 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoPresent: Designing Structured Visuals from Scratch
Jan 01, 2025



Designing structured visuals such as presentation slides is essential for communicative needs, necessitating both content creation and visual planning skills. In this work, we tackle the challenge of automated slide generation, where models produce slide presentations from natural language (NL) instructions. We first introduce the SlidesBench benchmark, the first benchmark for slide generation with 7k training and 585 testing examples derived from 310 slide decks across 10 domains. SlidesBench supports evaluations that are (i)reference-based to measure similarity to a target slide, and (ii)reference-free to measure the design quality of generated slides alone. We benchmark end-to-end image generation and program generation methods with a variety of models, and find that programmatic methods produce higher-quality slides in user-interactable formats. Built on the success of program generation, we create AutoPresent, an 8B Llama-based model trained on 7k pairs of instructions paired with code for slide generation, and achieve results comparable to the closed-source model GPT-4o. We further explore iterative design refinement where the model is tasked to self-refine its own output, and we found that this process improves the slide's quality. We hope that our work will provide a basis for future work on generating structured visuals.
Using Language Models to Disambiguate Lexical Choices in Translation
Nov 08, 2024



In translation, a concept represented by a single word in a source language can have multiple variations in a target language. The task of lexical selection requires using context to identify which variation is most appropriate for a source text. We work with native speakers of nine languages to create DTAiLS, a dataset of 1,377 sentence pairs that exhibit cross-lingual concept variation when translating from English. We evaluate recent LLMs and neural machine translation systems on DTAiLS, with the best-performing model, GPT-4, achieving from 67 to 85% accuracy across languages. Finally, we use language models to generate English rules describing target-language concept variations. Providing weaker models with high-quality lexical rules improves accuracy substantially, in some cases reaching or outperforming GPT-4.
Pose Priors from Language Models
May 06, 2024We present a zero-shot pose optimization method that enforces accurate physical contact constraints when estimating the 3D pose of humans. Our central insight is that since language is often used to describe physical interaction, large pretrained text-based models can act as priors on pose estimation. We can thus leverage this insight to improve pose estimation by converting natural language descriptors, generated by a large multimodal model (LMM), into tractable losses to constrain the 3D pose optimization. Despite its simplicity, our method produces surprisingly compelling pose reconstructions of people in close contact, correctly capturing the semantics of the social and physical interactions. We demonstrate that our method rivals more complex state-of-the-art approaches that require expensive human annotation of contact points and training specialized models. Moreover, unlike previous approaches, our method provides a unified framework for resolving self-contact and person-to-person contact.
TraveLER: A Multi-LMM Agent Framework for Video Question-Answering
Apr 01, 2024



Recently, Large Multimodal Models (LMMs) have made significant progress in video question-answering using a frame-wise approach by leveraging large-scale, image-based pretraining in a zero-shot manner. While image-based methods for videos have shown impressive performance, a current limitation is that they often overlook how key timestamps are selected and cannot adjust when incorrect timestamps are identified. Moreover, they are unable to extract details relevant to the question, instead providing general descriptions of the frame. To overcome this, we design a multi-LMM agent framework that travels along the video, iteratively collecting relevant information from keyframes through interactive question-asking until there is sufficient information to answer the question. Specifically, we propose TraveLER, a model that can create a plan to "Traverse" through the video, ask questions about individual frames to "Locate" and store key information, and then "Evaluate" if there is enough information to answer the question. Finally, if there is not enough information, our method is able to "Replan" based on its collected knowledge. Through extensive experiments, we find that the proposed TraveLER approach improves performance on several video question-answering benchmarks, such as NExT-QA, STAR, and Perception Test, without the need to fine-tune on specific datasets.
Recursive Visual Programming
Dec 04, 2023



Visual Programming (VP) has emerged as a powerful framework for Visual Question Answering (VQA). By generating and executing bespoke code for each question, these methods demonstrate impressive compositional and reasoning capabilities, especially in few-shot and zero-shot scenarios. However, existing VP methods generate all code in a single function, resulting in code that is suboptimal in terms of both accuracy and interpretability. Inspired by human coding practices, we propose Recursive Visual Programming (RVP), which simplifies generated routines, provides more efficient problem solving, and can manage more complex data structures. RVP is inspired by human coding practices and approaches VQA tasks with an iterative recursive code generation approach, allowing decomposition of complicated problems into smaller parts. Notably, RVP is capable of dynamic type assignment, i.e., as the system recursively generates a new piece of code, it autonomously determines the appropriate return type and crafts the requisite code to generate that output. We show RVP's efficacy through extensive experiments on benchmarks including VSR, COVR, GQA, and NextQA, underscoring the value of adopting human-like recursive and modular programming techniques for solving VQA tasks through coding.
From Wrong To Right: A Recursive Approach Towards Vision-Language Explanation
Nov 21, 2023



Addressing the challenge of adapting pre-trained vision-language models for generating insightful explanations for visual reasoning tasks with limited annotations, we present ReVisE: a $\textbf{Re}$cursive $\textbf{Vis}$ual $\textbf{E}$xplanation algorithm. Our method iteratively computes visual features (conditioned on the text input), an answer, and an explanation, to improve the explanation quality step by step until the answer converges. We find that this multi-step approach guides the model to correct its own answers and outperforms single-step explanation generation. Furthermore, explanations generated by ReVisE also serve as valuable annotations for few-shot self-training. Our approach outperforms previous methods while utilizing merely 5% of the human-annotated explanations across 10 metrics, demonstrating up to a 4.2 and 1.3 increase in BLEU-1 score on the VCR and VQA-X datasets, underscoring the efficacy and data-efficiency of our method.
Can Language Models Learn to Listen?
Aug 21, 2023



We present a framework for generating appropriate facial responses from a listener in dyadic social interactions based on the speaker's words. Given an input transcription of the speaker's words with their timestamps, our approach autoregressively predicts a response of a listener: a sequence of listener facial gestures, quantized using a VQ-VAE. Since gesture is a language component, we propose treating the quantized atomic motion elements as additional language token inputs to a transformer-based large language model. Initializing our transformer with the weights of a language model pre-trained only on text results in significantly higher quality listener responses than training a transformer from scratch. We show that our generated listener motion is fluent and reflective of language semantics through quantitative metrics and a qualitative user study. In our evaluation, we analyze the model's ability to utilize temporal and semantic aspects of spoken text. Project page: https://people.eecs.berkeley.edu/~evonne_ng/projects/text2listen/
Modular Visual Question Answering via Code Generation
Jun 08, 2023We present a framework that formulates visual question answering as modular code generation. In contrast to prior work on modular approaches to VQA, our approach requires no additional training and relies on pre-trained language models (LMs), visual models pre-trained on image-caption pairs, and fifty VQA examples used for in-context learning. The generated Python programs invoke and compose the outputs of the visual models using arithmetic and conditional logic. Our approach improves accuracy on the COVR dataset by at least 3% and on the GQA dataset by roughly 2% compared to the few-shot baseline that does not employ code generation.
ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
Apr 12, 2022
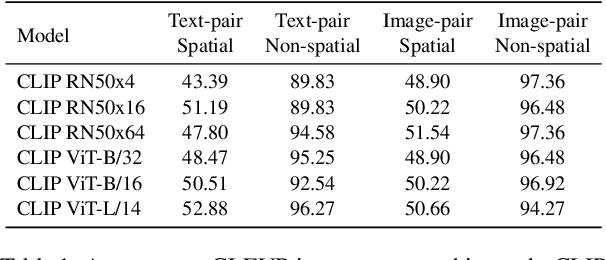
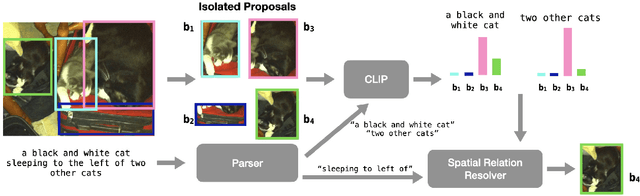
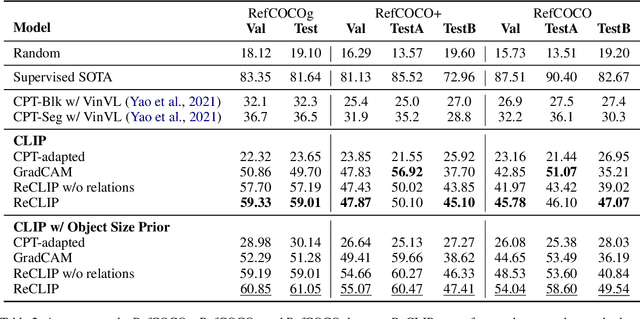
Training a referring expression comprehension (ReC) model for a new visual domain requires collecting referring expressions, and potentially corresponding bounding boxes, for images in the domain. While large-scale pre-trained models are useful for image classification across domains, it remains unclear if they can be applied in a zero-shot manner to more complex tasks like ReC. We present ReCLIP, a simple but strong zero-shot baseline that repurposes CLIP, a state-of-the-art large-scale model, for ReC. Motivated by the close connection between ReC and CLIP's contrastive pre-training objective, the first component of ReCLIP is a region-scoring method that isolates object proposals via cropping and blurring, and passes them to CLIP. However, through controlled experiments on a synthetic dataset, we find that CLIP is largely incapable of performing spatial reasoning off-the-shelf. Thus, the second component of ReCLIP is a spatial relation resolver that handles several types of spatial relations. We reduce the gap between zero-shot baselines from prior work and supervised models by as much as 29% on RefCOCOg, and on RefGTA (video game imagery), ReCLIP's relative improvement over supervised ReC models trained on real images is 8%.
MedICaT: A Dataset of Medical Images, Captions, and Textual References
Oct 12, 2020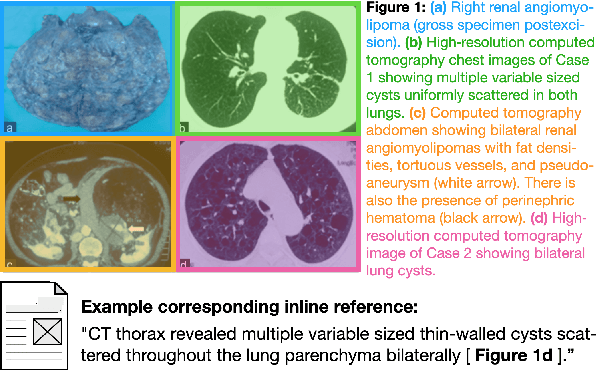

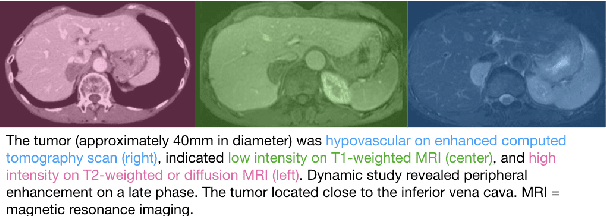
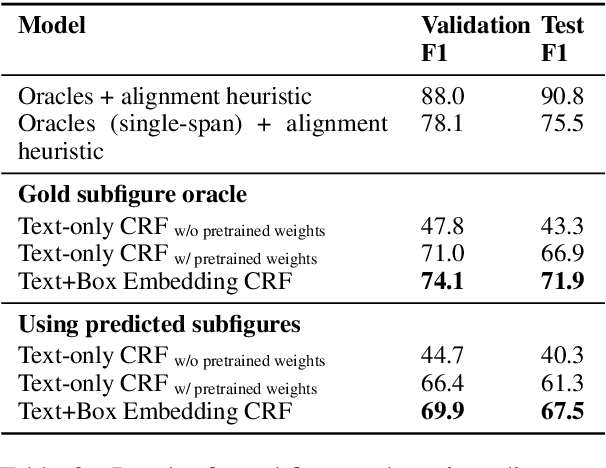
Understanding the relationship between figures and text is key to scientific document understanding. Medical figures in particular are quite complex, often consisting of several subfigures (75% of figures in our dataset), with detailed text describing their content. Previous work studying figures in scientific papers focused on classifying figure content rather than understanding how images relate to the text. To address challenges in figure retrieval and figure-to-text alignment, we introduce MedICaT, a dataset of medical images in context. MedICaT consists of 217K images from 131K open access biomedical papers, and includes captions, inline references for 74% of figures, and manually annotated subfigures and subcaptions for a subset of figures. Using MedICaT, we introduce the task of subfigure to subcaption alignment in compound figures and demonstrate the utility of inline references in image-text matching. Our data and code can be accessed at https://github.com/allenai/medicat.