 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData augmentation for efficient learning from parametric experts
May 23, 2022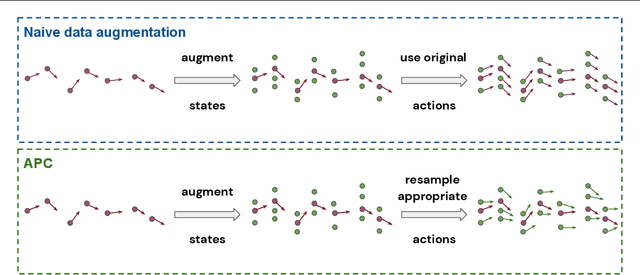
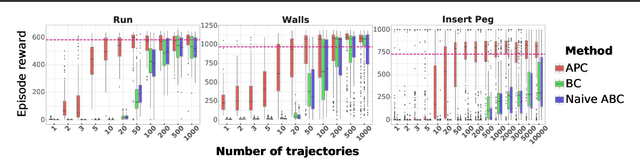
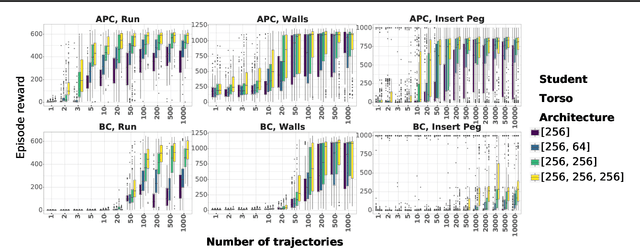
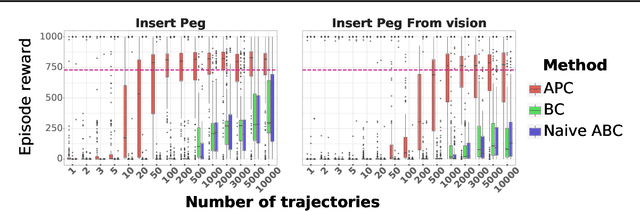
We present a simple, yet powerful data-augmentation technique to enable data-efficient learning from parametric experts for reinforcement and imitation learning. We focus on what we call the policy cloning setting, in which we use online or offline queries of an expert or expert policy to inform the behavior of a student policy. This setting arises naturally in a number of problems, for instance as variants of behavior cloning, or as a component of other algorithms such as DAGGER, policy distillation or KL-regularized RL. Our approach, augmented policy cloning (APC), uses synthetic states to induce feedback-sensitivity in a region around sampled trajectories, thus dramatically reducing the environment interactions required for successful cloning of the expert. We achieve highly data-efficient transfer of behavior from an expert to a student policy for high-degrees-of-freedom control problems. We demonstrate the benefit of our method in the context of several existing and widely used algorithms that include policy cloning as a constituent part. Moreover, we highlight the benefits of our approach in two practically relevant settings (a) expert compression, i.e. transfer to a student with fewer parameters; and (b) transfer from privileged experts, i.e. where the expert has a different observation space than the student, usually including access to privileged information.
Game Plan: What AI can do for Football, and What Football can do for AI
Nov 18, 2020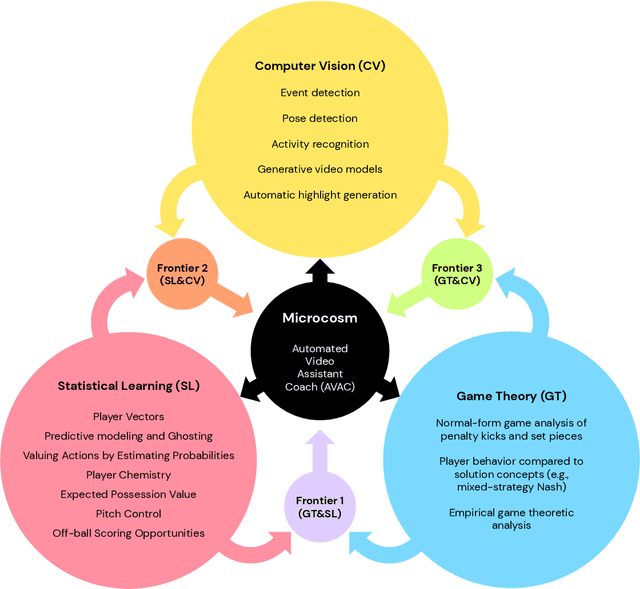



The rapid progress in artificial intelligence (AI) and machine learning has opened unprecedented analytics possibilities in various team and individual sports, including baseball, basketball, and tennis. More recently, AI techniques have been applied to football, due to a huge increase in data collection by professional teams, increased computational power, and advances in machine learning, with the goal of better addressing new scientific challenges involved in the analysis of both individual players' and coordinated teams' behaviors. The research challenges associated with predictive and prescriptive football analytics require new developments and progress at the intersection of statistical learning, game theory, and computer vision. In this paper, we provide an overarching perspective highlighting how the combination of these fields, in particular, forms a unique microcosm for AI research, while offering mutual benefits for professional teams, spectators, and broadcasters in the years to come. We illustrate that this duality makes football analytics a game changer of tremendous value, in terms of not only changing the game of football itself, but also in terms of what this domain can mean for the field of AI. We review the state-of-the-art and exemplify the types of analysis enabled by combining the aforementioned fields, including illustrative examples of counterfactual analysis using predictive models, and the combination of game-theoretic analysis of penalty kicks with statistical learning of player attributes. We conclude by highlighting envisioned downstream impacts, including possibilities for extensions to other sports (real and virtual).
Behavior Priors for Efficient Reinforcement Learning
Oct 27, 2020
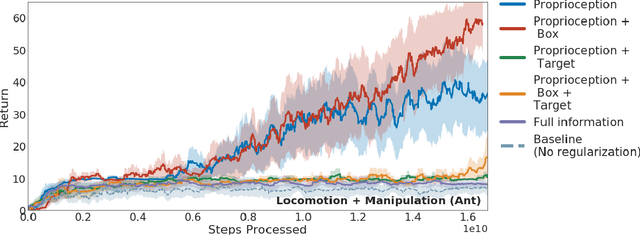

As we deploy reinforcement learning agents to solve increasingly challenging problems, methods that allow us to inject prior knowledge about the structure of the world and effective solution strategies becomes increasingly important. In this work we consider how information and architectural constraints can be combined with ideas from the probabilistic modeling literature to learn behavior priors that capture the common movement and interaction patterns that are shared across a set of related tasks or contexts. For example the day-to day behavior of humans comprises distinctive locomotion and manipulation patterns that recur across many different situations and goals. We discuss how such behavior patterns can be captured using probabilistic trajectory models and how these can be integrated effectively into reinforcement learning schemes, e.g.\ to facilitate multi-task and transfer learning. We then extend these ideas to latent variable models and consider a formulation to learn hierarchical priors that capture different aspects of the behavior in reusable modules. We discuss how such latent variable formulations connect to related work on hierarchical reinforcement learning (HRL) and mutual information and curiosity based objectives, thereby offering an alternative perspective on existing ideas. We demonstrate the effectiveness of our framework by applying it to a range of simulated continuous control domains.
Learning Dexterous Manipulation from Suboptimal Experts
Oct 16, 2020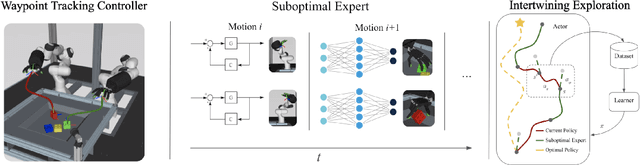
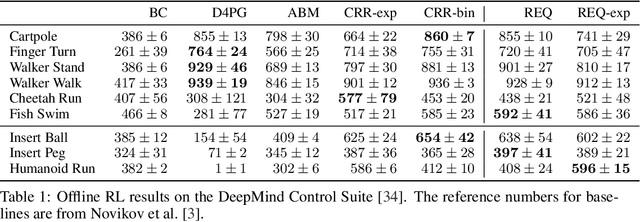

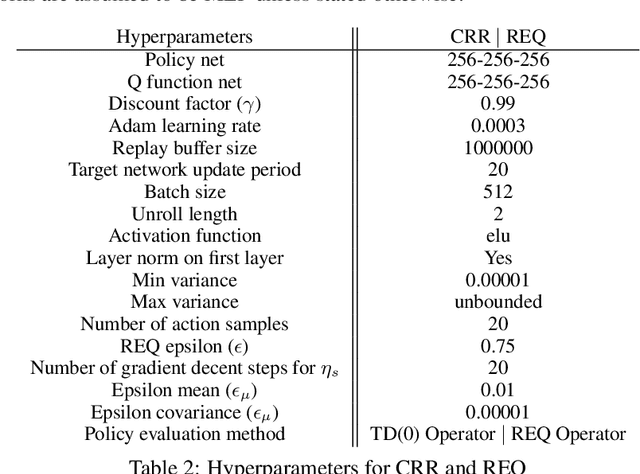
Learning dexterous manipulation in high-dimensional state-action spaces is an important open challenge with exploration presenting a major bottleneck. Although in many cases the learning process could be guided by demonstrations or other suboptimal experts, current RL algorithms for continuous action spaces often fail to effectively utilize combinations of highly off-policy expert data and on-policy exploration data. As a solution, we introduce Relative Entropy Q-Learning (REQ), a simple policy iteration algorithm that combines ideas from successful offline and conventional RL algorithms. It represents the optimal policy via importance sampling from a learned prior and is well-suited to take advantage of mixed data distributions. We demonstrate experimentally that REQ outperforms several strong baselines on robotic manipulation tasks for which suboptimal experts are available. We show how suboptimal experts can be constructed effectively by composing simple waypoint tracking controllers, and we also show how learned primitives can be combined with waypoint controllers to obtain reference behaviors to bootstrap a complex manipulation task on a simulated bimanual robot with human-like hands. Finally, we show that REQ is also effective for general off-policy RL, offline RL, and RL from demonstrations. Videos and further materials are available at sites.google.com/view/rlfse.
Temporal Difference Uncertainties as a Signal for Exploration
Oct 05, 2020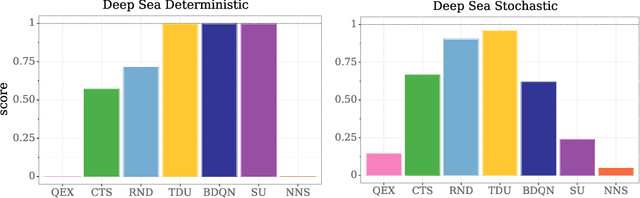
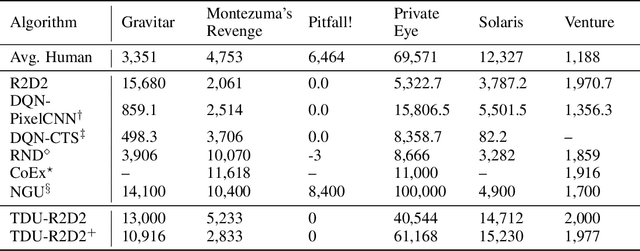
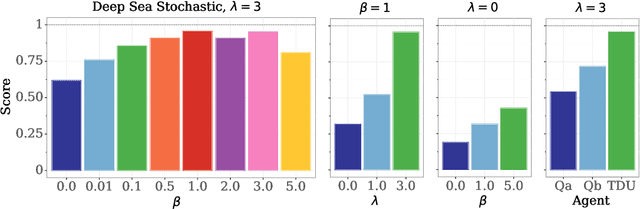

An effective approach to exploration in reinforcement learning is to rely on an agent's uncertainty over the optimal policy, which can yield near-optimal exploration strategies in tabular settings. However, in non-tabular settings that involve function approximators, obtaining accurate uncertainty estimates is almost as challenging a problem. In this paper, we highlight that value estimates are easily biased and temporally inconsistent. In light of this, we propose a novel method for estimating uncertainty over the value function that relies on inducing a distribution over temporal difference errors. This exploration signal controls for state-action transitions so as to isolate uncertainty in value that is due to uncertainty over the agent's parameters. Because our measure of uncertainty conditions on state-action transitions, we cannot act on this measure directly. Instead, we incorporate it as an intrinsic reward and treat exploration as a separate learning problem, induced by the agent's temporal difference uncertainties. We introduce a distinct exploration policy that learns to collect data with high estimated uncertainty, which gives rise to a curriculum that smoothly changes throughout learning and vanishes in the limit of perfect value estimates. We evaluate our method on hard exploration tasks, including Deep Sea and Atari 2600 environments and find that our proposed form of exploration facilitates both diverse and deep exploration.
Information Theoretic Meta Learning with Gaussian Processes
Oct 05, 2020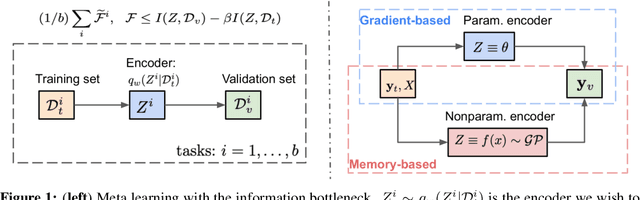
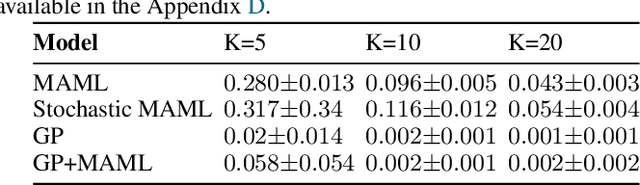
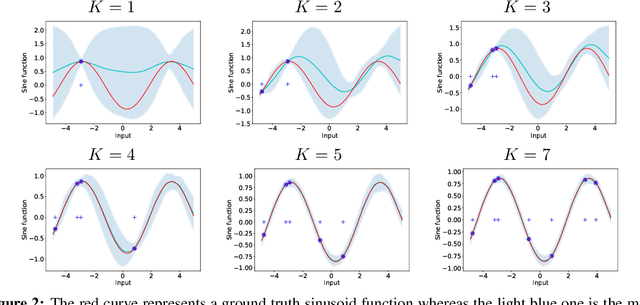
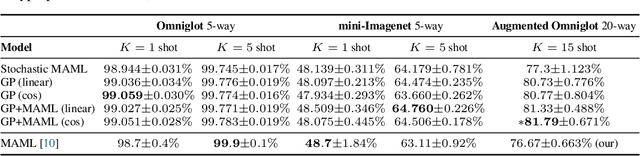
We formulate meta learning using information theoretic concepts such as mutual information and the information bottleneck. The idea is to learn a stochastic representation or encoding of the task description, given by a training or support set, that is highly informative about predicting the validation set. By making use of variational approximations to the mutual information, we derive a general and tractable framework for meta learning. We particularly develop new memory-based meta learning algorithms based on Gaussian processes and derive extensions that combine memory and gradient-based meta learning. We demonstrate our method on few-shot regression and classification by using standard benchmarks such as Omniglot, mini-Imagenet and Augmented Omniglot.
Importance Weighted Policy Learning and Adaption
Sep 10, 2020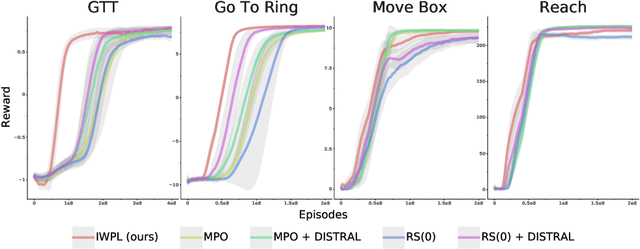
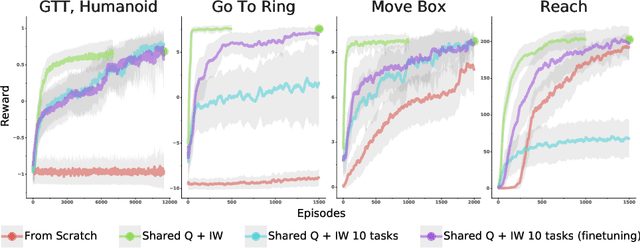

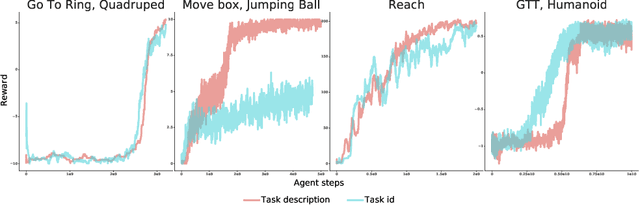
The ability to exploit prior experience to solve novel problems rapidly is a hallmark of biological learning systems and of great practical importance for artificial ones. In the meta reinforcement learning literature much recent work has focused on the problem of optimizing the learning process itself. In this paper we study a complementary approach which is conceptually simple, general, modular and built on top of recent improvements in off-policy learning. The framework is inspired by ideas from the probabilistic inference literature and combines robust off-policy learning with a behavior prior, or default behavior that constrains the space of solutions and serves as a bias for exploration; as well as a representation for the value function, both of which are easily learned from a number of training tasks in a multi-task scenario. Our approach achieves competitive adaptation performance on hold-out tasks compared to meta reinforcement learning baselines and can scale to complex sparse-reward scenarios.
Task Agnostic Continual Learning via Meta Learning
Jun 12, 2019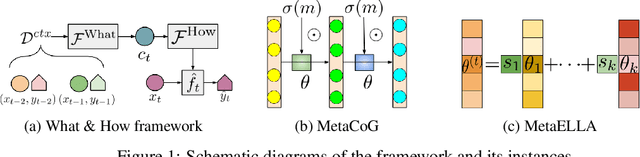

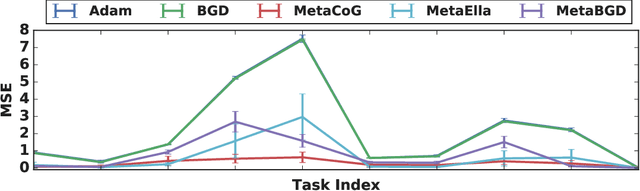
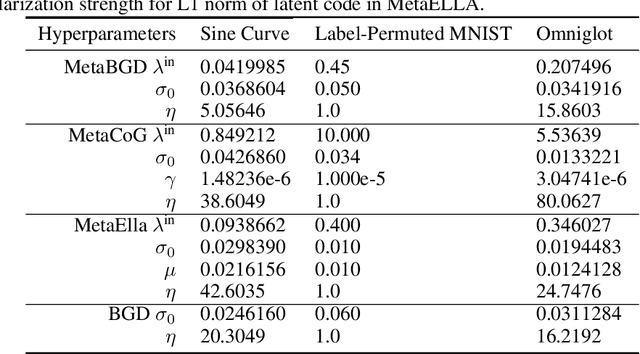
While neural networks are powerful function approximators, they suffer from catastrophic forgetting when the data distribution is not stationary. One particular formalism that studies learning under non-stationary distribution is provided by continual learning, where the non-stationarity is imposed by a sequence of distinct tasks. Most methods in this space assume, however, the knowledge of task boundaries, and focus on alleviating catastrophic forgetting. In this work, we depart from this view and move the focus towards faster remembering -- i.e measuring how quickly the network recovers performance rather than measuring the network's performance without any adaptation. We argue that in many settings this can be more effective and that it opens the door to combining meta-learning and continual learning techniques, leveraging their complementary advantages. We propose a framework specific for the scenario where no information about task boundaries or task identity is given. It relies on a separation of concerns into what task is being solved and how the task should be solved. This framework is implemented by differentiating task specific parameters from task agnostic parameters, where the latter are optimized in a continual meta learning fashion, without access to multiple tasks at the same time. We showcase this framework in a supervised learning scenario and discuss the implication of the proposed formalism.
Meta reinforcement learning as task inference
May 15, 2019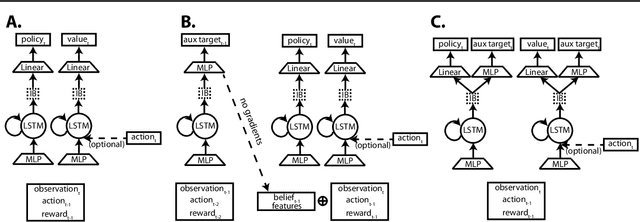
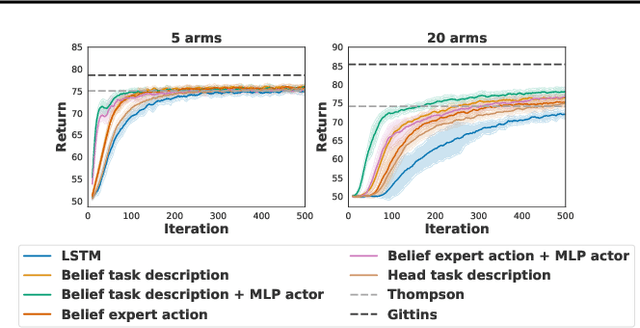
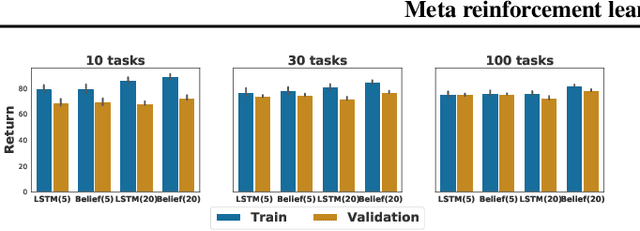

Humans achieve efficient learning by relying on prior knowledge about the structure of naturally occurring tasks. There has been considerable interest in designing reinforcement learning algorithms with similar properties. This includes several proposals to learn the learning algorithm itself, an idea also referred to as meta learning. One formal interpretation of this idea is in terms of a partially observable multi-task reinforcement learning problem in which information about the task is hidden from the agent. Although agents that solve partially observable environments can be trained from rewards alone, shaping an agent's memory with additional supervision has been shown to boost learning efficiency. It is thus natural to ask what kind of supervision, if any, facilitates meta-learning. Here we explore several choices and develop an architecture that separates learning of the belief about the unknown task from learning of the policy, and that can be used effectively with privileged information about the task during training. We show that this approach can be very effective at solving standard meta-RL environments, as well as a complex continuous control environment in which a simulated robot has to execute various movement sequences.
Information asymmetry in KL-regularized RL
May 03, 2019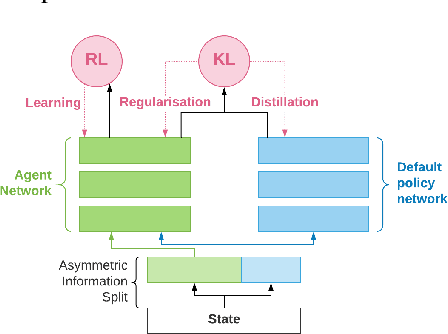

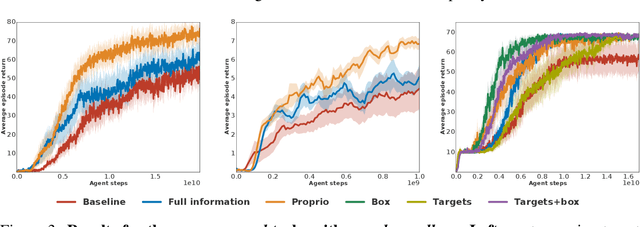
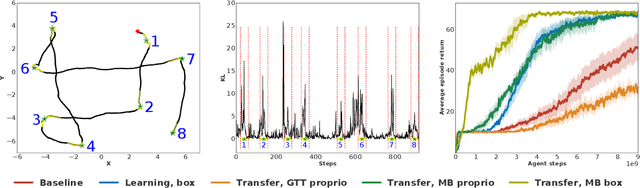
Many real world tasks exhibit rich structure that is repeated across different parts of the state space or in time. In this work we study the possibility of leveraging such repeated structure to speed up and regularize learning. We start from the KL regularized expected reward objective which introduces an additional component, a default policy. Instead of relying on a fixed default policy, we learn it from data. But crucially, we restrict the amount of information the default policy receives, forcing it to learn reusable behaviors that help the policy learn faster. We formalize this strategy and discuss connections to information bottleneck approaches and to the variational EM algorithm. We present empirical results in both discrete and continuous action domains and demonstrate that, for certain tasks, learning a default policy alongside the policy can significantly speed up and improve learning.