 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
Dec 05, 2024



We present a system that allows for accurate, fast, and robust estimation of camera parameters and depth maps from casual monocular videos of dynamic scenes. Most conventional structure from motion and monocular SLAM techniques assume input videos that feature predominantly static scenes with large amounts of parallax. Such methods tend to produce erroneous estimates in the absence of these conditions. Recent neural network-based approaches attempt to overcome these challenges; however, such methods are either computationally expensive or brittle when run on dynamic videos with uncontrolled camera motion or unknown field of view. We demonstrate the surprising effectiveness of a deep visual SLAM framework: with careful modifications to its training and inference schemes, this system can scale to real-world videos of complex dynamic scenes with unconstrained camera paths, including videos with little camera parallax. Extensive experiments on both synthetic and real videos demonstrate that our system is significantly more accurate and robust at camera pose and depth estimation when compared with prior and concurrent work, with faster or comparable running times. See interactive results on our project page: https://mega-sam.github.io/
Estimating Body and Hand Motion in an Ego-sensed World
Oct 04, 2024



We present EgoAllo, a system for human motion estimation from a head-mounted device. Using only egocentric SLAM poses and images, EgoAllo guides sampling from a conditional diffusion model to estimate 3D body pose, height, and hand parameters that capture the wearer's actions in the allocentric coordinate frame of the scene. To achieve this, our key insight is in representation: we propose spatial and temporal invariance criteria for improving model performance, from which we derive a head motion conditioning parameterization that improves estimation by up to 18%. We also show how the bodies estimated by our system can improve the hands: the resulting kinematic and temporal constraints result in over 40% lower hand estimation errors compared to noisy monocular estimates. Project page: https://egoallo.github.io/
gsplat: An Open-Source Library for Gaussian Splatting
Sep 10, 2024gsplat is an open-source library designed for training and developing Gaussian Splatting methods. It features a front-end with Python bindings compatible with the PyTorch library and a back-end with highly optimized CUDA kernels. gsplat offers numerous features that enhance the optimization of Gaussian Splatting models, which include optimization improvements for speed, memory, and convergence times. Experimental results demonstrate that gsplat achieves up to 10% less training time and 4x less memory than the original implementation. Utilized in several research projects, gsplat is actively maintained on GitHub. Source code is available at https://github.com/nerfstudio-project/gsplat under Apache License 2.0. We welcome contributions from the open-source community.
Shape of Motion: 4D Reconstruction from a Single Video
Jul 18, 2024



Monocular dynamic reconstruction is a challenging and long-standing vision problem due to the highly ill-posed nature of the task. Existing approaches are limited in that they either depend on templates, are effective only in quasi-static scenes, or fail to model 3D motion explicitly. In this work, we introduce a method capable of reconstructing generic dynamic scenes, featuring explicit, full-sequence-long 3D motion, from casually captured monocular videos. We tackle the under-constrained nature of the problem with two key insights: First, we exploit the low-dimensional structure of 3D motion by representing scene motion with a compact set of SE3 motion bases. Each point's motion is expressed as a linear combination of these bases, facilitating soft decomposition of the scene into multiple rigidly-moving groups. Second, we utilize a comprehensive set of data-driven priors, including monocular depth maps and long-range 2D tracks, and devise a method to effectively consolidate these noisy supervisory signals, resulting in a globally consistent representation of the dynamic scene. Experiments show that our method achieves state-of-the-art performance for both long-range 3D/2D motion estimation and novel view synthesis on dynamic scenes. Project Page: https://shape-of-motion.github.io/
Mathematical Supplement for the $\texttt{gsplat}$ Library
Dec 04, 2023This report provides the mathematical details of the gsplat library, a modular toolbox for efficient differentiable Gaussian splatting, as proposed by Kerbl et al. It provides a self-contained reference for the computations involved in the forward and backward passes of differentiable Gaussian splatting. To facilitate practical usage and development, we provide a user friendly Python API that exposes each component of the forward and backward passes in rasterization at github.com/nerfstudio-project/gsplat .
Generative Proxemics: A Prior for 3D Social Interaction from Images
Jun 15, 2023Social interaction is a fundamental aspect of human behavior and communication. The way individuals position themselves in relation to others, also known as proxemics, conveys social cues and affects the dynamics of social interaction. We present a novel approach that learns a 3D proxemics prior of two people in close social interaction. Since collecting a large 3D dataset of interacting people is a challenge, we rely on 2D image collections where social interactions are abundant. We achieve this by reconstructing pseudo-ground truth 3D meshes of interacting people from images with an optimization approach using existing ground-truth contact maps. We then model the proxemics using a novel denoising diffusion model called BUDDI that learns the joint distribution of two people in close social interaction directly in the SMPL-X parameter space. Sampling from our generative proxemics model produces realistic 3D human interactions, which we validate through a user study. Additionally, we introduce a new optimization method that uses the diffusion prior to reconstruct two people in close proximity from a single image without any contact annotation. Our approach recovers more accurate and plausible 3D social interactions from noisy initial estimates and outperforms state-of-the-art methods. See our project site for code, data, and model: muelea.github.io/buddi.
Decoupling Human and Camera Motion from Videos in the Wild
Mar 20, 2023



We propose a method to reconstruct global human trajectories from videos in the wild. Our optimization method decouples the camera and human motion, which allows us to place people in the same world coordinate frame. Most existing methods do not model the camera motion; methods that rely on the background pixels to infer 3D human motion usually require a full scene reconstruction, which is often not possible for in-the-wild videos. However, even when existing SLAM systems cannot recover accurate scene reconstructions, the background pixel motion still provides enough signal to constrain the camera motion. We show that relative camera estimates along with data-driven human motion priors can resolve the scene scale ambiguity and recover global human trajectories. Our method robustly recovers the global 3D trajectories of people in challenging in-the-wild videos, such as PoseTrack. We quantify our improvement over existing methods on 3D human dataset Egobody. We further demonstrate that our recovered camera scale allows us to reason about motion of multiple people in a shared coordinate frame, which improves performance of downstream tracking in PoseTrack. Code and video results can be found at https://vye16.github.io/slahmr.
Deformable Sprites for Unsupervised Video Decomposition
Apr 14, 2022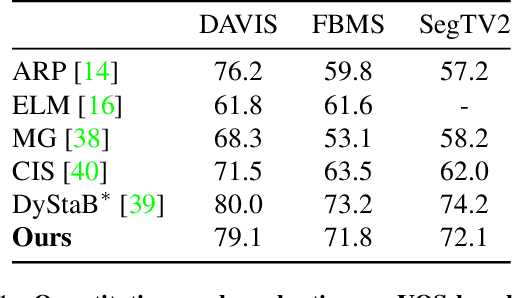
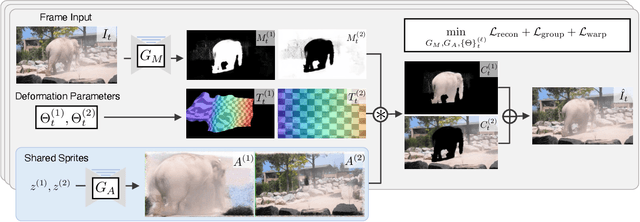


We describe a method to extract persistent elements of a dynamic scene from an input video. We represent each scene element as a \emph{Deformable Sprite} consisting of three components: 1) a 2D texture image for the entire video, 2) per-frame masks for the element, and 3) non-rigid deformations that map the texture image into each video frame. The resulting decomposition allows for applications such as consistent video editing. Deformable Sprites are a type of video auto-encoder model that is optimized on individual videos, and does not require training on a large dataset, nor does it rely on pre-trained models. Moreover, our method does not require object masks or other user input, and discovers moving objects of a wider variety than previous work. We evaluate our approach on standard video datasets and show qualitative results on a diverse array of Internet videos. Code and video results can be found at https://deformable-sprites.github.io
pixelNeRF: Neural Radiance Fields from One or Few Images
Dec 03, 2020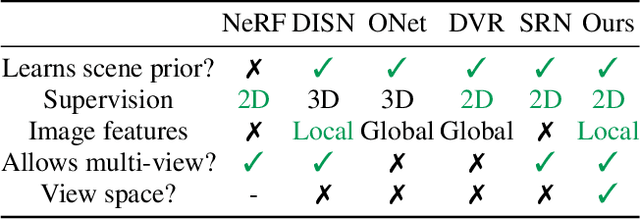
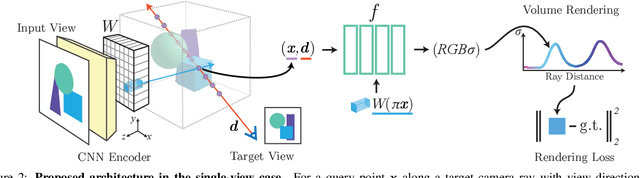
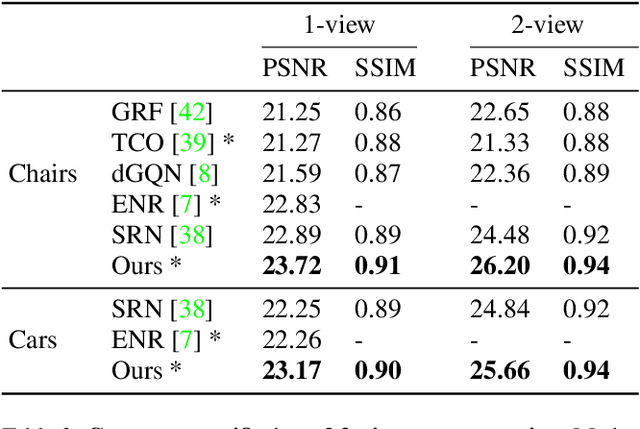

We propose pixelNeRF, a learning framework that predicts a continuous neural scene representation conditioned on one or few input images. The existing approach for constructing neural radiance fields involves optimizing the representation to every scene independently, requiring many calibrated views and significant compute time. We take a step towards resolving these shortcomings by introducing an architecture that conditions a NeRF on image inputs in a fully convolutional manner. This allows the network to be trained across multiple scenes to learn a scene prior, enabling it to perform novel view synthesis in a feed-forward manner from a sparse set of views (as few as one). Leveraging the volume rendering approach of NeRF, our model can be trained directly from images with no explicit 3D supervision. We conduct extensive experiments on ShapeNet benchmarks for single image novel view synthesis tasks with held-out objects as well as entire unseen categories. We further demonstrate the flexibility of pixelNeRF by demonstrating it on multi-object ShapeNet scenes and real scenes from the DTU dataset. In all cases, pixelNeRF outperforms current state-of-the-art baselines for novel view synthesis and single image 3D reconstruction. For the video and code, please visit the project website: https://alexyu.net/pixelnerf
Robust Guarantees for Perception-Based Control
Jul 08, 2019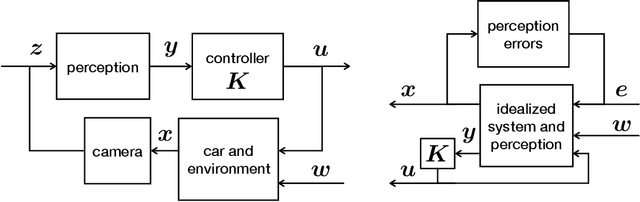

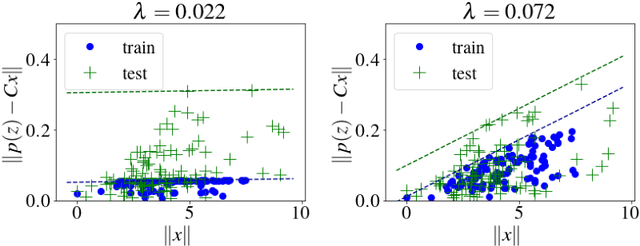

Motivated by vision based control of autonomous vehicles, we consider the problem of controlling a known linear dynamical system for which partial state information, such as vehicle position, can only be extracted from high-dimensional data, such as an image. Our approach is to learn a perception map from high-dimensional data to partial-state observation and its corresponding error profile, and then design a robust controller. We show that under suitable smoothness assumptions on the perception map and generative model relating state to high-dimensional data, an affine error model is sufficiently rich to capture all possible error profiles, and can further be learned via a robust regression problem. We then show how to integrate the learned perception map and error model into a novel robust control synthesis procedure, and prove that the resulting perception and control loop has favorable generalization properties. Finally, we illustrate the usefulness of our approach on a synthetic example and on the self-driving car simulation platform CARLA.