 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisionary: Vision architecture discovery for robot learning
Mar 26, 2021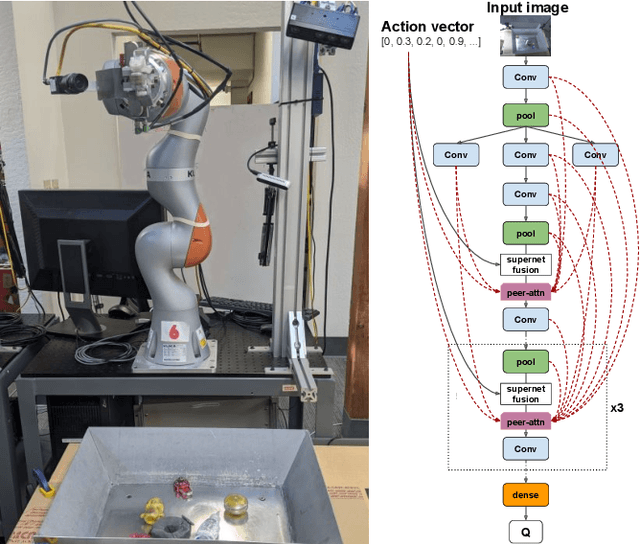
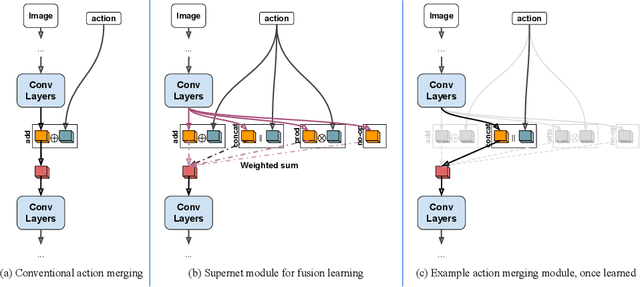
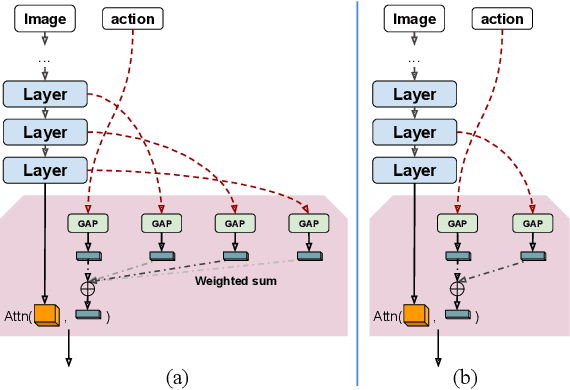
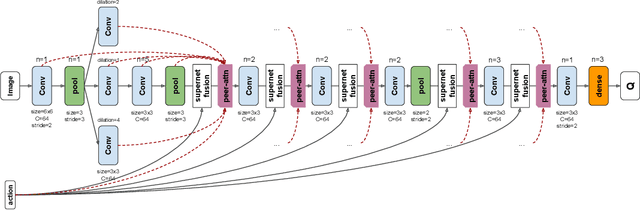
We propose a vision-based architecture search algorithm for robot manipulation learning, which discovers interactions between low dimension action inputs and high dimensional visual inputs. Our approach automatically designs architectures while training on the task - discovering novel ways of combining and attending image feature representations with actions as well as features from previous layers. The obtained new architectures demonstrate better task success rates, in some cases with a large margin, compared to a recent high performing baseline. Our real robot experiments also confirm that it improves grasping performance by 6%. This is the first approach to demonstrate a successful neural architecture search and attention connectivity search for a real-robot task.
Mechanical Search on Shelves using Lateral Access X-RAY
Nov 23, 2020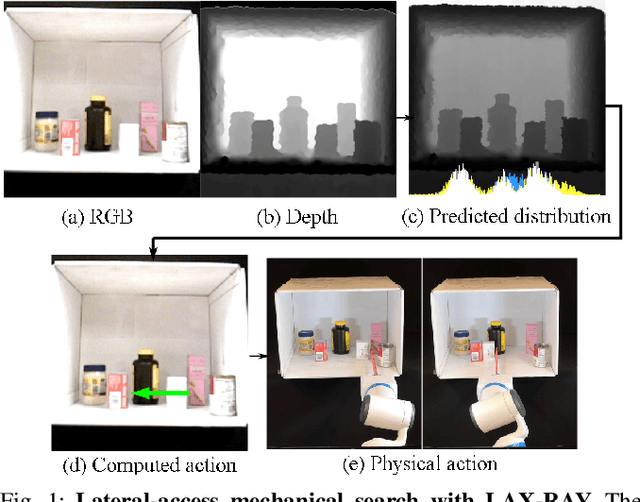



Efficiently finding an occluded object with lateral access arises in many contexts such as warehouses, retail, healthcare, shipping, and homes. We introduce LAX-RAY (Lateral Access maXimal Reduction of occupancY support Area), a system to automate the mechanical search for occluded objects on shelves. For such lateral access environments, LAX-RAY couples a perception pipeline predicting a target object occupancy support distribution with a mechanical search policy that sequentially selects occluding objects to push to the side to reveal the target as efficiently as possible. Within the context of extruded polygonal objects and a stationary target with a known aspect ratio, we explore three lateral access search policies: Distribution Area Reduction (DAR), Distribution Entropy Reduction (DER), and Distribution Entropy Reduction over Multiple Time Steps (DER-MT) utilizing the support distribution and prior information. We evaluate these policies using the First-Order Shelf Simulator (FOSS) in which we simulate 800 random shelf environments of varying difficulty, and in a physical shelf environment with a Fetch robot and an embedded PrimeSense RGBD Camera. Average simulation results of 87.3% success rate demonstrate better performance of DER-MT with 2 prediction steps. When deployed on the robot, results show a success rate of at least 80% for all policies, suggesting that LAX-RAY can efficiently reveal the target object in reality. Both results show significantly better performance of the three proposed policies compared to a baseline policy with uniform probability distribution assumption in non-trivial cases, showing the importance of distribution prediction. Code, videos, and supplementary material can be found at https://sites.google.com/berkeley.edu/lax-ray.
Unsupervised Monocular Depth Learning in Dynamic Scenes
Nov 07, 2020


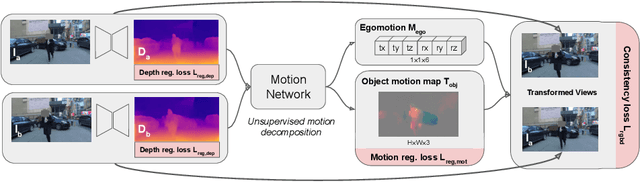
We present a method for jointly training the estimation of depth, ego-motion, and a dense 3D translation field of objects relative to the scene, with monocular photometric consistency being the sole source of supervision. We show that this apparently heavily underdetermined problem can be regularized by imposing the following prior knowledge about 3D translation fields: they are sparse, since most of the scene is static, and they tend to be constant for rigid moving objects. We show that this regularization alone is sufficient to train monocular depth prediction models that exceed the accuracy achieved in prior work for dynamic scenes, including methods that require semantic input. Code is at https://github.com/google-research/google-research/tree/master/depth_and_motion_learning .
AssembleNet++: Assembling Modality Representations via Attention Connections
Aug 18, 2020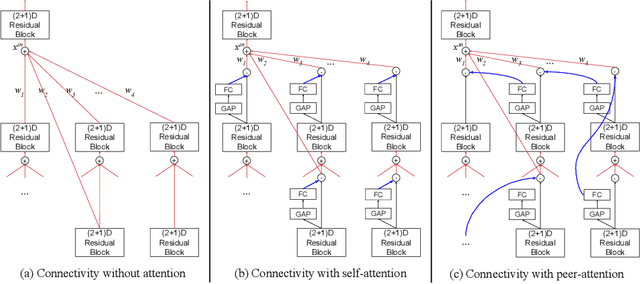
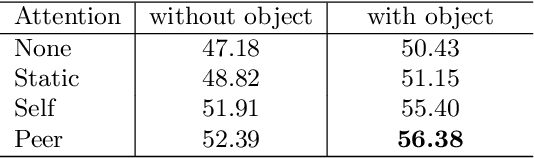
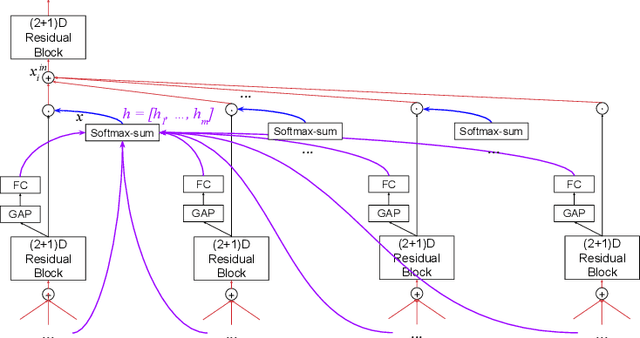
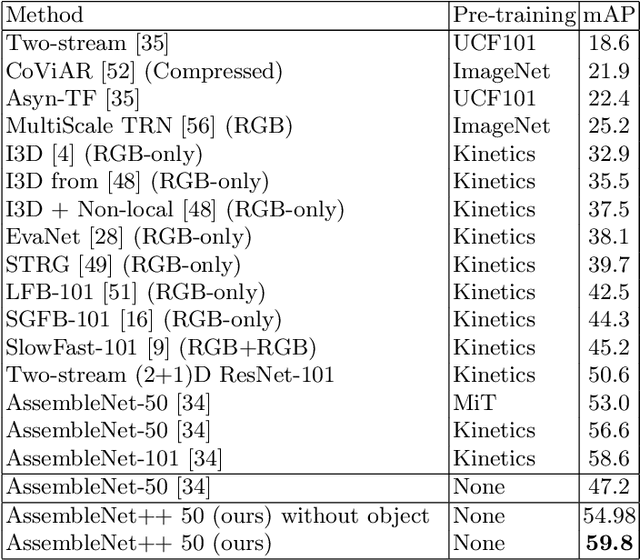
We create a family of powerful video models which are able to: (i) learn interactions between semantic object information and raw appearance and motion features, and (ii) deploy attention in order to better learn the importance of features at each convolutional block of the network. A new network component named peer-attention is introduced, which dynamically learns the attention weights using another block or input modality. Even without pre-training, our models outperform the previous work on standard public activity recognition datasets with continuous videos, establishing new state-of-the-art. We also confirm that our findings of having neural connections from the object modality and the use of peer-attention is generally applicable for different existing architectures, improving their performances. We name our model explicitly as AssembleNet++. The code will be available at: https://sites.google.com/corp/view/assemblenet/
* ECCV 2020 camera-ready version
Adversarial Generative Grammars for Human Activity Prediction
Aug 14, 2020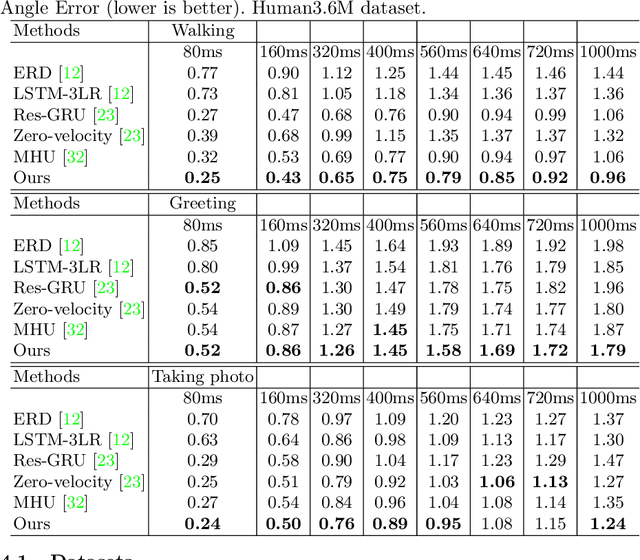
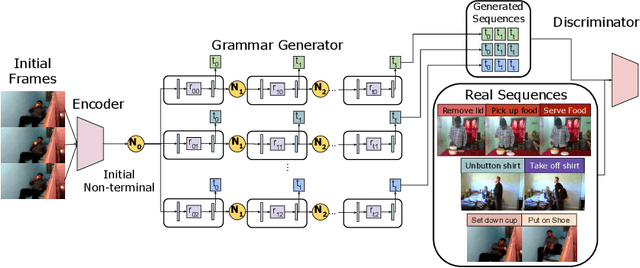
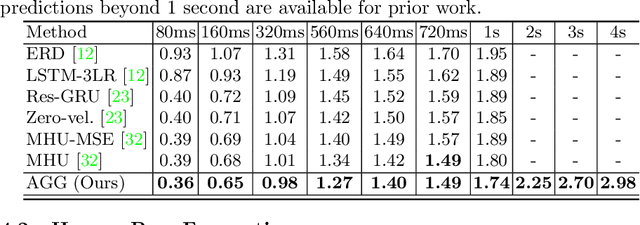
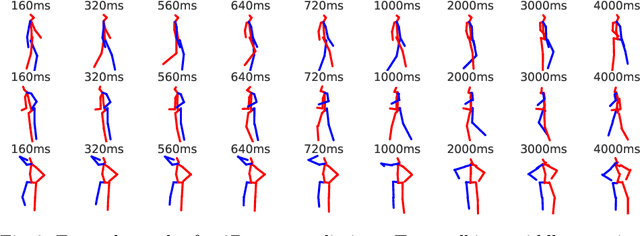
In this paper we propose an adversarial generative grammar model for future prediction. The objective is to learn a model that explicitly captures temporal dependencies, providing a capability to forecast multiple, distinct future activities. Our adversarial grammar is designed so that it can learn stochastic production rules from the data distribution, jointly with its latent non-terminal representations. Being able to select multiple production rules during inference leads to different predicted outcomes, thus efficiently modeling many plausible futures. The adversarial generative grammar is evaluated on the Charades, MultiTHUMOS, Human3.6M, and 50 Salads datasets and on two activity prediction tasks: future 3D human pose prediction and future activity prediction. The proposed adversarial grammar outperforms the state-of-the-art approaches, being able to predict much more accurately and further in the future, than prior work.
AttentionNAS: Spatiotemporal Attention Cell Search for Video Classification
Jul 31, 2020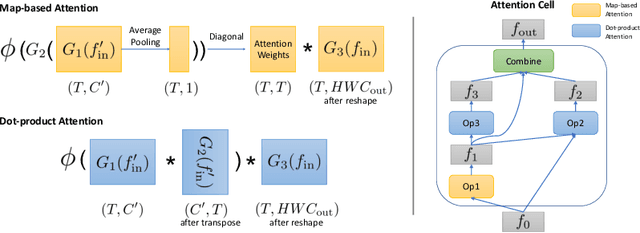
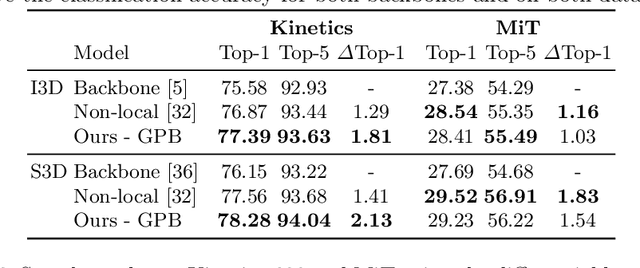
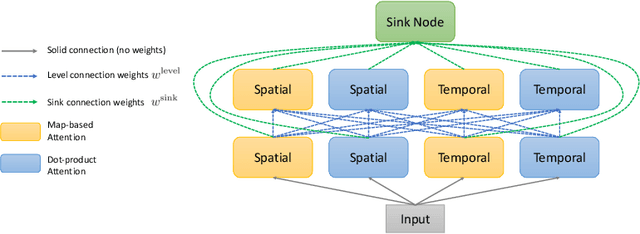
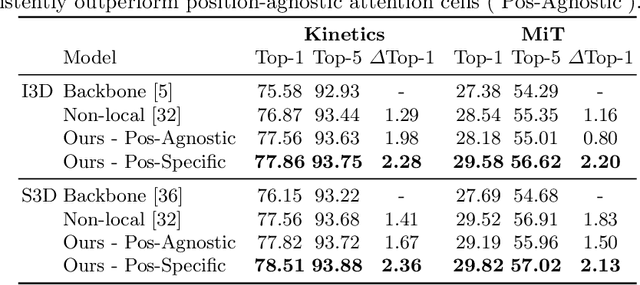
Convolutional operations have two limitations: (1) do not explicitly model where to focus as the same filter is applied to all the positions, and (2) are unsuitable for modeling long-range dependencies as they only operate on a small neighborhood. While both limitations can be alleviated by attention operations, many design choices remain to be determined to use attention, especially when applying attention to videos. Towards a principled way of applying attention to videos, we address the task of spatiotemporal attention cell search. We propose a novel search space for spatiotemporal attention cells, which allows the search algorithm to flexibly explore various design choices in the cell. The discovered attention cells can be seamlessly inserted into existing backbone networks, e.g., I3D or S3D, and improve video classification accuracy by more than 2% on both Kinetics-600 and MiT datasets. The discovered attention cells outperform non-local blocks on both datasets, and demonstrate strong generalization across different modalities, backbones, and datasets. Inserting our attention cells into I3D-R50 yields state-of-the-art performance on both datasets.
Mask2CAD: 3D Shape Prediction by Learning to Segment and Retrieve
Jul 26, 2020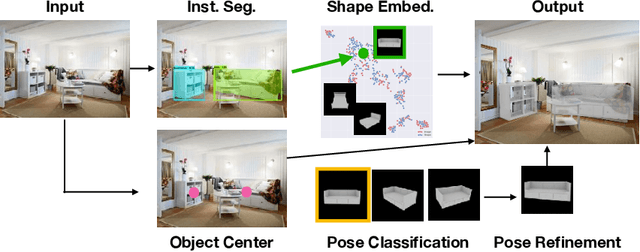
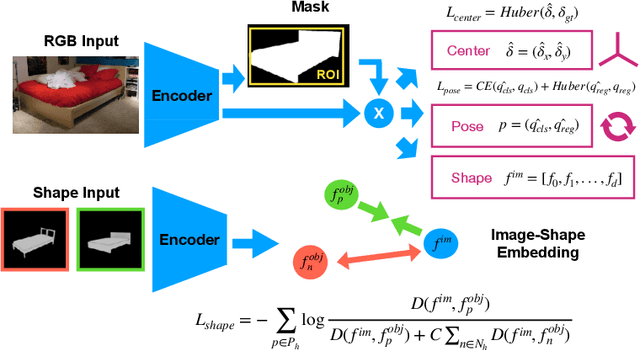
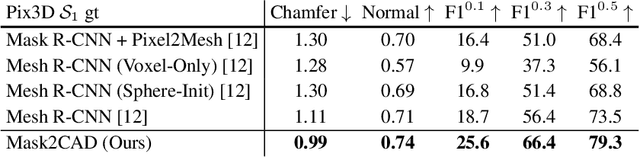
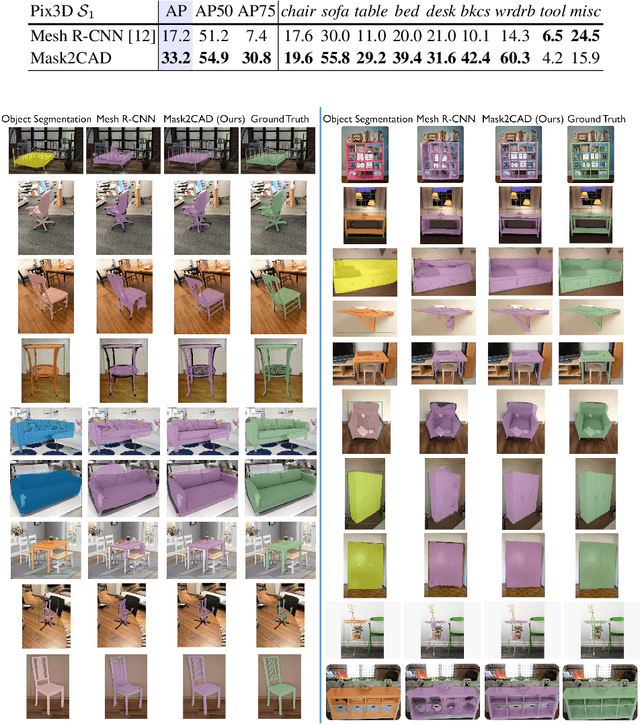
Object recognition has seen significant progress in the image domain, with focus primarily on 2D perception. We propose to leverage existing large-scale datasets of 3D models to understand the underlying 3D structure of objects seen in an image by constructing a CAD-based representation of the objects and their poses. We present Mask2CAD, which jointly detects objects in real-world images and for each detected object, optimizes for the most similar CAD model and its pose. We construct a joint embedding space between the detected regions of an image corresponding to an object and 3D CAD models, enabling retrieval of CAD models for an input RGB image. This produces a clean, lightweight representation of the objects in an image; this CAD-based representation ensures a valid, efficient shape representation for applications such as content creation or interactive scenarios, and makes a step towards understanding the transformation of real-world imagery to a synthetic domain. Experiments on real-world images from Pix3D demonstrate the advantage of our approach in comparison to state of the art. To facilitate future research, we additionally propose a new image-to-3D baseline on ScanNet which features larger shape diversity, real-world occlusions, and challenging image views.
What Matters in Unsupervised Optical Flow
Jun 08, 2020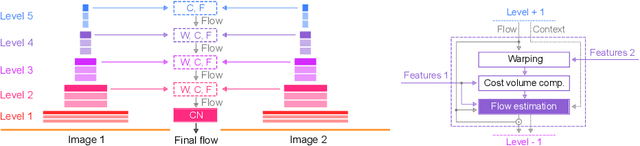
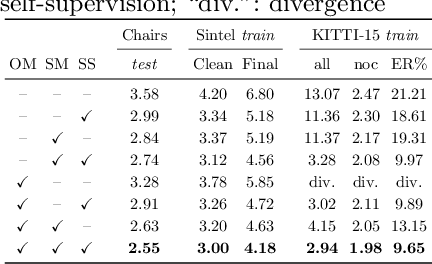

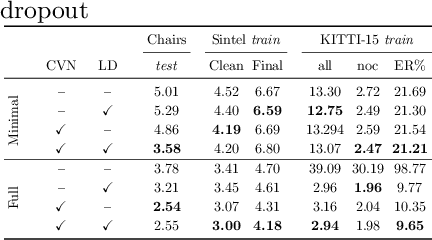
We systematically compare and analyze a set of key components in unsupervised optical flow to identify which photometric loss, occlusion handling, and smoothness regularization is most effective. Alongside this investigation we construct a number of novel improvements to unsupervised flow models, such as cost volume normalization, stopping the gradient at the occlusion mask, encouraging smoothness before upsampling the flow field, and continual self-supervision with image resizing. By combining the results of our investigation with our improved model components, we are able to present a new unsupervised flow technique that significantly outperforms the previous unsupervised state-of-the-art and performs on par with supervised FlowNet2 on the KITTI 2015 dataset, while also being significantly simpler than related approaches.
Differentiable Mapping Networks: Learning Structured Map Representations for Sparse Visual Localization
May 19, 2020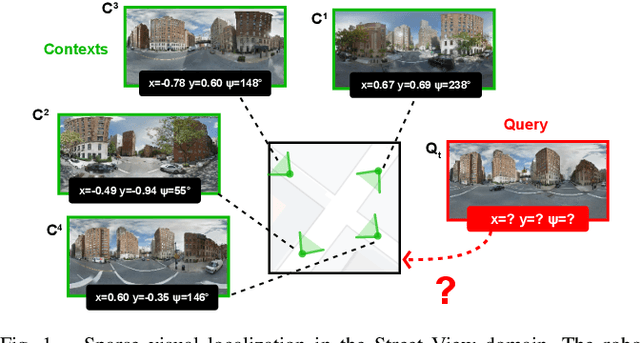
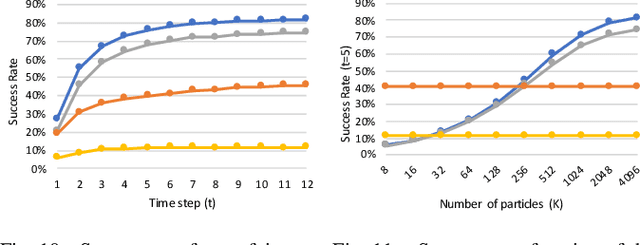
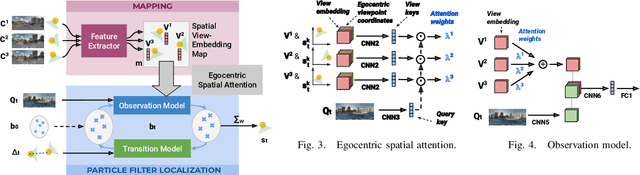
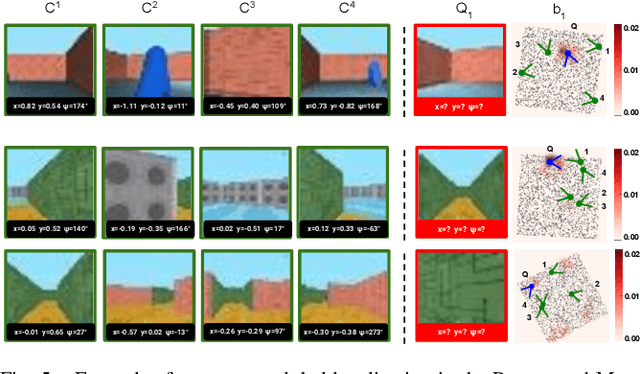
Mapping and localization, preferably from a small number of observations, are fundamental tasks in robotics. We address these tasks by combining spatial structure (differentiable mapping) and end-to-end learning in a novel neural network architecture: the Differentiable Mapping Network (DMN). The DMN constructs a spatially structured view-embedding map and uses it for subsequent visual localization with a particle filter. Since the DMN architecture is end-to-end differentiable, we can jointly learn the map representation and localization using gradient descent. We apply the DMN to sparse visual localization, where a robot needs to localize in a new environment with respect to a small number of images from known viewpoints. We evaluate the DMN using simulated environments and a challenging real-world Street View dataset. We find that the DMN learns effective map representations for visual localization. The benefit of spatial structure increases with larger environments, more viewpoints for mapping, and when training data is scarce. Project website: http://sites.google.com/view/differentiable-mapping
Taskology: Utilizing Task Relations at Scale
May 14, 2020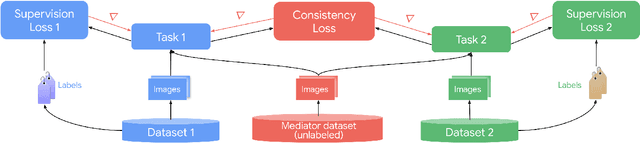
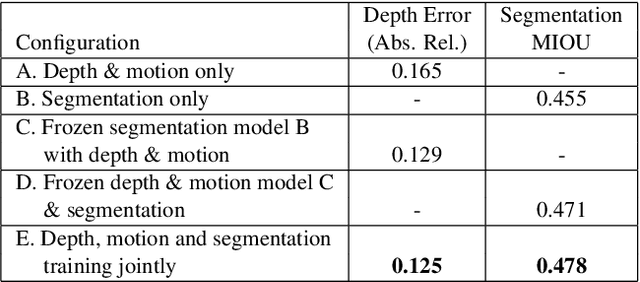
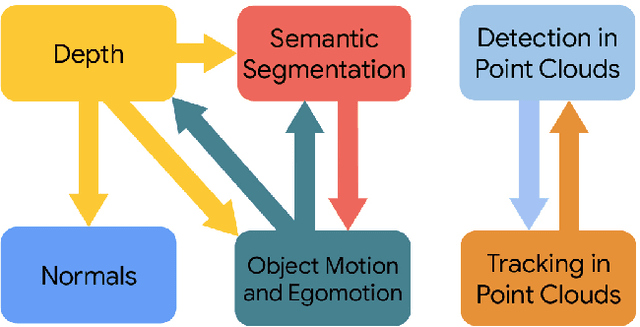
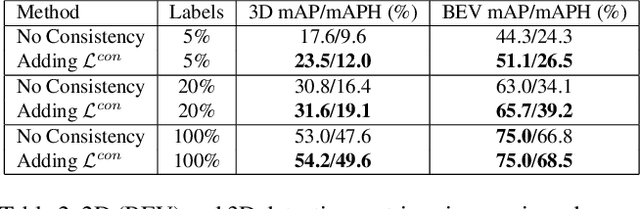
It has been recognized that the joint training of computer vision tasks with shared network components enables higher performance for each individual task. Training tasks together allows learning the inherent relationships among them; however, this requires large sets of labeled data. Instead, we argue that utilizing the known relationships between tasks explicitly allows improving their performance with less labeled data. To this end, we aim to establish and explore a novel approach for the collective training of computer vision tasks. In particular, we focus on utilizing the inherent relations of tasks by employing consistency constraints derived from physics, geometry, and logic. We show that collections of models can be trained without shared components, interacting only through the consistency constraints as supervision (peer-supervision). The consistency constraints enforce the structural priors between tasks, which enables their mutually consistent training, and -- in turn -- leads to overall higher performance. Treating individual tasks as modules, agnostic to their implementation, reduces the engineering overhead to collectively train many tasks to a minimum. Furthermore, the collective training can be distributed among multiple compute nodes, which further facilitates training at scale. We demonstrate our framework on subsets of the following collection of tasks: depth and normal prediction, semantic segmentation, 3D motion estimation, and object tracking and detection in point clouds.