jun 15, 2022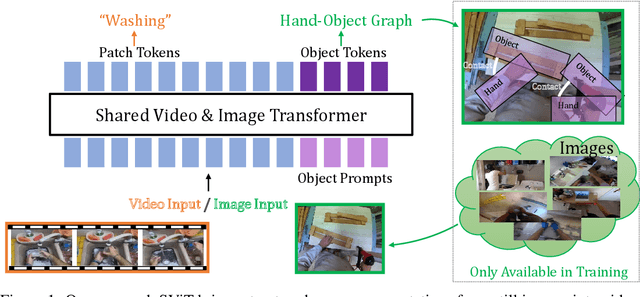
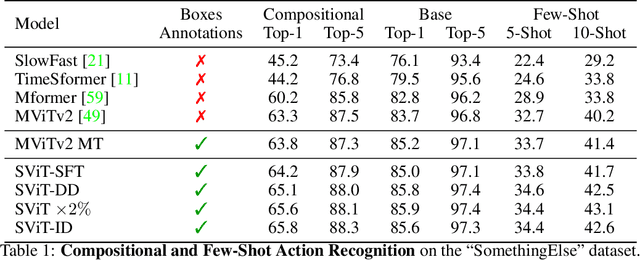
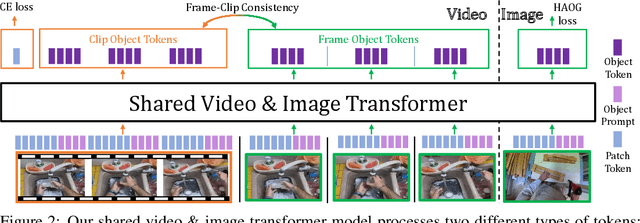
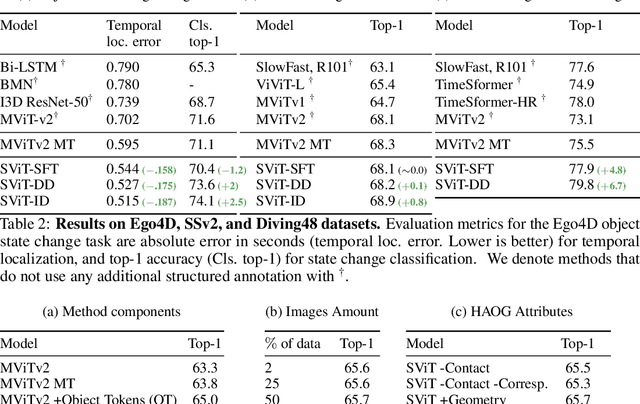
Recent action recognition models have achieved impressive results by integrating objects, their locations and interactions. However, obtaining dense structured annotations for each frame is tedious and time-consuming, making these methods expensive to train and less scalable. At the same time, if a small set of annotated images is available, either within or outside the domain of interest, how could we leverage these for a video downstream task? We propose a learning framework StructureViT (SViT for short), which demonstrates how utilizing the structure of a small number of images only available during training can improve a video model. SViT relies on two key insights. First, as both images and videos contain structured information, we enrich a transformer model with a set of \emph{object tokens} that can be used across images and videos. Second, the scene representations of individual frames in video should "align" with those of still images. This is achieved via a \emph{Frame-Clip Consistency} loss, which ensures the flow of structured information between images and videos. We explore a particular instantiation of scene structure, namely a \emph{Hand-Object Graph}, consisting of hands and objects with their locations as nodes, and physical relations of contact/no-contact as edges. SViT shows strong performance improvements on multiple video understanding tasks and datasets. Furthermore, it won in the Ego4D CVPR'22 Object State Localization challenge. For code and pretrained models, visit the project page at \url{https://eladb3.github.io/SViT/}
Reliable Visual Question Answering: Abstain Rather Than Answer Incorrectly
Apr 28, 2022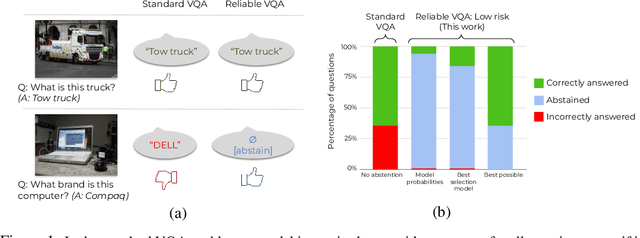
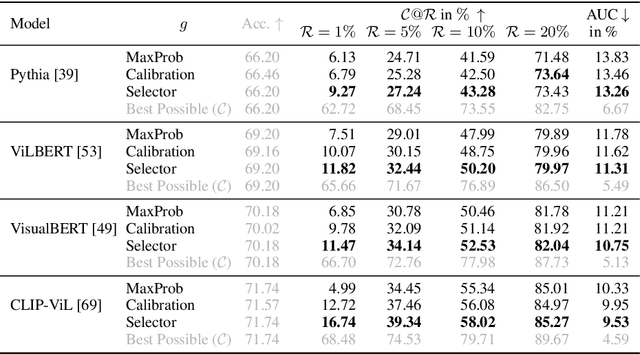


Machine learning has advanced dramatically, narrowing the accuracy gap to humans in multimodal tasks like visual question answering (VQA). However, while humans can say "I don't know" when they are uncertain (i.e., abstain from answering a question), such ability has been largely neglected in multimodal research, despite the importance of this problem to the usage of VQA in real settings. In this work, we promote a problem formulation for reliable VQA, where we prefer abstention over providing an incorrect answer. We first enable abstention capabilities for several VQA models, and analyze both their coverage, the portion of questions answered, and risk, the error on that portion. For that we explore several abstention approaches. We find that although the best performing models achieve over 71% accuracy on the VQA v2 dataset, introducing the option to abstain by directly using a model's softmax scores limits them to answering less than 8% of the questions to achieve a low risk of error (i.e., 1%). This motivates us to utilize a multimodal selection function to directly estimate the correctness of the predicted answers, which we show can triple the coverage from, for example, 5.0% to 16.7% at 1% risk. While it is important to analyze both coverage and risk, these metrics have a trade-off which makes comparing VQA models challenging. To address this, we also propose an Effective Reliability metric for VQA that places a larger cost on incorrect answers compared to abstentions. This new problem formulation, metric, and analysis for VQA provide the groundwork for building effective and reliable VQA models that have the self-awareness to abstain if and only if they don't know the answer.
K-LITE: Learning Transferable Visual Models with External Knowledge
Apr 20, 2022
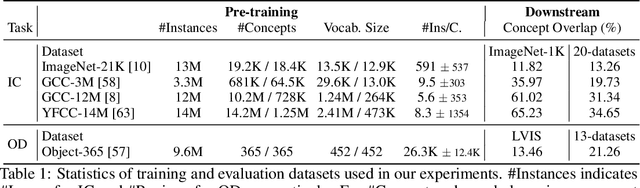
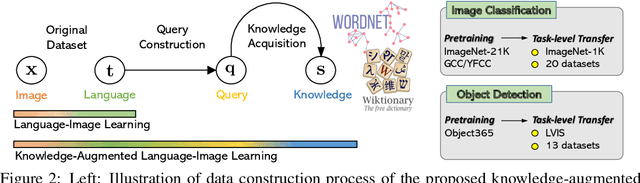
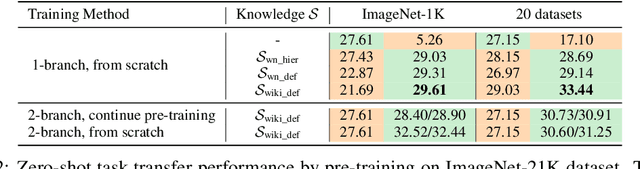
Recent state-of-the-art computer vision systems are trained from natural language supervision, ranging from simple object category names to descriptive captions. This free form of supervision ensures high generality and usability of the learned visual models, based on extensive heuristics on data collection to cover as many visual concepts as possible. Alternatively, learning with external knowledge about images is a promising way which leverages a much more structured source of supervision. In this paper, we propose K-LITE (Knowledge-augmented Language-Image Training and Evaluation), a simple strategy to leverage external knowledge to build transferable visual systems: In training, it enriches entities in natural language with WordNet and Wiktionary knowledge, leading to an efficient and scalable approach to learning image representations that can understand both visual concepts and their knowledge; In evaluation, the natural language is also augmented with external knowledge and then used to reference learned visual concepts (or describe new ones) to enable zero-shot and few-shot transfer of the pre-trained models. We study the performance of K-LITE on two important computer vision problems, image classification and object detection, benchmarking on 20 and 13 different existing datasets, respectively. The proposed knowledge-augmented models show significant improvement in transfer learning performance over existing methods.
ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
Apr 12, 2022
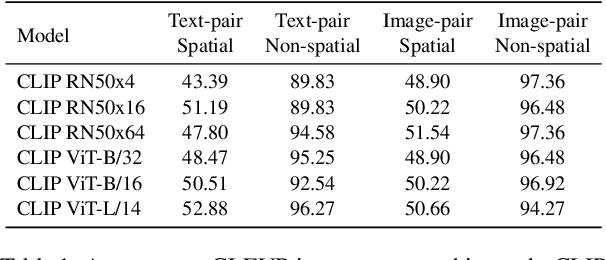
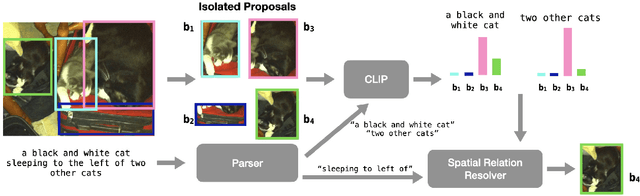
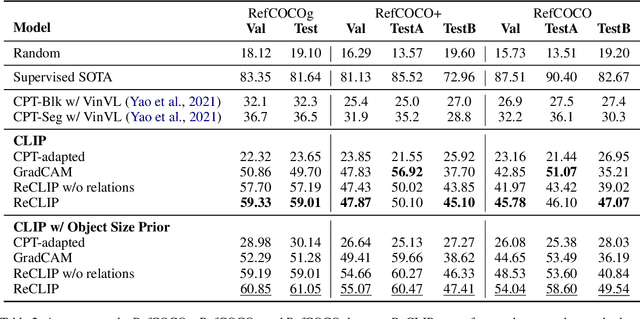
Training a referring expression comprehension (ReC) model for a new visual domain requires collecting referring expressions, and potentially corresponding bounding boxes, for images in the domain. While large-scale pre-trained models are useful for image classification across domains, it remains unclear if they can be applied in a zero-shot manner to more complex tasks like ReC. We present ReCLIP, a simple but strong zero-shot baseline that repurposes CLIP, a state-of-the-art large-scale model, for ReC. Motivated by the close connection between ReC and CLIP's contrastive pre-training objective, the first component of ReCLIP is a region-scoring method that isolates object proposals via cropping and blurring, and passes them to CLIP. However, through controlled experiments on a synthetic dataset, we find that CLIP is largely incapable of performing spatial reasoning off-the-shelf. Thus, the second component of ReCLIP is a spatial relation resolver that handles several types of spatial relations. We reduce the gap between zero-shot baselines from prior work and supervised models by as much as 29% on RefCOCOg, and on RefGTA (video game imagery), ReCLIP's relative improvement over supervised ReC models trained on real images is 8%.