 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Imitation Enables Contextual Humanoid Control
May 07, 2025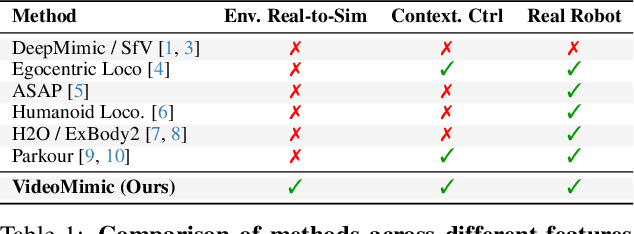
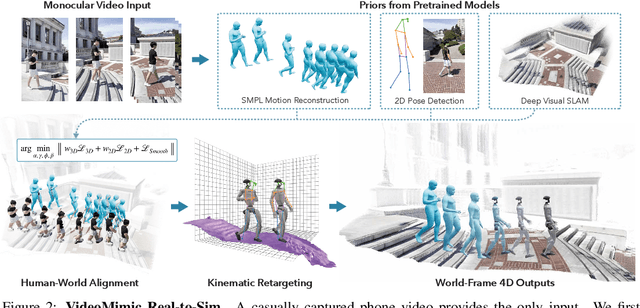


How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.
PyRoki: A Modular Toolkit for Robot Kinematic Optimization
May 06, 2025



Robot motion can have many goals. Depending on the task, we might optimize for pose error, speed, collision, or similarity to a human demonstration. Motivated by this, we present PyRoki: a modular, extensible, and cross-platform toolkit for solving kinematic optimization problems. PyRoki couples an interface for specifying kinematic variables and costs with an efficient nonlinear least squares optimizer. Unlike existing tools, it is also cross-platform: optimization runs natively on CPU, GPU, and TPU. In this paper, we present (i) the design and implementation of PyRoki, (ii) motion retargeting and planning case studies that highlight the advantages of PyRoki's modularity, and (iii) optimization benchmarking, where PyRoki can be 1.4-1.7x faster and converges to lower errors than cuRobo, an existing GPU-accelerated inverse kinematics library.
Predict-Optimize-Distill: A Self-Improving Cycle for 4D Object Understanding
Apr 24, 2025Humans can resort to long-form inspection to build intuition on predicting the 3D configurations of unseen objects. The more we observe the object motion, the better we get at predicting its 3D state immediately. Existing systems either optimize underlying representations from multi-view observations or train a feed-forward predictor from supervised datasets. We introduce Predict-Optimize-Distill (POD), a self-improving framework that interleaves prediction and optimization in a mutually reinforcing cycle to achieve better 4D object understanding with increasing observation time. Given a multi-view object scan and a long-form monocular video of human-object interaction, POD iteratively trains a neural network to predict local part poses from RGB frames, uses this predictor to initialize a global optimization which refines output poses through inverse rendering, then finally distills the results of optimization back into the model by generating synthetic self-labeled training data from novel viewpoints. Each iteration improves both the predictive model and the optimized motion trajectory, creating a virtuous cycle that bootstraps its own training data to learn about the pose configurations of an object. We also introduce a quasi-multiview mining strategy for reducing depth ambiguity by leveraging long video. We evaluate POD on 14 real-world and 5 synthetic objects with various joint types, including revolute and prismatic joints as well as multi-body configurations where parts detach or reattach independently. POD demonstrates significant improvement over a pure optimization baseline which gets stuck in local minima, particularly for longer videos. We also find that POD's performance improves with both video length and successive iterations of the self-improving cycle, highlighting its ability to scale performance with additional observations and looped refinement.
St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
Apr 17, 2025



Dynamic 3D reconstruction and point tracking in videos are typically treated as separate tasks, despite their deep connection. We propose St4RTrack, a feed-forward framework that simultaneously reconstructs and tracks dynamic video content in a world coordinate frame from RGB inputs. This is achieved by predicting two appropriately defined pointmaps for a pair of frames captured at different moments. Specifically, we predict both pointmaps at the same moment, in the same world, capturing both static and dynamic scene geometry while maintaining 3D correspondences. Chaining these predictions through the video sequence with respect to a reference frame naturally computes long-range correspondences, effectively combining 3D reconstruction with 3D tracking. Unlike prior methods that rely heavily on 4D ground truth supervision, we employ a novel adaptation scheme based on a reprojection loss. We establish a new extensive benchmark for world-frame reconstruction and tracking, demonstrating the effectiveness and efficiency of our unified, data-driven framework. Our code, model, and benchmark will be released.
Segment Any Motion in Videos
Mar 28, 2025Moving object segmentation is a crucial task for achieving a high-level understanding of visual scenes and has numerous downstream applications. Humans can effortlessly segment moving objects in videos. Previous work has largely relied on optical flow to provide motion cues; however, this approach often results in imperfect predictions due to challenges such as partial motion, complex deformations, motion blur and background distractions. We propose a novel approach for moving object segmentation that combines long-range trajectory motion cues with DINO-based semantic features and leverages SAM2 for pixel-level mask densification through an iterative prompting strategy. Our model employs Spatio-Temporal Trajectory Attention and Motion-Semantic Decoupled Embedding to prioritize motion while integrating semantic support. Extensive testing on diverse datasets demonstrates state-of-the-art performance, excelling in challenging scenarios and fine-grained segmentation of multiple objects. Our code is available at https://motion-seg.github.io/.
Fillerbuster: Multi-View Scene Completion for Casual Captures
Feb 07, 2025
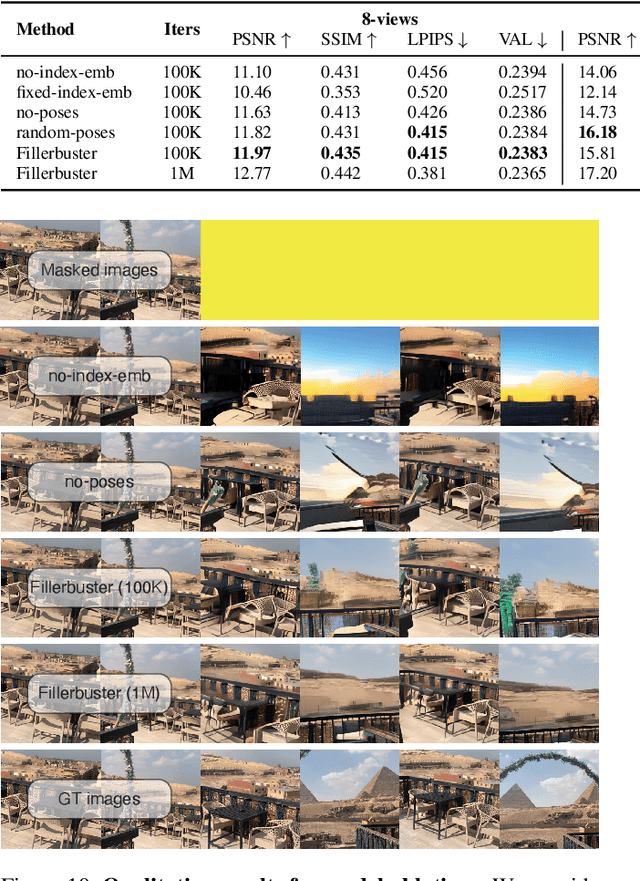
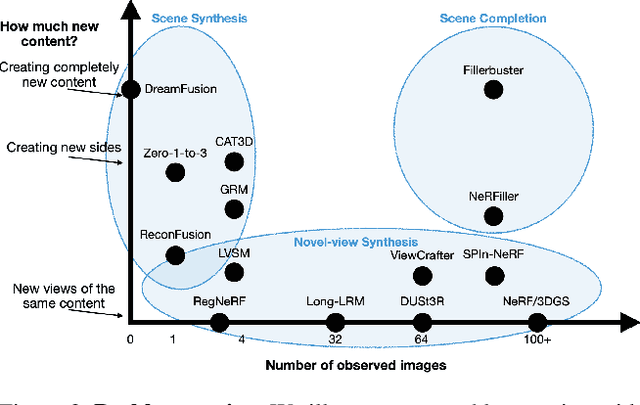

We present Fillerbuster, a method that completes unknown regions of a 3D scene by utilizing a novel large-scale multi-view latent diffusion transformer. Casual captures are often sparse and miss surrounding content behind objects or above the scene. Existing methods are not suitable for handling this challenge as they focus on making the known pixels look good with sparse-view priors, or on creating the missing sides of objects from just one or two photos. In reality, we often have hundreds of input frames and want to complete areas that are missing and unobserved from the input frames. Additionally, the images often do not have known camera parameters. Our solution is to train a generative model that can consume a large context of input frames while generating unknown target views and recovering image poses when desired. We show results where we complete partial captures on two existing datasets. We also present an uncalibrated scene completion task where our unified model predicts both poses and creates new content. Our model is the first to predict many images and poses together for scene completion.
Continuous 3D Perception Model with Persistent State
Jan 21, 2025We present a unified framework capable of solving a broad range of 3D tasks. Our approach features a stateful recurrent model that continuously updates its state representation with each new observation. Given a stream of images, this evolving state can be used to generate metric-scale pointmaps (per-pixel 3D points) for each new input in an online fashion. These pointmaps reside within a common coordinate system, and can be accumulated into a coherent, dense scene reconstruction that updates as new images arrive. Our model, called CUT3R (Continuous Updating Transformer for 3D Reconstruction), captures rich priors of real-world scenes: not only can it predict accurate pointmaps from image observations, but it can also infer unseen regions of the scene by probing at virtual, unobserved views. Our method is simple yet highly flexible, naturally accepting varying lengths of images that may be either video streams or unordered photo collections, containing both static and dynamic content. We evaluate our method on various 3D/4D tasks and demonstrate competitive or state-of-the-art performance in each. Project Page: https://cut3r.github.io/
Decentralized Diffusion Models
Jan 10, 2025Large-scale AI model training divides work across thousands of GPUs, then synchronizes gradients across them at each step. This incurs a significant network burden that only centralized, monolithic clusters can support, driving up infrastructure costs and straining power systems. We propose Decentralized Diffusion Models, a scalable framework for distributing diffusion model training across independent clusters or datacenters by eliminating the dependence on a centralized, high-bandwidth networking fabric. Our method trains a set of expert diffusion models over partitions of the dataset, each in full isolation from one another. At inference time, the experts ensemble through a lightweight router. We show that the ensemble collectively optimizes the same objective as a single model trained over the whole dataset. This means we can divide the training burden among a number of "compute islands," lowering infrastructure costs and improving resilience to localized GPU failures. Decentralized diffusion models empower researchers to take advantage of smaller, more cost-effective and more readily available compute like on-demand GPU nodes rather than central integrated systems. We conduct extensive experiments on ImageNet and LAION Aesthetics, showing that decentralized diffusion models FLOP-for-FLOP outperform standard diffusion models. We finally scale our approach to 24 billion parameters, demonstrating that high-quality diffusion models can now be trained with just eight individual GPU nodes in less than a week.
Reconstructing People, Places, and Cameras
Dec 23, 2024



We present "Humans and Structure from Motion" (HSfM), a method for jointly reconstructing multiple human meshes, scene point clouds, and camera parameters in a metric world coordinate system from a sparse set of uncalibrated multi-view images featuring people. Our approach combines data-driven scene reconstruction with the traditional Structure-from-Motion (SfM) framework to achieve more accurate scene reconstruction and camera estimation, while simultaneously recovering human meshes. In contrast to existing scene reconstruction and SfM methods that lack metric scale information, our method estimates approximate metric scale by leveraging a human statistical model. Furthermore, it reconstructs multiple human meshes within the same world coordinate system alongside the scene point cloud, effectively capturing spatial relationships among individuals and their positions in the environment. We initialize the reconstruction of humans, scenes, and cameras using robust foundational models and jointly optimize these elements. This joint optimization synergistically improves the accuracy of each component. We compare our method to existing approaches on two challenging benchmarks, EgoHumans and EgoExo4D, demonstrating significant improvements in human localization accuracy within the world coordinate frame (reducing error from 3.51m to 1.04m in EgoHumans and from 2.9m to 0.56m in EgoExo4D). Notably, our results show that incorporating human data into the SfM pipeline improves camera pose estimation (e.g., increasing RRA@15 by 20.3% on EgoHumans). Additionally, qualitative results show that our approach improves overall scene reconstruction quality. Our code is available at: muelea.github.io/hsfm.
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
Dec 05, 2024



We present a system that allows for accurate, fast, and robust estimation of camera parameters and depth maps from casual monocular videos of dynamic scenes. Most conventional structure from motion and monocular SLAM techniques assume input videos that feature predominantly static scenes with large amounts of parallax. Such methods tend to produce erroneous estimates in the absence of these conditions. Recent neural network-based approaches attempt to overcome these challenges; however, such methods are either computationally expensive or brittle when run on dynamic videos with uncontrolled camera motion or unknown field of view. We demonstrate the surprising effectiveness of a deep visual SLAM framework: with careful modifications to its training and inference schemes, this system can scale to real-world videos of complex dynamic scenes with unconstrained camera paths, including videos with little camera parallax. Extensive experiments on both synthetic and real videos demonstrate that our system is significantly more accurate and robust at camera pose and depth estimation when compared with prior and concurrent work, with faster or comparable running times. See interactive results on our project page: https://mega-sam.github.io/